Vector-Symbolic Architecture for Event-Based Optical Flow

0
⚙️
Sign in to get full access
Overview
- This research paper introduces a novel feature descriptor for event-based optical flow estimation using Vector Symbolic Architectures (VSA).
- The proposed VSA-based feature descriptor is able to effectively capture the topological similarity between neighboring events, leading to enhanced representation for feature matching across event frames.
- The paper presents two methods for event-based optical flow estimation: a model-based approach (VSA-Flow) and a self-supervised learning approach (VSA-SM).
- Evaluation on benchmark datasets shows the VSA-based methods outperform existing model-based and self-supervised learning approaches for event-based optical flow.
Plain English Explanation
Event cameras are a type of sensor that capture changes in the visual scene, rather than recording full images like traditional cameras. This makes them well-suited for applications that require fast, low-power, and high-dynamic-range visual processing, such as autonomous driving and robotics.
One key task for event cameras is optical flow estimation, which involves tracking the movement of features in the visual scene. This paper introduces a new way to describe and match features in event camera data using a mathematical framework called Vector Symbolic Architectures (VSA).
The VSA-based feature descriptor is able to capture the spatial relationships between neighboring events, which helps with accurately matching features across different event frames. This is important for estimating optical flow, as it allows the system to track how features are moving over time.
The paper presents two methods that use this VSA-based feature descriptor for event-based optical flow estimation:
- VSA-Flow: a model-based approach that directly uses the feature descriptors to estimate optical flow.
- VSA-SM: a self-supervised learning approach that learns to estimate optical flow directly from the event data, without needing additional information like grayscale images.
The researchers evaluated these methods on standard benchmarks for event-based optical flow and found that they outperformed existing techniques, both model-based and self-supervised. This represents an important advance in the field, as it shows how the VSA framework can be leveraged to create more robust and accurate event-based computer vision systems.
Technical Explanation
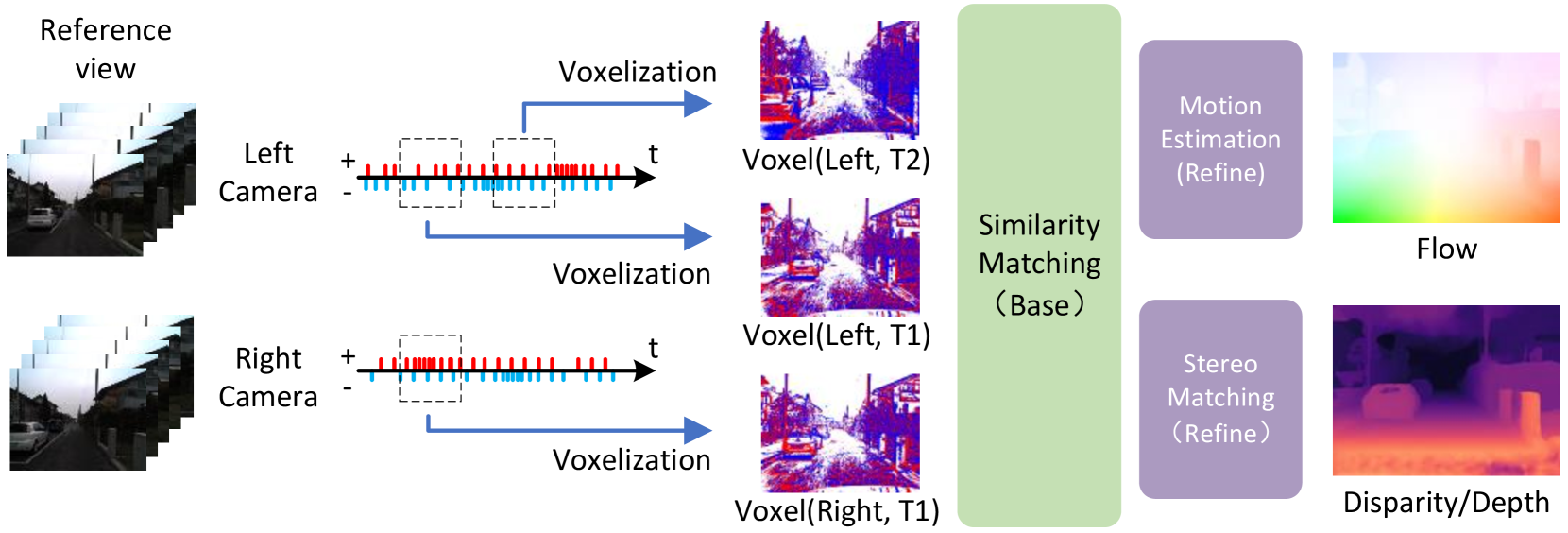
The core innovation in this paper is the development of a high-dimensional (HD) feature descriptor for event frames using Vector Symbolic Architectures (VSA). VSA is a mathematical framework that allows for the representation of complex data structures, such as the spatial relationships between events, in a structured symbolic form.
