Privacy-Preserving UCB Decision Process Verification via zk-SNARKs
2404.12186
0
0
Abstract
With the increasingly widespread application of machine learning, how to strike a balance between protecting the privacy of data and algorithm parameters and ensuring the verifiability of machine learning has always been a challenge. This study explores the intersection of reinforcement learning and data privacy, specifically addressing the Multi-Armed Bandit (MAB) problem with the Upper Confidence Bound (UCB) algorithm. We introduce zkUCB, an innovative algorithm that employs the Zero-Knowledge Succinct Non-Interactive Argument of Knowledge (zk-SNARKs) to enhance UCB. zkUCB is carefully designed to safeguard the confidentiality of training data and algorithmic parameters, ensuring transparent UCB decision-making. Experiments highlight zkUCB's superior performance, attributing its enhanced reward to judicious quantization bit usage that reduces information entropy in the decision-making process. zkUCB's proof size and verification time scale linearly with the execution steps of zkUCB. This showcases zkUCB's adept balance between data security and operational efficiency. This approach contributes significantly to the ongoing discourse on reinforcing data privacy in complex decision-making processes, offering a promising solution for privacy-sensitive applications.
Create account to get full access
Overview
- The paper presents a privacy-preserving method for verifying decisions made by a multi-armed bandit (MAB) algorithm using zero-knowledge succinct non-interactive arguments of knowledge (zk-SNARKs).
- The proposed system allows a client to verify that a server has followed the Upper Confidence Bound (UCB) MAB protocol without revealing the client's underlying data or the server's internal model.
- The authors demonstrate the practicality of their approach through theoretical analysis and experimental evaluation.
Plain English Explanation
The paper introduces a way to verify that a decision-making system, specifically a multi-armed bandit algorithm, is behaving correctly without revealing sensitive information about the system or the data it is using. [A multi-armed bandit algorithm is a type of machine learning model used to make decisions, like which advertisement to show a user, in a way that balances exploring new options and exploiting what has worked well in the past.]
The key idea is to use a cryptographic technique called zk-SNARKs to allow a client (e.g., an individual user) to check that the server (e.g., an online platform) is following the Upper Confidence Bound (UCB) decision-making process a commonly used multi-armed bandit algorithm, described in more detail in this paper without revealing the client's private data or the server's internal model.
This could be useful in applications where the client wants to verify the fairness and transparency of the decision-making process, such as in content recommendation systems or clinical trial enrollment, without compromising privacy or revealing sensitive information.
Technical Explanation
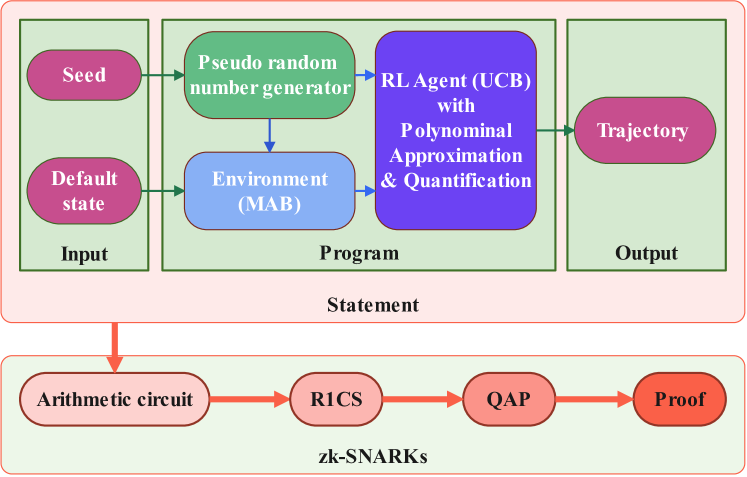
The paper presents a privacy-preserving UCB verification system that uses zk-SNARKs to allow a client to verify that a server is correctly following the UCB decision-making process without revealing the client's data or the server's internal model.
The key components of the system are:
- UCB Decision Process: The server uses the UCB algorithm to make decisions based on the client's data.
- Commitment Scheme: The server commits to the UCB decision process using a cryptographic commitment scheme.
- zk-SNARK Proofs: The server generates zk-SNARK proofs to demonstrate that the committed UCB decision process was followed correctly, without revealing any sensitive information.
