Verifiable evaluations of machine learning models using zkSNARKs
2402.02675
0
0
🏅
Abstract
In a world of increasing closed-source commercial machine learning models, model evaluations from developers must be taken at face value. These benchmark results-whether over task accuracy, bias evaluations, or safety checks-are traditionally impossible to verify by a model end-user without the costly or impossible process of re-performing the benchmark on black-box model outputs. This work presents a method of verifiable model evaluation using model inference through zkSNARKs. The resulting zero-knowledge computational proofs of model outputs over datasets can be packaged into verifiable evaluation attestations showing that models with fixed private weights achieve stated performance or fairness metrics over public inputs. We present a flexible proving system that enables verifiable attestations to be performed on any standard neural network model with varying compute requirements. For the first time, we demonstrate this across a sample of real-world models and highlight key challenges and design solutions. This presents a new transparency paradigm in the verifiable evaluation of private models.
Create account to get full access
Overview
- In a world where commercial machine learning models are often closed-source, developers' benchmark results are difficult to verify for end-users.
- This research presents a method for verifiable model evaluation using zero-knowledge succinct non-interactive arguments of knowledge (zkSNARKs).
- The proposed system generates zero-knowledge proofs of model outputs over public datasets, which can be packaged into verifiable evaluation attestations.
- This allows users to verify model performance and fairness metrics without accessing the private model weights or the datasets used.
Plain English Explanation
In the world of machine learning, many commercial models are "black boxes" - their inner workings are kept secret by the companies that develop them. This makes it hard for regular users to verify the claims these companies make about their models' accuracy, fairness, and other important metrics.
This research offers a solution to this problem. The researchers have developed a way to create "proofs" that a model is performing as claimed, without revealing the model's private details. These proofs are generated using a technique called zkSNARKs, which allows for verifiable computations without revealing the private information.
The key idea is that the model developer can generate a "proof" that their model achieves certain performance or fairness metrics on public datasets. This proof can then be shared with users, who can verify it without needing access to the model or the training data. This presents a new way for users to trust the claims made about machine learning models, even when the models themselves are proprietary.
Technical Explanation
The core of this research is a flexible proving system that can generate verifiable attestations for the outputs of standard neural network models. The system uses zkSNARKs to create these proofs, which allow the model's performance to be verified without revealing the private model weights or the datasets used for evaluation.
The researchers demonstrate this system across a range of real-world models, highlighting the key challenges and design solutions. For example, they address the varying compute requirements of different models by making the proving system flexible and scalable.
The resulting verifiable evaluation attestations can be used to establish trust in the claimed performance or fairness metrics of machine learning models, even when the models themselves are closed-source. This represents a significant advancement in the transparency and verifiability of commercial AI systems.
Critical Analysis
The research presents a promising approach to verifying the claims made about commercial machine learning models. By leveraging zkSNARKs, the system allows for verifiable evaluations without revealing sensitive information about the models or the data used.
However, the paper does acknowledge some limitations and areas for further research. For example, the current system relies on the model developer to generate the proofs, which introduces a potential trust issue. Future work could explore ways to make the proof generation more decentralized or collaborative, such as the approaches explored in this paper.
Additionally, the computational requirements of the proving system may still be a barrier for some use cases, particularly for large or complex models. Further optimizations or alternative proving techniques, like those discussed in this paper, could help address this challenge.
Overall, this research represents an important step towards increasing transparency and trust in commercial AI systems. By enabling verifiable evaluations of model performance and fairness, it has the potential to empower users and hold developers more accountable for their claims.
Conclusion
This research presents a novel method for verifying the claims made about commercial machine learning models, even when the models themselves are closed-source. By leveraging zkSNARKs to generate verifiable proofs of model outputs, the system allows users to validate performance and fairness metrics without accessing the private model details or training data.
This work has significant implications for the AI industry, as it offers a path towards greater transparency and accountability. By enabling users to independently verify the claims made about AI systems, it has the potential to build trust, promote responsible development practices, and empower end-users to make more informed decisions about the AI technologies they use.
While the research has some limitations that require further exploration, it represents an important step forward in the quest for trustworthy and verifiable AI.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Trustless Audits without Revealing Data or Models
Suppakit Waiwitlikhit, Ion Stoica, Yi Sun, Tatsunori Hashimoto, Daniel Kang
0
0
There is an increasing conflict between business incentives to hide models and data as trade secrets, and the societal need for algorithmic transparency. For example, a rightsholder wishing to know whether their copyrighted works have been used during training must convince the model provider to allow a third party to audit the model and data. Finding a mutually agreeable third party is difficult, and the associated costs often make this approach impractical. In this work, we show that it is possible to simultaneously allow model providers to keep their model weights (but not architecture) and data secret while allowing other parties to trustlessly audit model and data properties. We do this by designing a protocol called ZkAudit in which model providers publish cryptographic commitments of datasets and model weights, alongside a zero-knowledge proof (ZKP) certifying that published commitments are derived from training the model. Model providers can then respond to audit requests by privately computing any function F of the dataset (or model) and releasing the output of F alongside another ZKP certifying the correct execution of F. To enable ZkAudit, we develop new methods of computing ZKPs for SGD on modern neural nets for simple recommender systems and image classification models capable of high accuracies on ImageNet. Empirically, we show it is possible to provide trustless audits of DNNs, including copyright, censorship, and counterfactual audits with little to no loss in accuracy.