The key insight is that the topological similarity between neighboring events within the VSA representation contributes to enhanced representation similarity of feature descriptors for points that should be matched across event frames for optical flow estimation. Additionally, the structured symbolic nature of VSA facilitates the fusion of features from both event polarities (on/off) and multiple spatial scales.
Based on this HD feature descriptor, the authors propose two methods for event-based optical flow estimation:
-
VSA-Flow: This is a model-based approach that directly uses the VSA-based feature descriptors to match features and estimate optical flow. The authors demonstrate that the effectiveness of the HD feature descriptors leads to accurate optical flow estimation.
-
VSA-SM: This is a self-supervised learning approach, where a novel similarity maximization method based on the HD feature descriptor is used to learn optical flow directly from the event data, without requiring any additional information like grayscale images.
The paper evaluates these VSA-based methods on two standard benchmarks for event-based optical flow: the DSEC and MVSEC datasets. The results show that the VSA-based methods outperform both model-based and self-supervised learning approaches on the DSEC benchmark, while remaining competitive on the MVSEC benchmark.
Critical Analysis
The main strength of this research is the novel application of Vector Symbolic Architectures to the problem of event-based optical flow estimation. The VSA-based feature descriptor appears to be a powerful tool for capturing the spatial relationships between events, which is crucial for accurate feature matching and flow estimation.
However, the paper does not provide a detailed analysis of the computational complexity or runtime performance of the proposed methods. As event-based systems are often deployed on resource-constrained embedded platforms, the efficiency of the algorithms is an important consideration that is not fully addressed.
Additionally, the paper only evaluates the methods on two benchmark datasets, which may not fully represent the diversity of real-world scenarios where event cameras are deployed. Further testing on a wider range of datasets, including more challenging environments and sensor configurations, would help to validate the broader applicability of the VSA-based approach.
It would also be interesting to see how the VSA-based methods compare to other recent advances in event-based optical flow, such as the lightweight approach or the video-to-events simulator that could potentially be used to generate larger and more diverse training datasets.
Conclusion
This research paper presents a significant advance in the field of event-based optical flow estimation by introducing a novel feature descriptor based on Vector Symbolic Architectures. The VSA-based approach effectively captures the spatial relationships between events, leading to enhanced feature matching and improved accuracy in both model-based and self-supervised learning methods.
The results on benchmark datasets demonstrate the potential of this VSA-based framework to become a valuable tool for event-based computer vision, with applications in areas like autonomous navigation and video object tracking. Further research is needed to fully explore the efficiency and real-world performance of these methods, but this work marks an important step forward in the development of robust and accurate event-based vision systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
⚙️
0
Vector-Symbolic Architecture for Event-Based Optical Flow
Hongzhi You, Yijun Cao, Wei Yuan, Fanjun Wang, Ning Qiao, Yongjie Li
From a perspective of feature matching, optical flow estimation for event cameras involves identifying event correspondences by comparing feature similarity across accompanying event frames. In this work, we introduces an effective and robust high-dimensional (HD) feature descriptor for event frames, utilizing Vector Symbolic Architectures (VSA). The topological similarity among neighboring variables within VSA contributes to the enhanced representation similarity of feature descriptors for flow-matching points, while its structured symbolic representation capacity facilitates feature fusion from both event polarities and multiple spatial scales. Based on this HD feature descriptor, we propose a novel feature matching framework for event-based optical flow, encompassing both model-based (VSA-Flow) and self-supervised learning (VSA-SM) methods. In VSA-Flow, accurate optical flow estimation validates the effectiveness of HD feature descriptors. In VSA-SM, a novel similarity maximization method based on the HD feature descriptor is proposed to learn optical flow in a self-supervised way from events alone, eliminating the need for auxiliary grayscale images. Evaluation results demonstrate that our VSA-based method achieves superior accuracy in comparison to both model-based and self-supervised learning methods on the DSEC benchmark, while remains competitive among both methods on the MVSEC benchmark. This contribution marks a significant advancement in event-based optical flow within the feature matching methodology.
