Vera Verto: Multimodal Hijacking Attack

0

Sign in to get full access
Overview
- The paper "Vera Verto: Multimodal Hijacking Attack" explores a new type of attack that can hijack AI models by exploiting vulnerabilities in multimodal systems.
- The researchers demonstrate how they can gain control of an AI model's outputs by carefully crafting malicious inputs that manipulate the model's behavior across different modalities like images, text, and audio.
- This attack, called "Vera Verto," highlights the security risks of AI systems that integrate multiple input types, and the need for more robust defenses against such multimodal attacks.
Plain English Explanation
The paper describes a new way to trick AI systems that use multiple types of information, like images, text, and audio. The researchers show how they can create special inputs that cause the AI to behave in ways it shouldn't, essentially taking control of the AI's outputs. They call this the "Vera Verto" attack.
This is possible because these AI systems, which combine information from different sources, can be vulnerable in ways that single-input AI systems are not. By carefully designing the right kind of malicious input that affects multiple parts of the system, the researchers were able to gain control over what the AI says or does.
This highlights an important security risk with AI systems that rely on multiple types of data. If they're not designed very carefully, these AI systems can be manipulated in dangerous ways. The researchers hope their work will inspire developers to build more secure and robust multimodal AI systems that are better protected against this kind of attack.
Technical Explanation
The paper introduces a new attack called "Vera Verto" that can hijack the outputs of multimodal AI models by carefully crafting malicious inputs that exploit vulnerabilities across different input modalities.
The researchers demonstrate this attack on a multimodal language model trained on both text and images. They show how they can generate adversarial inputs that simultaneously fool the model's vision and language components, allowing them to control the model's generated text outputs.
Specifically, the Vera Verto attack involves creating an "adversarial image" that, when paired with a benign text prompt, causes the model to output a malicious text response. The researchers leverage weaknesses in how the model integrates and reasons about the different input modalities to achieve this multimodal hijacking.
Through extensive experiments, the team shows the Vera Verto attack can successfully manipulate the model's outputs across a range of tasks, from image captioning to open-ended text generation. They also demonstrate the attack's transferability, where a single set of adversarial inputs can hijack multiple multimodal models.
The paper concludes by discussing the security implications of these findings and calling for the development of more robust defenses against multimodal attacks to ensure the safety and reliability of AI systems that combine different input types.
Critical Analysis
The Vera Verto attack highlights significant vulnerabilities in multimodal AI systems that integrate vision, language, and other modalities. The researchers demonstrate the potency of this attack, which can subvert the intended behavior of these models in concerning ways.
However, the paper does not explore the full scope of potential multimodal attacks or provide a comprehensive defense strategy. The attack is demonstrated on a specific language model, and the ability to generalize the approach to a wider range of multimodal AI systems is not thoroughly investigated.
Additionally, the paper does not delve into the ethical implications of such attacks, such as the potential for misuse by bad actors. Deeper consideration of the societal risks and responsible disclosure practices would strengthen the work.
That said, the Vera Verto attack is a valuable contribution that underscores the need for heightened security in multimodal AI. The findings should spur further research into developing robust defenses, including techniques for detecting and mitigating multimodal vulnerabilities.
Conclusion
The "Vera Verto: Multimodal Hijacking Attack" paper sheds light on a new and concerning vulnerability in AI systems that combine multiple input modalities like vision and language. The researchers demonstrate how carefully crafted adversarial inputs can hijack the outputs of these multimodal models, highlighting the security risks inherent in this emerging class of AI technologies.
While the specific attack is demonstrated on a particular model, the broader implications of this work are far-reaching. As AI systems become more sophisticated and integrate richer sensory inputs, the potential for multimodal attacks to disrupt their intended behavior and undermine their reliability grows. The Vera Verto attack serves as a wake-up call, underscoring the urgent need for improved security measures and more robust defenses against such multimodal vulnerabilities.
