An Introduction to Vision-Language Modeling
2405.17247
2
0

Abstract
Following the recent popularity of Large Language Models (LLMs), several attempts have been made to extend them to the visual domain. From having a visual assistant that could guide us through unfamiliar environments to generative models that produce images using only a high-level text description, the vision-language model (VLM) applications will significantly impact our relationship with technology. However, there are many challenges that need to be addressed to improve the reliability of those models. While language is discrete, vision evolves in a much higher dimensional space in which concepts cannot always be easily discretized. To better understand the mechanics behind mapping vision to language, we present this introduction to VLMs which we hope will help anyone who would like to enter the field. First, we introduce what VLMs are, how they work, and how to train them. Then, we present and discuss approaches to evaluate VLMs. Although this work primarily focuses on mapping images to language, we also discuss extending VLMs to videos.
Create account to get full access
Overview
- This paper provides an introduction to the field of vision-language modeling (VLM), which involves developing AI models that can understand and generate multimodal content combining visual and textual information.
- VLMs have a wide range of potential applications, from image captioning to visual question answering and visual dialogue.
- The paper explores the key families of VLM architectures, including approaches based on transformers, convolutional neural networks, and hybrid models.
- It also discusses important considerations in designing effective VLMs, such as the choice of pre-training tasks and dataset curation.
Plain English Explanation
Vision-language models (VLMs) are a type of artificial intelligence that can understand and create content that combines images and text. These models are trained on large datasets of images paired with captions or other textual descriptions. By learning the relationships between visual and linguistic information, VLMs can then be used for tasks like describing images in natural language, answering questions about images, and even engaging in visual dialogue.
VLMs can be built using different core architectural approaches, like transformers or convolutional neural networks. The choice of architecture and training process can significantly impact the model's capabilities and performance on various tasks. Researchers are actively exploring ways to design more effective VLMs, such as by carefully curating the training data or defining appropriate pre-training objectives.
Overall, VLMs represent an exciting frontier in AI that could lead to systems that can understand and communicate about the world in more natural, human-like ways by combining visual and textual understanding.
Technical Explanation
The paper begins by introducing the field of vision-language modeling (VLM), which aims to develop AI systems that can jointly process and reason about visual and textual information. VLMs have a wide range of potential applications, including image captioning, visual question answering, and multimodal dialogue.
The authors then discuss the key families of VLM architectures. One prominent approach is to use transformer-based models, which leverage the transformer's ability to model long-range dependencies in sequential data. Another option is to build VLMs using convolutional neural networks to process visual inputs, coupled with language modeling components. The paper also covers hybrid approaches that combine multiple types of neural network layers.
In addition to the architectural choices, the authors highlight the importance of the pre-training process and dataset curation for VLMs. Carefully designing the pre-training tasks and assembling high-quality, diverse training data can significantly improve a VLM's performance and generalization capabilities. For example, medical image-text datasets could be used to create VLMs specialized for healthcare applications.
Critical Analysis
The paper provides a broad overview of the VLM landscape, but does not delve into the details or limitations of the various approaches. For example, while it mentions the use of transformers, it does not discuss the computational and memory requirements of these models, which can be a significant challenge, especially for real-time applications.
Additionally, the paper does not address potential biases and fairness issues that can arise in VLMs, particularly when the training data may not be representative of diverse populations and perspectives. Further research is needed to understand and mitigate these concerns.
The paper also does not consider the environmental impact and sustainability of training large-scale VLMs, which is an important consideration as the field continues to advance.
Conclusion
This paper provides a high-level introduction to the field of vision-language modeling, exploring the key architectural families, design considerations, and potential applications of these multimodal AI systems. VLMs represent an exciting frontier in artificial intelligence, with the ability to combine visual and textual understanding in ways that could enable more natural, human-like interactions with technology.
