VEGA: Learning Interleaved Image-Text Comprehension in Vision-Language Large Models
2406.10228
0
0

Abstract
The swift progress of Multi-modal Large Models (MLLMs) has showcased their impressive ability to tackle tasks blending vision and language. Yet, most current models and benchmarks cater to scenarios with a narrow scope of visual and textual contexts. These models often fall short when faced with complex comprehension tasks, which involve navigating through a plethora of irrelevant and potentially misleading information in both text and image forms. To bridge this gap, we introduce a new, more demanding task known as Interleaved Image-Text Comprehension (IITC). This task challenges models to discern and disregard superfluous elements in both images and text to accurately answer questions and to follow intricate instructions to pinpoint the relevant image. In support of this task, we further craft a new VEGA dataset, tailored for the IITC task on scientific content, and devised a subtask, Image-Text Association (ITA), to refine image-text correlation skills. Our evaluation of four leading closed-source models, as well as various open-source models using VEGA, underscores the rigorous nature of IITC. Even the most advanced models, such as Gemini-1.5-pro and GPT4V, only achieved modest success. By employing a multi-task, multi-scale post-training strategy, we have set a robust baseline for MLLMs on the IITC task, attaining an $85.8%$ accuracy rate in image association and a $0.508$ Rouge score. These results validate the effectiveness of our dataset in improving MLLMs capabilities for nuanced image-text comprehension.
Create account to get full access
Overview
- This paper introduces VEGA, a novel approach for learning interleaved image-text comprehension in vision-language large models.
- VEGA aims to enhance the understanding of text-heavy content by leveraging the complementary strengths of vision and language models.
- The key idea is to train vision-language models on an interleaved sequence of image and text inputs, allowing the models to learn the relationship between visual and linguistic information more effectively.
Plain English Explanation
VEGA is a new way to train large artificial intelligence (AI) models that can understand both images and text. These models are called "vision-language" models because they can work with both visual and textual information.
The main insight behind VEGA is that by training the models to process images and text in an interleaved fashion - switching back and forth between the two - the models can learn the connections between visual and linguistic information more deeply. This is important because many real-world applications, such as understanding social media posts or documents, require understanding both the images and the accompanying text.
By training the models to constantly toggle between images and text, VEGA helps them develop a stronger grasp of how visual and language information relate to and complement each other. This can lead to better performance on tasks that involve comprehending text-heavy content, where both visual and linguistic cues are crucial for full understanding.
Technical Explanation
The VEGA approach trains vision-language models on an interleaved sequence of image and text inputs. This is in contrast to the more common practice of training on image-text pairs [<a href="https://aimodels.fyi/papers/arxiv/vision-model-pre-training-interleaved-image-text">1</a>] or separately on images and text [<a href="https://aimodels.fyi/papers/arxiv/enhancing-vision-models-text-heavy-content-understanding">2</a>].
The interleaved training procedure encourages the model to learn how to effectively integrate visual and linguistic information, rather than processing them in isolation. This can lead to improved performance on tasks that require joint understanding of images and text, such as [<a href="https://aimodels.fyi/papers/arxiv/can-mllms-perform-text-to-image-context">3</a>] or [<a href="https://aimodels.fyi/papers/arxiv/seed-bench-2-plus-benchmarking-multimodal-large">4</a>].
The authors demonstrate the effectiveness of VEGA through extensive experiments on various vision-language benchmarks, showing consistent improvements over strong baselines that use non-interleaved training [<a href="https://aimodels.fyi/papers/arxiv/image-textualization-automatic-framework-creating-accurate-detailed">5</a>].
Critical Analysis
The VEGA paper presents a compelling approach for enhancing the joint understanding of images and text in large language models. However, the authors acknowledge that the benefits of interleaved training may be more pronounced for certain types of text-heavy content, and the optimal interleaving strategy may depend on the specific task or dataset.
Additionally, the paper does not explore the computational or memory efficiency tradeoffs of the interleaved training approach compared to other multi-modal training strategies. Further research is needed to understand the scalability and practical deployment considerations of VEGA.
Overall, the VEGA method represents an important step forward in developing more integrated vision-language models, but additional work is required to fully understand its strengths, limitations, and broader implications for the field of multimodal AI.
Conclusion
The VEGA approach introduces a novel training strategy for vision-language large models, where image and text inputs are processed in an interleaved fashion. This enables the models to learn more effective ways of integrating visual and linguistic information, leading to improved performance on tasks that require joint understanding of images and text.
