VerityMath: Advancing Mathematical Reasoning by Self-Verification Through Unit Consistency

0
🎲
Sign in to get full access
Overview
- Large language models (LLMs) are demonstrating increasing proficiency in mathematical reasoning, including solving math word problems.
- Open-source LLMs have shown limited progress in this area, and the challenges they face are not well-studied.
- This paper examines the performance of strong open-source LLMs on math word problems using program-based solving techniques.
- The authors identify a category of problems involving quantities with multiple units as a significant challenge for these models.
- To address this, the authors propose a systematic approach using Unit Consistency Programs (UCPs) to ensure consistency of units during mathematical operations.
Plain English Explanation
Large language models, which are powerful AI systems that can understand and generate human-like text, are getting better at solving math problems. Some closed-source models, like OpenAI's GPT-4 and a model called Claude, have shown impressive results in solving math word problems.
However, open-source language models, which are available for anyone to use and study, have not made as much progress in this area. The researchers in this paper wanted to understand the specific challenges these open-source models face when solving math word problems.
They tested three strong open-source language models - Llama 2, Code Llama, and Mistral - on a variety of math word problems. They found that the models struggled the most with problems involving quantities that had different units, like feet and inches or dollars and cents.
To address this, the researchers developed something called Unit Consistency Programs (UCPs). These are math word problems that have been annotated with information about the units of each quantity, and with routines to check that the units are used correctly during the math operations.
The researchers then fine-tuned the three language models using the UCPs, creating "VerityMath" variants of the models. They found that this approach slightly underperformed compared to not using the UCPs. The researchers then analyzed the errors to try to understand why and suggest ways to improve the approach in the future.
Technical Explanation
The paper examines the performance of open-source large language models (LLMs), including Llama 2 (7B), Code Llama (7B), and Mistral (7B), on math word problem-solving using program-based techniques. The authors identify challenges these models face, particularly with problems involving quantities spanning multiple units.
To address this, the researchers proposed a systematic approach using Unit Consistency Programs (UCPs), an annotated dataset of math word problems paired with programs containing unit specifications and unit verification routines. The authors fine-tuned the Llama 2 (7B), Code Llama (7B), and Mistral (7B) models with the UCPs to produce their "VerityMath" variants.
The findings indicate that the VerityMath approach, which incorporates unit consistency, currently slightly underperforms compared to an approach that does not. The researchers conducted an in-depth error analysis to understand the reasons behind this and suggest options for future improvements.
Critical Analysis
The paper provides a valuable contribution by identifying a specific challenge faced by open-source LLMs in solving math word problems - the handling of quantities with multiple units. The proposed solution of using Unit Consistency Programs is a systematic approach to address this issue.
However, the finding that the VerityMath approach slightly underperforms compared to the baseline raises questions about the effectiveness of this solution. The authors' error analysis and suggestions for future improvements are helpful, but more research may be needed to fully understand the limitations and optimize the approach.
Additionally, the paper focuses on a specific set of open-source LLMs, and it would be interesting to see how the findings and proposed solutions apply to a broader range of models, including closed-source ones. Expanding the scope of the research could provide a more comprehensive understanding of the challenges and potential solutions in this area.
Conclusion
This paper highlights the progress of LLMs in mathematical reasoning and the specific challenges they face with math word problems involving quantities across multiple units. The authors' proposed solution of using Unit Consistency Programs is a promising approach, though the current underperformance compared to the baseline suggests room for further refinement and investigation.
The research contributes to the ongoing efforts to improve the mathematical capabilities of LLMs, which could have significant implications for various applications, from education to scientific research. As the field of large language models continues to evolve, studies like this one will be valuable in shaping the future development and real-world deployment of these powerful AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🎲
0
VerityMath: Advancing Mathematical Reasoning by Self-Verification Through Unit Consistency
Vernon Toh Yan Han, Ratish Puduppully, Nancy F. Chen
Large Language Models (LLMs), combined with program-based solving techniques, are increasingly demonstrating proficiency in mathematical reasoning. For example, closed-source models such as OpenAI GPT-4 and Claude show excellent results in solving math word problems. However, progress in math word problem-solving for open-source LLMs is limited, and the challenges these models face are not well-studied. In this paper, we study the performance of strong open-source LLMs, including Llama 2 (7B), Code Llama (7B), and Mistral (7B) on math word problems using program-based solving techniques. Specifically, we analyze the outputs of these models when applied to math word problems and identify a category of problems that pose a significant challenge, particularly those involving quantities spanning multiple units. To address this issue, we propose a systematic approach by defining the units for each quantity and ensuring the consistency of these units during mathematical operations. We developed Unit Consistency Programs (UCPs), an annotated dataset of math word problems, each paired with programs containing unit specifications and unit verification routines. We fine-tuned Llama 2 (7B), Code Llama (7B), and Mistral (7B) models with UCPs to produce theirVerityMath variants. Our findings indicate that our approach, which incorporates unit consistency, currently slightly underperforms compared to an approach that does not. To understand the reasons behind this, we conduct an in-depth error analysis and suggest options for future improvements. Our code and dataset are available at https://github.com/vernontoh/VerityMath.
Read more7/23/2024