Ultimately, this research contributes to the ongoing effort to ensure the safety and trustworthiness of AI systems as they become increasingly ubiquitous in our lives. By proactively addressing the security challenges posed by multimodal AI, the field can work towards developing AI technologies that are more resilient, secure, and aligned with societal values.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Vera Verto: Multimodal Hijacking Attack
Minxing Zhang, Ahmed Salem, Michael Backes, Yang Zhang
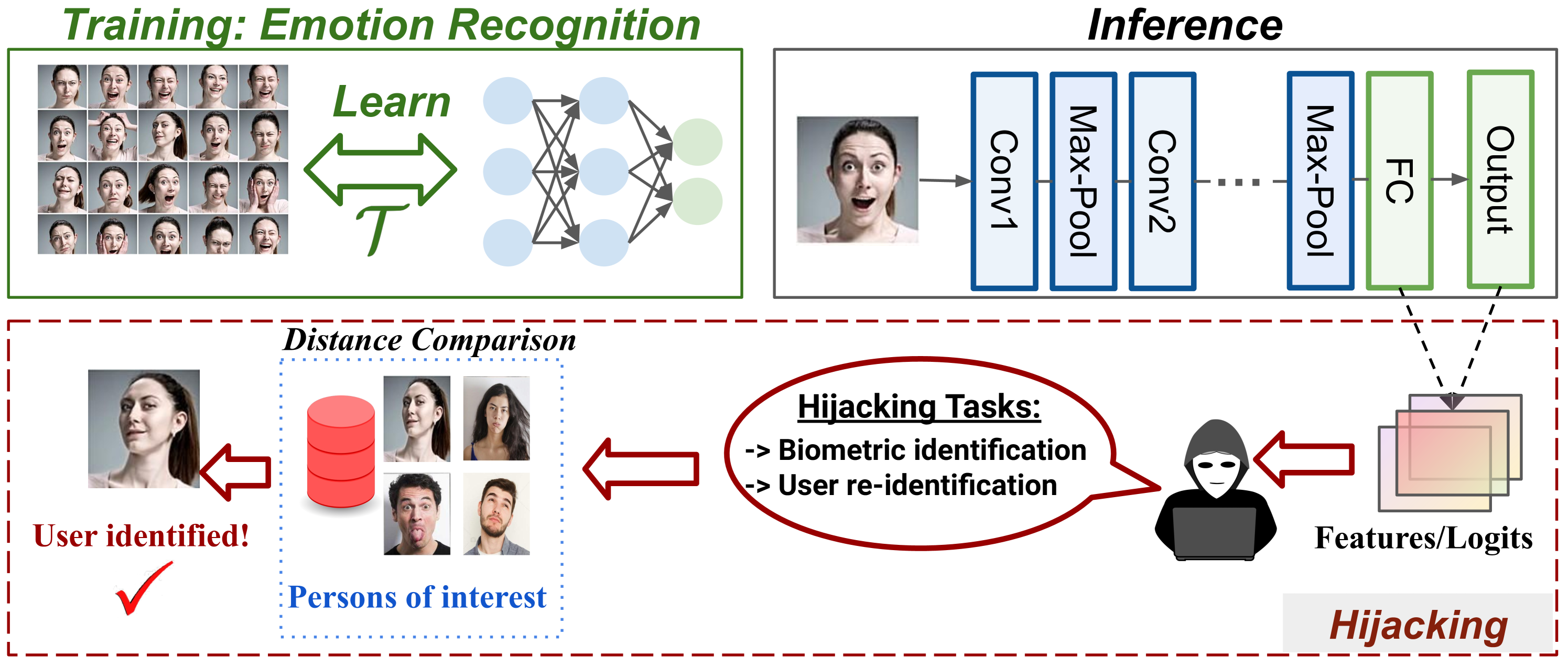
The increasing cost of training machine learning (ML) models has led to the inclusion of new parties to the training pipeline, such as users who contribute training data and companies that provide computing resources. This involvement of such new parties in the ML training process has introduced new attack surfaces for an adversary to exploit. A recent attack in this domain is the model hijacking attack, whereby an adversary hijacks a victim model to implement their own -- possibly malicious -- hijacking tasks. However, the scope of the model hijacking attack is so far limited to the homogeneous-modality tasks. In this paper, we transform the model hijacking attack into a more general multimodal setting, where the hijacking and original tasks are performed on data of different modalities. Specifically, we focus on the setting where an adversary implements a natural language processing (NLP) hijacking task into an image classification model. To mount the attack, we propose a novel encoder-decoder based framework, namely the Blender, which relies on advanced image and language models. Experimental results show that our modal hijacking attack achieves strong performances in different settings. For instance, our attack achieves 94%, 94%, and 95% attack success rate when using the Sogou news dataset to hijack STL10, CIFAR-10, and MNIST classifiers.