The paper demonstrates the effectiveness of VEGA across various benchmarks, highlighting its potential to enhance the comprehension of text-heavy content. While further research is needed to fully understand the approach's limitations and practical considerations, VEGA represents an important advancement in the field of multimodal AI and its ability to tackle increasingly complex real-world challenges.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
❗
Can MLLMs Perform Text-to-Image In-Context Learning?
Yuchen Zeng, Wonjun Kang, Yicong Chen, Hyung Il Koo, Kangwook Lee
0
0
The evolution from Large Language Models (LLMs) to Multimodal Large Language Models (MLLMs) has spurred research into extending In-Context Learning (ICL) to its multimodal counterpart. Existing such studies have primarily concentrated on image-to-text ICL. However, the Text-to-Image ICL (T2I-ICL), with its unique characteristics and potential applications, remains underexplored. To address this gap, we formally define the task of T2I-ICL and present CoBSAT, the first T2I-ICL benchmark dataset, encompassing ten tasks. Utilizing our dataset to benchmark six state-of-the-art MLLMs, we uncover considerable difficulties MLLMs encounter in solving T2I-ICL. We identify the primary challenges as the inherent complexity of multimodality and image generation, and show that strategies such as fine-tuning and Chain-of-Thought prompting help to mitigate these difficulties, leading to notable improvements in performance. Our code and dataset are available at https://github.com/UW-Madison-Lee-Lab/CoBSAT.
4/17/2024
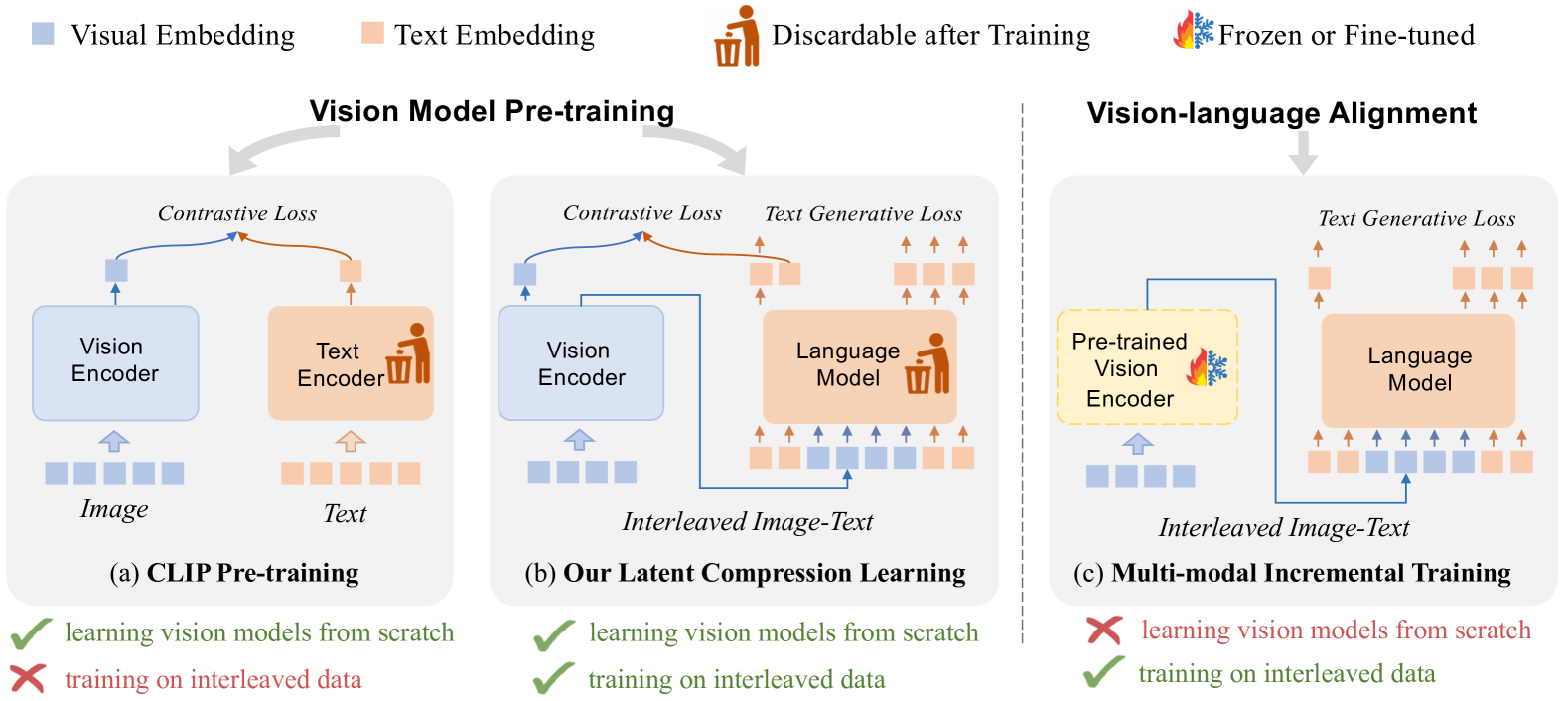
Vision Model Pre-training on Interleaved Image-Text Data via Latent Compression Learning
Chenyu Yang, Xizhou Zhu, Jinguo Zhu, Weijie Su, Junjie Wang, Xuan Dong, Wenhai Wang, Lewei Lu, Bin Li, Jie Zhou, Yu Qiao, Jifeng Dai
0
0
Recently, vision model pre-training has evolved from relying on manually annotated datasets to leveraging large-scale, web-crawled image-text data. Despite these advances, there is no pre-training method that effectively exploits the interleaved image-text data, which is very prevalent on the Internet. Inspired by the recent success of compression learning in natural language processing, we propose a novel vision model pre-training method called Latent Compression Learning (LCL) for interleaved image-text data. This method performs latent compression learning by maximizing the mutual information between the inputs and outputs of a causal attention model. The training objective can be decomposed into two basic tasks: 1) contrastive learning between visual representation and preceding context, and 2) generating subsequent text based on visual representation. Our experiments demonstrate that our method not only matches the performance of CLIP on paired pre-training datasets (e.g., LAION), but can also leverage interleaved pre-training data (e.g., MMC4) to learn robust visual representation from scratch, showcasing the potential of vision model pre-training with interleaved image-text data. Code is released at https://github.com/OpenGVLab/LCL.