0
Caught in the Quicksand of Reasoning, Far from AGI Summit: Evaluating LLMs' Mathematical and Coding Competency through Ontology-guided Interventions
Pengfei Hong, Navonil Majumder, Deepanway Ghosal, Somak Aditya, Rada Mihalcea, Soujanya Poria
Recent advancements in Large Language Models (LLMs) have showcased striking results on existing logical reasoning benchmarks, with some models even surpassing human performance. However, the true depth of their competencies and robustness in reasoning tasks remains an open question. To this end, in this paper, we focus on two popular reasoning tasks: arithmetic reasoning and code generation. Particularly, we introduce: (i) a general ontology of perturbations for maths and coding questions, (ii) a semi-automatic method to apply these perturbations, and (iii) two datasets, MORE and CORE, respectively, of perturbed maths and coding problems to probe the limits of LLM capabilities in numeric reasoning and coding tasks. Through comprehensive evaluations of both closed-source and open-source LLMs, we show a significant performance drop across all the models against the perturbed questions, suggesting that the current LLMs lack robust problem solving skills and structured reasoning abilities in many areas, as defined by our ontology. We open source the datasets and source codes at: https://github.com/declare-lab/llm_robustness.
Read more6/28/2024

0
NUMCoT: Numerals and Units of Measurement in Chain-of-Thought Reasoning using Large Language Models
Ancheng Xu, Minghuan Tan, Lei Wang, Min Yang, Ruifeng Xu
Numeral systems and units of measurement are two conjoined topics in activities of human beings and have mutual effects with the languages expressing them. Currently, the evaluation of Large Language Models (LLMs) often involves mathematical reasoning, yet little attention is given to how minor changes in numbers or units can drastically alter the complexity of problems and the performance of LLMs. In this paper, we scrutinize existing LLMs on processing of numerals and units of measurement by constructing datasets with perturbations. We first anatomize the reasoning of math word problems to different sub-procedures like numeral conversions from language to numbers and measurement conversions based on units. Then we further annotate math word problems from ancient Chinese arithmetic works which are challenging in numerals and units of measurement. Experiments on perturbed datasets demonstrate that LLMs still encounter difficulties in handling numeral and measurement conversions.
Read more6/6/2024
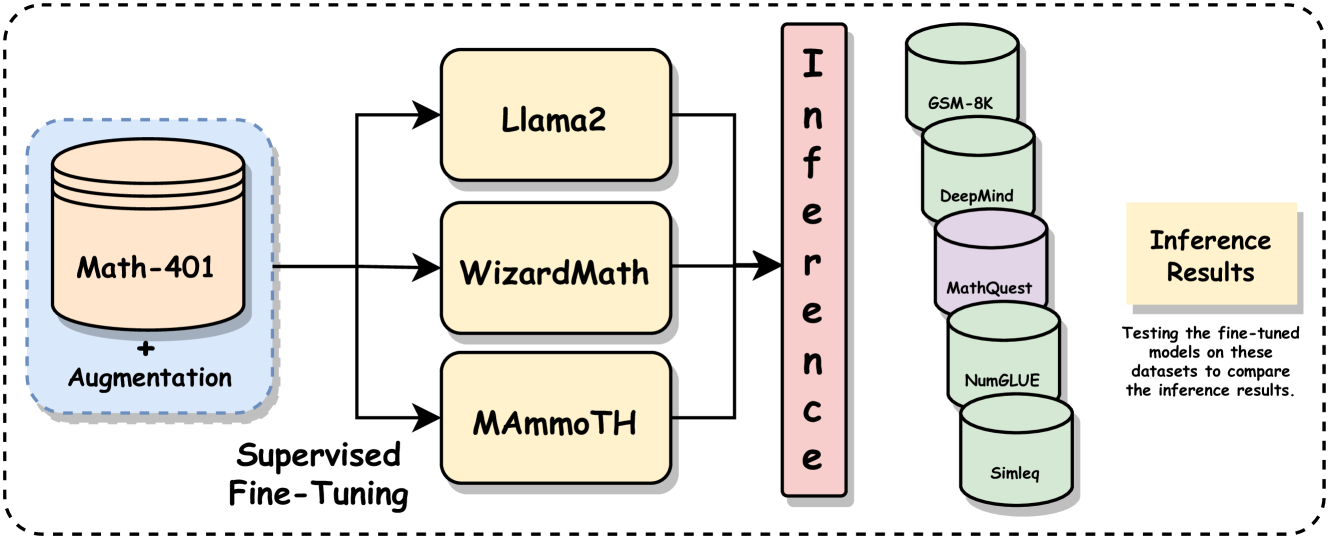
0
Mathify: Evaluating Large Language Models on Mathematical Problem Solving Tasks
Avinash Anand, Mohit Gupta, Kritarth Prasad, Navya Singla, Sanjana Sanjeev, Jatin Kumar, Adarsh Raj Shivam, Rajiv Ratn Shah
The rapid progress in the field of natural language processing (NLP) systems and the expansion of large language models (LLMs) have opened up numerous opportunities in the field of education and instructional methods. These advancements offer the potential for tailored learning experiences and immediate feedback, all delivered through accessible and cost-effective services. One notable application area for this technological advancement is in the realm of solving mathematical problems. Mathematical problem-solving not only requires the ability to decipher complex problem statements but also the skill to perform precise arithmetic calculations at each step of the problem-solving process. However, the evaluation of the arithmetic capabilities of large language models remains an area that has received relatively little attention. In response, we introduce an extensive mathematics dataset called MathQuest sourced from the 11th and 12th standard Mathematics NCERT textbooks. This dataset encompasses mathematical challenges of varying complexity and covers a wide range of mathematical concepts. Utilizing this dataset, we conduct fine-tuning experiments with three prominent LLMs: LLaMA-2, WizardMath, and MAmmoTH. These fine-tuned models serve as benchmarks for evaluating their performance on our dataset. Our experiments reveal that among the three models, MAmmoTH-13B emerges as the most proficient, achieving the highest level of competence in solving the presented mathematical problems. Consequently, MAmmoTH-13B establishes itself as a robust and dependable benchmark for addressing NCERT mathematics problems.
Read more4/23/2024