Vector Quantization for Recommender Systems: A Review and Outlook

0
Sign in to get full access
Overview
- Vector Quantization (VQ): A technique that compresses high-dimensional data by mapping it to a smaller set of representative vectors, known as a "codebook".
- Recommender Systems: Systems that suggest products, services, or content to users based on their preferences and behaviors.
- Applying VQ to Recommender Systems: VQ can help improve the efficiency and performance of recommender systems by reducing the dimensionality of user and item representations.
Plain English Explanation
Vector Quantization (VQ) is a way of compressing and simplifying complex data. Imagine you have a huge spreadsheet with millions of numbers - VQ can take all that information and boil it down to a smaller set of representative numbers, kind of like a "cheat sheet" for the data.
Recommender systems are the algorithms that power the personalized suggestions you see on websites and apps, like "Products you might like" or "Videos you might enjoy." These systems need to process a lot of information about users and items to make good recommendations.
By applying VQ to recommender systems, researchers have found a way to condense all that data into a more compact form. This makes the recommender system more efficient, allowing it to work faster and with less computing power. It's kind of like taking a big box of puzzle pieces and organizing them into a smaller set of buckets - now the system can quickly find the right pieces (recommendations) without having to dig through the whole box.
The key benefit is that VQ can help recommender systems provide better suggestions without requiring as much data storage or processing power. This could lead to faster, more responsive recommendation engines, especially on devices with limited resources like phones and tablets.
Technical Explanation
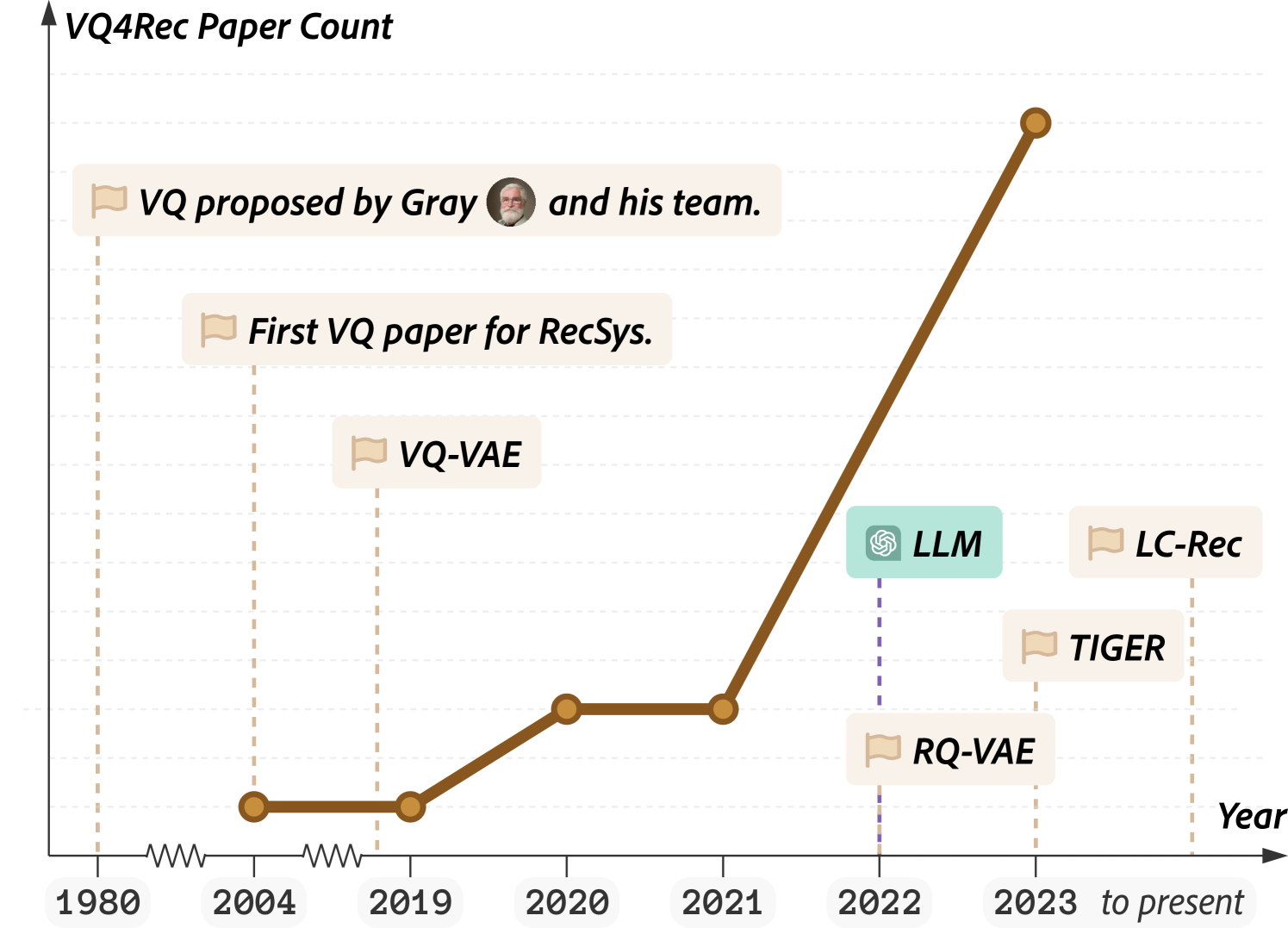
Vector Quantization (VQ) is a technique for compressing high-dimensional data by mapping it to a smaller set of representative vectors, known as a "codebook." VQ for Recommender Systems explores how VQ can be applied to improve the efficiency and performance of recommender systems.
Recommender systems typically need to process and store large amounts of user and item data to generate personalized suggestions. By using VQ to compress this data, recommender systems can reduce the memory and computational requirements, leading to faster and more scalable performance.
The paper discusses various VQ techniques, such as K-means clustering and self-organizing maps, and how they can be adapted for recommender systems. It also covers recent advancements, such as long-range VQ models and quantization approaches for large language models, and their potential impact on recommender systems.
Critical Analysis
The paper provides a comprehensive overview of VQ techniques and their application to recommender systems. However, it also acknowledges some key limitations and areas for further research:
- Adaptive Codebook Generation: The paper suggests that developing more adaptive and dynamic codebook generation methods could further improve the performance of VQ-based recommender systems.