6/12/2024

CoMM: A Coherent Interleaved Image-Text Dataset for Multimodal Understanding and Generation
Wei Chen, Lin Li, Yongqi Yang, Bin Wen, Fan Yang, Tingting Gao, Yu Wu, Long Chen
0
0
Interleaved image-text generation has emerged as a crucial multimodal task, aiming at creating sequences of interleaved visual and textual content given a query. Despite notable advancements in recent multimodal large language models (MLLMs), generating integrated image-text sequences that exhibit narrative coherence and entity and style consistency remains challenging due to poor training data quality. To address this gap, we introduce CoMM, a high-quality Coherent interleaved image-text MultiModal dataset designed to enhance the coherence, consistency, and alignment of generated multimodal content. Initially, CoMM harnesses raw data from diverse sources, focusing on instructional content and visual storytelling, establishing a foundation for coherent and consistent content. To further refine the data quality, we devise a multi-perspective filter strategy that leverages advanced pre-trained models to ensure the development of sentences, consistency of inserted images, and semantic alignment between them. Various quality evaluation metrics are designed to prove the high quality of the filtered dataset. Meanwhile, extensive few-shot experiments on various downstream tasks demonstrate CoMM's effectiveness in significantly enhancing the in-context learning capabilities of MLLMs. Moreover, we propose four new tasks to evaluate MLLMs' interleaved generation abilities, supported by a comprehensive evaluation framework. We believe CoMM opens a new avenue for advanced MLLMs with superior multimodal in-context learning and understanding ability.
6/18/2024
👀
Enhancing Vision Models for Text-Heavy Content Understanding and Interaction
Adithya TG, Adithya SK, Abhinav R Bharadwaj, Abhiram HA, Dr. Surabhi Narayan
0
0
Interacting and understanding with text heavy visual content with multiple images is a major challenge for traditional vision models. This paper is on enhancing vision models' capability to comprehend or understand and learn from images containing a huge amount of textual information from the likes of textbooks and research papers which contain multiple images like graphs, etc and tables in them with different types of axes and scales. The approach involves dataset preprocessing, fine tuning which is by using instructional oriented data and evaluation. We also built a visual chat application integrating CLIP for image encoding and a model from the Massive Text Embedding Benchmark which is developed to consider both textual and visual inputs. An accuracy of 96.71% was obtained. The aim of the project is to increase and also enhance the advance vision models' capabilities in understanding complex visual textual data interconnected data, contributing to multimodal AI.
6/3/2024