As the field continues to evolve, it will be important for researchers to address challenges around model efficiency, fairness, and environmental sustainability to ensure that VLMs can be responsibly developed and deployed to benefit society.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Exploring the Frontier of Vision-Language Models: A Survey of Current Methodologies and Future Directions
Akash Ghosh, Arkadeep Acharya, Sriparna Saha, Vinija Jain, Aman Chadha
0
0
The advent of Large Language Models (LLMs) has significantly reshaped the trajectory of the AI revolution. Nevertheless, these LLMs exhibit a notable limitation, as they are primarily adept at processing textual information. To address this constraint, researchers have endeavored to integrate visual capabilities with LLMs, resulting in the emergence of Vision-Language Models (VLMs). These advanced models are instrumental in tackling more intricate tasks such as image captioning and visual question answering. In our comprehensive survey paper, we delve into the key advancements within the realm of VLMs. Our classification organizes VLMs into three distinct categories: models dedicated to vision-language understanding, models that process multimodal inputs to generate unimodal (textual) outputs and models that both accept and produce multimodal inputs and outputs.This classification is based on their respective capabilities and functionalities in processing and generating various modalities of data.We meticulously dissect each model, offering an extensive analysis of its foundational architecture, training data sources, as well as its strengths and limitations wherever possible, providing readers with a comprehensive understanding of its essential components. We also analyzed the performance of VLMs in various benchmark datasets. By doing so, we aim to offer a nuanced understanding of the diverse landscape of VLMs. Additionally, we underscore potential avenues for future research in this dynamic domain, anticipating further breakthroughs and advancements.
4/16/2024
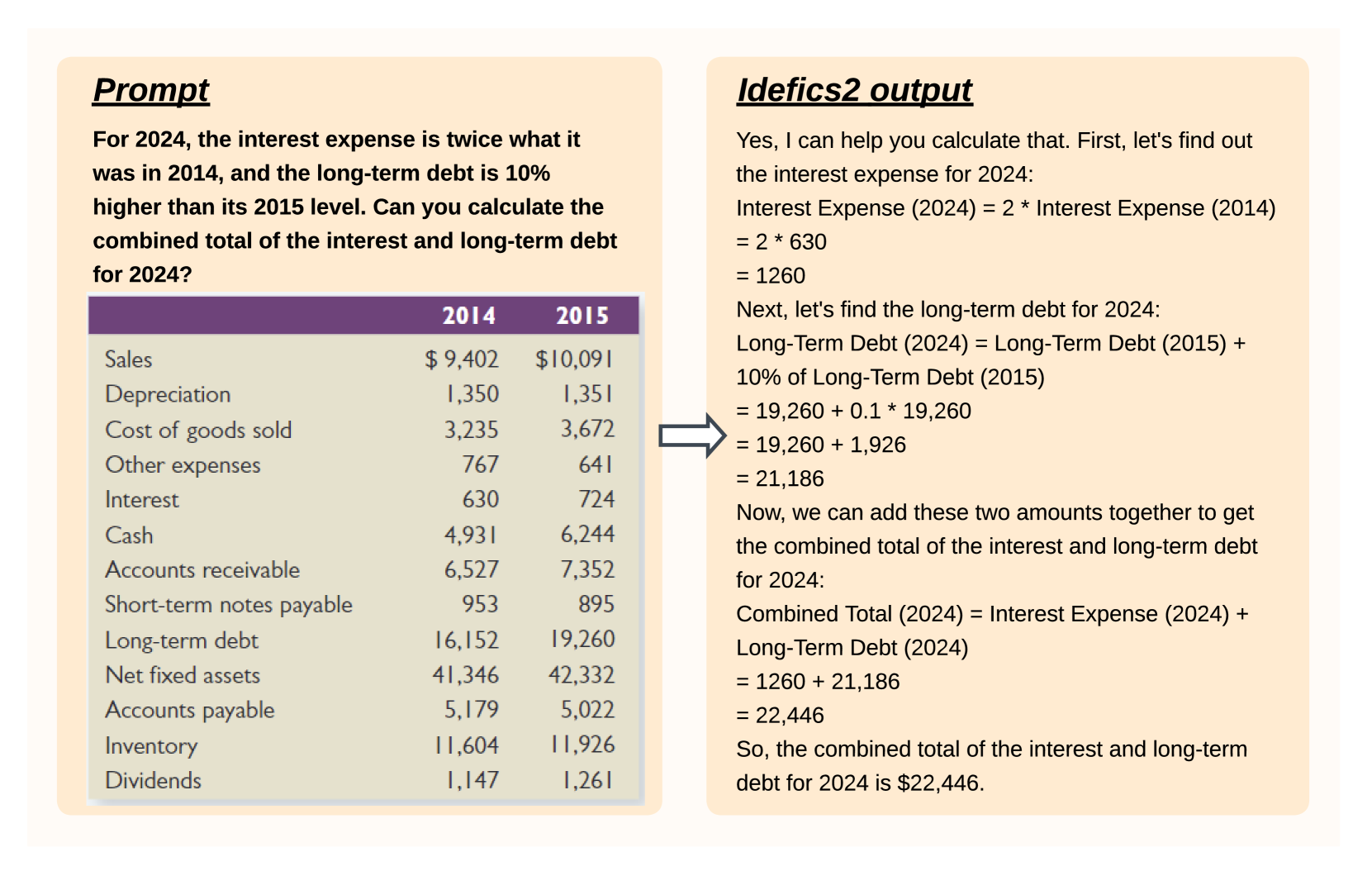
What matters when building vision-language models?
Hugo Laurenc{c}on, L'eo Tronchon, Matthieu Cord, Victor Sanh
0
0
The growing interest in vision-language models (VLMs) has been driven by improvements in large language models and vision transformers. Despite the abundance of literature on this subject, we observe that critical decisions regarding the design of VLMs are often not justified. We argue that these unsupported decisions impede progress in the field by making it difficult to identify which choices improve model performance. To address this issue, we conduct extensive experiments around pre-trained models, architecture