- Verification: The client verifies the zk-SNARK proofs to ensure the server's decisions were made according to the UCB protocol.
The authors provide a formal security analysis and demonstrate the practicality of the approach through experimental evaluation, showing that the zk-SNARK proofs can be generated and verified efficiently.
Critical Analysis
The paper presents a compelling solution to the problem of verifying the fairness and transparency of decision-making systems without compromising privacy. The use of zk-SNARKs is a clever way to enable auditing without revealing sensitive information.
One potential limitation is the reliance on the UCB algorithm, which may not be the optimal decision-making strategy in all scenarios. The authors acknowledge this and suggest that the approach could be extended to other multi-armed bandit algorithms as discussed in this related work.
Additionally, the security analysis assumes the server is honest-but-curious, meaning it follows the protocol correctly but may attempt to learn information about the client's data. In practice, a more adversarial server model may be necessary, which could introduce additional complexity or performance challenges.
Overall, the paper presents an important step towards privacy-preserving verification of decision-making systems, and the authors' thoughtful consideration of the limitations and future work directions suggests a strong foundation for further research in this area.
Conclusion
The presented privacy-preserving UCB verification system using zk-SNARKs addresses a critical need for auditing decision-making algorithms without compromising sensitive information. By enabling clients to verify the fairness and transparency of the decision-making process, this work contributes to building trust in automated systems and paves the way for more accountable and ethical AI applications in domains like content recommendation, clinical trial enrollment, and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏅
Verifiable evaluations of machine learning models using zkSNARKs
Tobin South, Alexander Camuto, Shrey Jain, Shayla Nguyen, Robert Mahari, Christian Paquin, Jason Morton, Alex 'Sandy' Pentland
0
0
In a world of increasing closed-source commercial machine learning models, model evaluations from developers must be taken at face value. These benchmark results-whether over task accuracy, bias evaluations, or safety checks-are traditionally impossible to verify by a model end-user without the costly or impossible process of re-performing the benchmark on black-box model outputs. This work presents a method of verifiable model evaluation using model inference through zkSNARKs. The resulting zero-knowledge computational proofs of model outputs over datasets can be packaged into verifiable evaluation attestations showing that models with fixed private weights achieve stated performance or fairness metrics over public inputs. We present a flexible proving system that enables verifiable attestations to be performed on any standard neural network model with varying compute requirements. For the first time, we demonstrate this across a sample of real-world models and highlight key challenges and design solutions. This presents a new transparency paradigm in the verifiable evaluation of private models.
5/24/2024
Data-Driven Upper Confidence Bounds with Near-Optimal Regret for Heavy-Tailed Bandits
Ambrus Tam'as, Szabolcs Szentp'eteri, Bal'azs Csan'ad Cs'aji
0
0
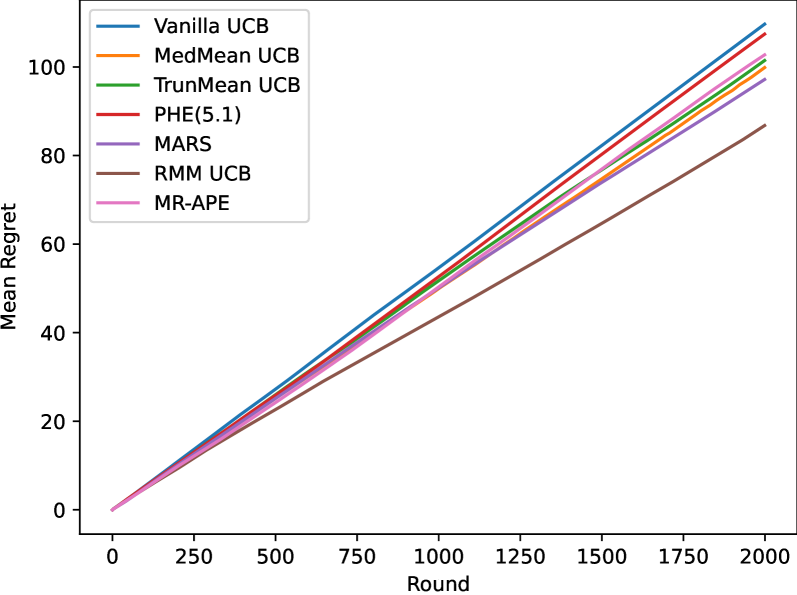
Stochastic multi-armed bandits (MABs) provide a fundamental reinforcement learning model to study sequential decision making in uncertain environments. The upper confidence bounds (UCB) algorithm gave birth to the renaissance of bandit algorithms, as it achieves near-optimal regret rates under various moment assumptions. Up until recently most UCB methods relied on concentration inequalities leading to confidence bounds which depend on moment parameters, such as the variance proxy, that are usually unknown in practice. In this paper, we propose a new distribution-free, data-driven UCB algorithm for symmetric reward distributions, which needs no moment information. The key idea is to combine a refined, one-sided version of the recently developed resampled median-of-means (RMM) method with UCB. We prove a near-optimal regret bound for the proposed anytime, parameter-free RMM-UCB method, even for heavy-tailed distributions.