- Multimodal Integration: Incorporating VQ techniques into multimodal recommender systems, which leverage diverse data sources like text, images, and audio, could be a promising direction for future research.
- Interpretability and Explainability: While VQ can improve the efficiency of recommender systems, the paper notes that the compressed representations may reduce the interpretability of the underlying recommendations. Addressing this challenge could enhance user trust and acceptance of VQ-powered recommender systems.
Overall, the paper provides a solid foundation for understanding the potential of VQ in recommender systems, while also highlighting areas where further innovation and research could lead to even more impactful applications.
Conclusion
This paper presents a comprehensive review of using Vector Quantization (VQ) techniques to improve the efficiency and performance of recommender systems. By compressing user and item data into a smaller set of representative vectors, VQ can help reduce the memory and computational requirements of recommender systems, leading to faster and more scalable performance.
The paper covers a range of VQ techniques and their adaptations for recommender systems, as well as recent advancements in long-range VQ models and quantization approaches for large language models. While VQ-based recommender systems show promising results, the paper also identifies areas for further research, such as developing more adaptive codebook generation methods and addressing interpretability challenges.
Overall, this review highlights the significant potential of VQ to enhance the effectiveness and accessibility of recommender systems, particularly in resource-constrained environments like mobile devices. As the field continues to evolve, these VQ techniques could play an increasingly important role in shaping the future of personalized recommendation experiences.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Vector Quantization for Recommender Systems: A Review and Outlook
Qijiong Liu, Xiaoyu Dong, Jiaren Xiao, Nuo Chen, Hengchang Hu, Jieming Zhu, Chenxu Zhu, Tetsuya Sakai, Xiao-Ming Wu
Vector quantization, renowned for its unparalleled feature compression capabilities, has been a prominent topic in signal processing and machine learning research for several decades and remains widely utilized today. With the emergence of large models and generative AI, vector quantization has gained popularity in recommender systems, establishing itself as a preferred solution. This paper starts with a comprehensive review of vector quantization techniques. It then explores systematic taxonomies of vector quantization methods for recommender systems (VQ4Rec), examining their applications from multiple perspectives. Further, it provides a thorough introduction to research efforts in diverse recommendation scenarios, including efficiency-oriented approaches and quality-oriented approaches. Finally, the survey analyzes the remaining challenges and anticipates future trends in VQ4Rec, including the challenges associated with the training of vector quantization, the opportunities presented by large language models, and emerging trends in multimodal recommender systems. We hope this survey can pave the way for future researchers in the recommendation community and accelerate their exploration in this promising field.