choice, data, and training methods. Our consolidation of findings includes the development of Idefics2, an efficient foundational VLM of 8 billion parameters. Idefics2 achieves state-of-the-art performance within its size category across various multimodal benchmarks, and is often on par with models four times its size. We release the model (base, instructed, and chat) along with the datasets created for its training.
5/6/2024
👀
New!Vision Language Models in Autonomous Driving: A Survey and Outlook
Xingcheng Zhou, Mingyu Liu, Ekim Yurtsever, Bare Luka Zagar, Walter Zimmer, Hu Cao, Alois C. Knoll
0
0
The applications of Vision-Language Models (VLMs) in the field of Autonomous Driving (AD) have attracted widespread attention due to their outstanding performance and the ability to leverage Large Language Models (LLMs). By incorporating language data, driving systems can gain a better understanding of real-world environments, thereby enhancing driving safety and efficiency. In this work, we present a comprehensive and systematic survey of the advances in vision language models in this domain, encompassing perception and understanding, navigation and planning, decision-making and control, end-to-end autonomous driving, and data generation. We introduce the mainstream VLM tasks in AD and the commonly utilized metrics. Additionally, we review current studies and applications in various areas and summarize the existing language-enhanced autonomous driving datasets thoroughly. Lastly, we discuss the benefits and challenges of VLMs in AD and provide researchers with the current research gaps and future trends.
6/25/2024

VR-GPT: Visual Language Model for Intelligent Virtual Reality Applications
Mikhail Konenkov, Artem Lykov, Daria Trinitatova, Dzmitry Tsetserukou
0
0
The advent of immersive Virtual Reality applications has transformed various domains, yet their integration with advanced artificial intelligence technologies like Visual Language Models remains underexplored. This study introduces a pioneering approach utilizing VLMs within VR environments to enhance user interaction and task efficiency. Leveraging the Unity engine and a custom-developed VLM, our system facilitates real-time, intuitive user interactions through natural language processing, without relying on visual text instructions. The incorporation of speech-to-text and text-to-speech technologies allows for seamless communication between the user and the VLM, enabling the system to guide users through complex tasks effectively. Preliminary experimental results indicate that utilizing VLMs not only reduces task completion times but also improves user comfort and task engagement compared to traditional VR interaction methods.
5/21/2024