Read more5/16/2024
0
Unifying Event-based Flow, Stereo and Depth Estimation via Feature Similarity Matching
Pengjie Zhang, Lin Zhu, Lizhi Wang, Hua Huang
As an emerging vision sensor, the event camera has gained popularity in various vision tasks such as optical flow estimation, stereo matching, and depth estimation due to its high-speed, sparse, and asynchronous event streams. Unlike traditional approaches that use specialized architectures for each specific task, we propose a unified framework, EventMatch, that reformulates these tasks as an event-based dense correspondence matching problem, allowing them to be solved with a single model by directly comparing feature similarities. By utilizing a shared feature similarities module, which integrates knowledge from other event flows via temporal or spatial interactions, and distinct task heads, our network can concurrently perform optical flow estimation from temporal inputs (e.g., two segments of event streams in the temporal domain) and stereo matching from spatial inputs (e.g., two segments of event streams from different viewpoints in the spatial domain). Moreover, we further demonstrate that our unified model inherently supports cross-task transfer since the architecture and parameters are shared across tasks. Without the need for retraining on each task, our model can effectively handle both optical flow and disparity estimation simultaneously. The experiment conducted on the DSEC benchmark demonstrates that our model exhibits superior performance in both optical flow and disparity estimation tasks, outperforming existing state-of-the-art methods. Our unified approach not only advances event-based models but also opens new possibilities for cross-task transfer and inter-task fusion in both spatial and temporal dimensions. Our code will be available later.
Read more8/1/2024

0
Temporal Event Stereo via Joint Learning with Stereoscopic Flow
Hoonhee Cho, Jae-Young Kang, Kuk-Jin Yoon
Event cameras are dynamic vision sensors inspired by the biological retina, characterized by their high dynamic range, high temporal resolution, and low power consumption. These features make them capable of perceiving 3D environments even in extreme conditions. Event data is continuous across the time dimension, which allows a detailed description of each pixel's movements. To fully utilize the temporally dense and continuous nature of event cameras, we propose a novel temporal event stereo, a framework that continuously uses information from previous time steps. This is accomplished through the simultaneous training of an event stereo matching network alongside stereoscopic flow, a new concept that captures all pixel movements from stereo cameras. Since obtaining ground truth for optical flow during training is challenging, we propose a method that uses only disparity maps to train the stereoscopic flow. The performance of event-based stereo matching is enhanced by temporally aggregating information using the flows. We have achieved state-of-the-art performance on the MVSEC and the DSEC datasets. The method is computationally efficient, as it stacks previous information in a cascading manner. The code is available at https://github.com/mickeykang16/TemporalEventStereo.
Read more7/16/2024

0
SDformerFlow: Spatiotemporal swin spikeformer for event-based optical flow estimation
Yi Tian, Juan Andrade-Cetto
Event cameras generate asynchronous and sparse event streams capturing changes in light intensity. They offer significant advantages over conventional frame-based cameras, such as a higher dynamic range and an extremely faster data rate, making them particularly useful in scenarios involving fast motion or challenging lighting conditions. Spiking neural networks (SNNs) share similar asynchronous and sparse characteristics and are well-suited for processing data from event cameras. Inspired by the potential of transformers and spike-driven transformers (spikeformers) in other computer vision tasks, we propose two solutions for fast and robust optical flow estimation for event cameras: STTFlowNet and SDformerFlow. STTFlowNet adopts a U-shaped artificial neural network (ANN) architecture with spatiotemporal shifted window self-attention (swin) transformer encoders, while SDformerFlow presents its fully spiking counterpart, incorporating swin spikeformer encoders. Furthermore, we present two variants of the spiking version with different neuron models. Our work is the first to make use of spikeformers for dense optical flow estimation. We conduct end-to-end training for all models using supervised learning. Our results yield state-of-the-art performance among SNN-based event optical flow methods on both the DSEC and MVSEC datasets, and show significant reduction in power consumption compared to the equivalent ANNs.
Read more9/9/2024