4/9/2024
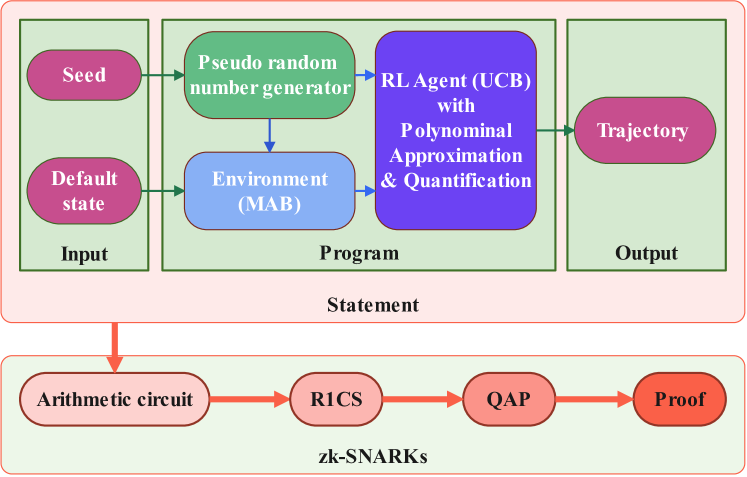
Privacy-Preserving UCB Decision Process Verification via zk-SNARKs
Xikun Jiang, He Lyu, Chenhao Ying, Yibin Xu, Boris Dudder, Yuan Luo
0
0
With the increasingly widespread application of machine learning, how to strike a balance between protecting the privacy of data and algorithm parameters and ensuring the verifiability of machine learning has always been a challenge. This study explores the intersection of reinforcement learning and data privacy, specifically addressing the Multi-Armed Bandit (MAB) problem with the Upper Confidence Bound (UCB) algorithm. We introduce zkUCB, an innovative algorithm that employs the Zero-Knowledge Succinct Non-Interactive Argument of Knowledge (zk-SNARKs) to enhance UCB. zkUCB is carefully designed to safeguard the confidentiality of training data and algorithmic parameters, ensuring transparent UCB decision-making. Experiments highlight zkUCB's superior performance, attributing its enhanced reward to judicious quantization bit usage that reduces information entropy in the decision-making process. zkUCB's proof size and verification time scale linearly with the execution steps of zkUCB. This showcases zkUCB's adept balance between data security and operational efficiency. This approach contributes significantly to the ongoing discourse on reinforcing data privacy in complex decision-making processes, offering a promising solution for privacy-sensitive applications.
6/10/2024
📈
Provable Guarantees for Model Performance via Mechanistic Interpretability
Jason Gross, Rajashree Agrawal, Thomas Kwa, Euan Ong, Chun Hei Yip, Alex Gibson, Soufiane Noubir, Lawrence Chan
0
0
In this work, we propose using mechanistic interpretability -- techniques for reverse engineering model weights into human-interpretable algorithms -- to derive and compactly prove formal guarantees on model performance. We prototype this approach by formally proving lower bounds on the accuracy of 151 small transformers trained on a Max-of-$K$ task. We create 102 different computer-assisted proof strategies and assess their length and tightness of bound on each of our models. Using quantitative metrics, we find that shorter proofs seem to require and provide more mechanistic understanding. Moreover, we find that more faithful mechanistic understanding leads to tighter performance bounds. We confirm these connections by qualitatively examining a subset of our proofs. Finally, we identify compounding structureless noise as a key challenge for using mechanistic interpretability to generate compact proofs on model performance.
6/26/2024
💬
zkLLM: Zero Knowledge Proofs for Large Language Models
Haochen Sun, Jason Li, Hongyang Zhang
0
0
The recent surge in artificial intelligence (AI), characterized by the prominence of large language models (LLMs), has ushered in fundamental transformations across the globe. However, alongside these advancements, concerns surrounding the legitimacy of LLMs have grown, posing legal challenges to their extensive applications. Compounding these concerns, the parameters of LLMs are often treated as intellectual property, restricting direct investigations. In this study, we address a fundamental challenge within the realm of AI legislation: the need to establish the authenticity of outputs generated by LLMs. To tackle this issue, we present zkLLM, which stands as the inaugural specialized zero-knowledge proof tailored for LLMs to the best of our knowledge. Addressing the persistent challenge of non-arithmetic operations in deep learning, we introduce tlookup, a parallelized lookup argument designed for non-arithmetic tensor operations in deep learning, offering a solution with no asymptotic overhead. Furthermore, leveraging the foundation of tlookup, we introduce zkAttn, a specialized zero-knowledge proof crafted for the attention mechanism, carefully balancing considerations of running time, memory usage, and accuracy. Empowered by our fully parallelized CUDA implementation, zkLLM emerges as a significant stride towards achieving efficient zero-knowledge verifiable computations over LLMs. Remarkably, for LLMs boasting 13 billion parameters, our approach enables the generation of a correctness proof for the entire inference process in under 15 minutes. The resulting proof, compactly sized at less than 200 kB, is designed to uphold the privacy of the model parameters, ensuring no inadvertent information leakage.
4/26/2024