6/11/2024
🐍
Concentrated Differential Privacy for Bandits
Achraf Azize, Debabrota Basu
0
0
Bandits serve as the theoretical foundation of sequential learning and an algorithmic foundation of modern recommender systems. However, recommender systems often rely on user-sensitive data, making privacy a critical concern. This paper contributes to the understanding of Differential Privacy (DP) in bandits with a trusted centralised decision-maker, and especially the implications of ensuring zero Concentrated Differential Privacy (zCDP). First, we formalise and compare different adaptations of DP to bandits, depending on the considered input and the interaction protocol. Then, we propose three private algorithms, namely AdaC-UCB, AdaC-GOPE and AdaC-OFUL, for three bandit settings, namely finite-armed bandits, linear bandits, and linear contextual bandits. The three algorithms share a generic algorithmic blueprint, i.e. the Gaussian mechanism and adaptive episodes, to ensure a good privacy-utility trade-off. We analyse and upper bound the regret of these three algorithms. Our analysis shows that in all of these settings, the prices of imposing zCDP are (asymptotically) negligible in comparison with the regrets incurred oblivious to privacy. Next, we complement our regret upper bounds with the first minimax lower bounds on the regret of bandits with zCDP. To prove the lower bounds, we elaborate a new proof technique based on couplings and optimal transport. We conclude by experimentally validating our theoretical results for the three different settings of bandits.
4/16/2024
Leveraging (Biased) Information: Multi-armed Bandits with Offline Data
Wang Chi Cheung, Lixing Lyu
0
0
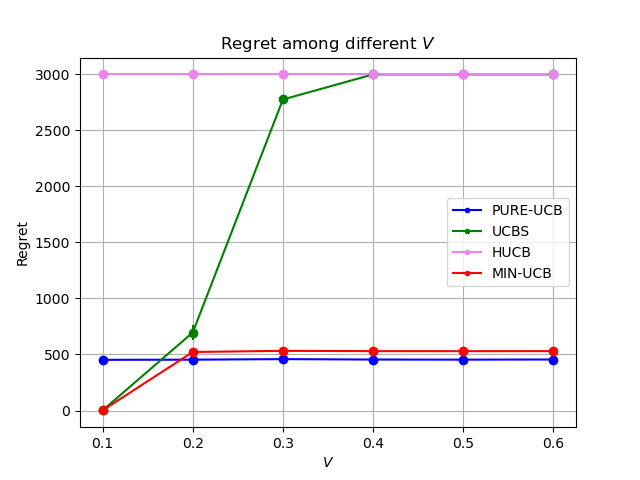
We leverage offline data to facilitate online learning in stochastic multi-armed bandits. The probability distributions that govern the offline data and the online rewards can be different. Without any non-trivial upper bound on their difference, we show that no non-anticipatory policy can outperform the UCB policy by (Auer et al. 2002), even in the presence of offline data. In complement, we propose an online policy MIN-UCB, which outperforms UCB when a non-trivial upper bound is given. MIN-UCB adaptively chooses to utilize the offline data when they are deemed informative, and to ignore them otherwise. MIN-UCB is shown to be tight in terms of both instance independent and dependent regret bounds. Finally, we corroborate the theoretical results with numerical experiments.
5/7/2024