Read more5/7/2024
0
Accurate Compression of Text-to-Image Diffusion Models via Vector Quantization
Vage Egiazarian, Denis Kuznedelev, Anton Voronov, Ruslan Svirschevski, Michael Goin, Daniil Pavlov, Dan Alistarh, Dmitry Baranchuk
Text-to-image diffusion models have emerged as a powerful framework for high-quality image generation given textual prompts. Their success has driven the rapid development of production-grade diffusion models that consistently increase in size and already contain billions of parameters. As a result, state-of-the-art text-to-image models are becoming less accessible in practice, especially in resource-limited environments. Post-training quantization (PTQ) tackles this issue by compressing the pretrained model weights into lower-bit representations. Recent diffusion quantization techniques primarily rely on uniform scalar quantization, providing decent performance for the models compressed to 4 bits. This work demonstrates that more versatile vector quantization (VQ) may achieve higher compression rates for large-scale text-to-image diffusion models. Specifically, we tailor vector-based PTQ methods to recent billion-scale text-to-image models (SDXL and SDXL-Turbo), and show that the diffusion models of 2B+ parameters compressed to around 3 bits using VQ exhibit the similar image quality and textual alignment as previous 4-bit compression techniques.
Read more9/4/2024
0
New!Practical and Asymptotically Optimal Quantization of High-Dimensional Vectors in Euclidean Space for Approximate Nearest Neighbor Search
Jianyang Gao, Yutong Gou, Yuexuan Xu, Yongyi Yang, Cheng Long, Raymond Chi-Wing Wong
Approximate nearest neighbor (ANN) query in high-dimensional Euclidean space is a key operator in database systems. For this query, quantization is a popular family of methods developed for compressing vectors and reducing memory consumption. Recently, a method called RaBitQ achieves the state-of-the-art performance among these methods. It produces better empirical performance in both accuracy and efficiency when using the same compression rate and provides rigorous theoretical guarantees. However, the method is only designed for compressing vectors at high compression rates (32x) and lacks support for achieving higher accuracy by using more space. In this paper, we introduce a new quantization method to address this limitation by extending RaBitQ. The new method inherits the theoretical guarantees of RaBitQ and achieves the asymptotic optimality in terms of the trade-off between space and error bounds as to be proven in this study. Additionally, we present efficient implementations of the method, enabling its application to ANN queries to reduce both space and time consumption. Extensive experiments on real-world datasets confirm that our method consistently outperforms the state-of-the-art baselines in both accuracy and efficiency when using the same amount of memory.
Read more9/17/2024
🧠
0
Residual Quantization with Implicit Neural Codebooks
Iris A. M. Huijben, Matthijs Douze, Matthew Muckley, Ruud J. G. van Sloun, Jakob Verbeek
Vector quantization is a fundamental operation for data compression and vector search. To obtain high accuracy, multi-codebook methods represent each vector using codewords across several codebooks. Residual quantization (RQ) is one such method, which iteratively quantizes the error of the previous step. While the error distribution is dependent on previously-selected codewords, this dependency is not accounted for in conventional RQ as it uses a fixed codebook per quantization step. In this paper, we propose QINCo, a neural RQ variant that constructs specialized codebooks per step that depend on the approximation of the vector from previous steps. Experiments show that QINCo outperforms state-of-the-art methods by a large margin on several datasets and code sizes. For example, QINCo achieves better nearest-neighbor search accuracy using 12-byte codes than the state-of-the-art UNQ using 16 bytes on the BigANN1M and Deep1M datasets.
Read more5/22/2024