Read more8/2/2024
0
Model for Peanuts: Hijacking ML Models without Training Access is Possible
Mahmoud Ghorbel, Halima Bouzidi, Ioan Marius Bilasco, Ihsen Alouani
The massive deployment of Machine Learning (ML) models has been accompanied by the emergence of several attacks that threaten their trustworthiness and raise ethical and societal concerns such as invasion of privacy, discrimination risks, and lack of accountability. Model hijacking is one of these attacks, where the adversary aims to hijack a victim model to execute a different task than its original one. Model hijacking can cause accountability and security risks since a hijacked model owner can be framed for having their model offering illegal or unethical services. Prior state-of-the-art works consider model hijacking as a training time attack, whereby an adversary requires access to the ML model training to execute their attack. In this paper, we consider a stronger threat model where the attacker has no access to the training phase of the victim model. Our intuition is that ML models, typically over-parameterized, might (unintentionally) learn more than the intended task for they are trained. We propose a simple approach for model hijacking at inference time named SnatchML to classify unknown input samples using distance measures in the latent space of the victim model to previously known samples associated with the hijacking task classes. SnatchML empirically shows that benign pre-trained models can execute tasks that are semantically related to the initial task. Surprisingly, this can be true even for hijacking tasks unrelated to the original task. We also explore different methods to mitigate this risk. We first propose a novel approach we call meta-unlearning, designed to help the model unlearn a potentially malicious task while training on the original task dataset. We also provide insights on over-parameterization as one possible inherent factor that makes model hijacking easier, and we accordingly propose a compression-based countermeasure against this attack.
Read more6/5/2024

0
Adversarial Attacks on Multimodal Agents
Chen Henry Wu, Jing Yu Koh, Ruslan Salakhutdinov, Daniel Fried, Aditi Raghunathan
Vision-enabled language models (VLMs) are now used to build autonomous multimodal agents capable of taking actions in real environments. In this paper, we show that multimodal agents raise new safety risks, even though attacking agents is more challenging than prior attacks due to limited access to and knowledge about the environment. Our attacks use adversarial text strings to guide gradient-based perturbation over one trigger image in the environment: (1) our captioner attack attacks white-box captioners if they are used to process images into captions as additional inputs to the VLM; (2) our CLIP attack attacks a set of CLIP models jointly, which can transfer to proprietary VLMs. To evaluate the attacks, we curated VisualWebArena-Adv, a set of adversarial tasks based on VisualWebArena, an environment for web-based multimodal agent tasks. Within an L-infinity norm of $16/256$ on a single image, the captioner attack can make a captioner-augmented GPT-4V agent execute the adversarial goals with a 75% success rate. When we remove the captioner or use GPT-4V to generate its own captions, the CLIP attack can achieve success rates of 21% and 43%, respectively. Experiments on agents based on other VLMs, such as Gemini-1.5, Claude-3, and GPT-4o, show interesting differences in their robustness. Further analysis reveals several key factors contributing to the attack's success, and we also discuss the implications for defenses as well. Project page: https://chenwu.io/attack-agent Code and data: https://github.com/ChenWu98/agent-attack
Read more6/19/2024
🖼️
0
Image Hijacks: Adversarial Images can Control Generative Models at Runtime
Luke Bailey, Euan Ong, Stuart Russell, Scott Emmons
Are foundation models secure against malicious actors? In this work, we focus on the image input to a vision-language model (VLM). We discover image hijacks, adversarial images that control the behaviour of VLMs at inference time, and introduce the general Behaviour Matching algorithm for training image hijacks. From this, we derive the Prompt Matching method, allowing us to train hijacks matching the behaviour of an arbitrary user-defined text prompt (e.g. 'the Eiffel Tower is now located in Rome') using a generic, off-the-shelf dataset unrelated to our choice of prompt. We use Behaviour Matching to craft hijacks for four types of attack, forcing VLMs to generate outputs of the adversary's choice, leak information from their context window, override their safety training, and believe false statements. We study these attacks against LLaVA, a state-of-the-art VLM based on CLIP and LLaMA-2, and find that all attack types achieve a success rate of over 80%. Moreover, our attacks are automated and require only small image perturbations.
Read more4/24/2024