Caught in the Quicksand of Reasoning, Far from AGI Summit: Evaluating LLMs' Mathematical and Coding Competency through Ontology-guided Interventions
2401.09395
0
0

Abstract
Recent advancements in Large Language Models (LLMs) have showcased striking results on existing logical reasoning benchmarks, with some models even surpassing human performance. However, the true depth of their competencies and robustness in reasoning tasks remains an open question. To this end, in this paper, we focus on two popular reasoning tasks: arithmetic reasoning and code generation. Particularly, we introduce: (i) a general ontology of perturbations for maths and coding questions, (ii) a semi-automatic method to apply these perturbations, and (iii) two datasets, MORE and CORE, respectively, of perturbed maths and coding problems to probe the limits of LLM capabilities in numeric reasoning and coding tasks. Through comprehensive evaluations of both closed-source and open-source LLMs, we show a significant performance drop across all the models against the perturbed questions, suggesting that the current LLMs lack robust problem solving skills and structured reasoning abilities in many areas, as defined by our ontology. We open source the datasets and source codes at: https://github.com/declare-lab/llm_robustness.
Create account to get full access
Overview
- This paper evaluates the mathematical competency of large language models (LLMs) through a series of carefully designed perturbations guided by a mathematical ontology.
- The authors find that while LLMs demonstrate impressive performance on standard math benchmarks, they struggle with more nuanced mathematical reasoning tasks that require a deeper understanding of underlying concepts.
- The paper argues that current LLM evaluations often overlook these limitations, painting an overly optimistic picture of their mathematical abilities and masking their limitations relative to human-level mathematical reasoning.
Plain English Explanation
The paper examines how well large language models (LLMs) - powerful AI systems that can understand and generate human-like text - perform on mathematical reasoning tasks. While these models have shown impressive results on standard math tests, the researchers wanted to dig deeper and see how they handle more complex, nuanced mathematical concepts.
To do this, the researchers developed a set of carefully crafted "perturbations" - small tweaks or changes to standard math problems. These perturbations were guided by a detailed ontology, or map, of mathematical concepts. The goal was to see how the LLMs would respond when faced with problems that required a deeper, more sophisticated understanding of underlying mathematical principles.
The results were eye-opening. The LLMs struggled with many of these perturbed math problems, revealing significant gaps in their mathematical competency. The authors argue that current evaluations of LLM math abilities often miss these limitations, painting an overly optimistic picture of their capabilities. In reality, these models are still far from matching human-level mathematical reasoning and understanding.
This work highlights the importance of going beyond superficial benchmarks when assessing the capabilities of advanced AI systems. By digging deeper and probing the limits of their knowledge, the researchers were able to uncover fundamental shortcomings in the LLMs' mathematical abilities. This is a crucial step in understanding the true strengths and weaknesses of these powerful technologies as they continue to evolve.
Technical Explanation
The paper presents a novel approach to evaluating the mathematical competency of large language models (LLMs) using ontology-guided perturbations. The authors first construct a detailed ontology of mathematical concepts, capturing the hierarchical relationships and dependencies between different ideas and skills.
They then leverage this ontology to generate a suite of perturbed math problems, where small tweaks are made to standard questions in order to probe the models' deeper understanding. For example, a problem may be reframed slightly to require the application of a particular mathematical principle or the recognition of a specific pattern.
By evaluating the LLMs' performance on these perturbed problems, the researchers are able to identify significant gaps in the models' mathematical reasoning abilities. Despite their strong performance on standard benchmarks, the LLMs struggle with many of the ontology-guided perturbations, revealing limitations in their grasp of underlying mathematical concepts.
The authors argue that these findings call into question the conclusions drawn from common LLM evaluations, which often present an overly optimistic view of their mathematical competency. They suggest that a more comprehensive, ontology-driven approach is necessary to truly assess the capabilities and limitations of these powerful language models.
Critical Analysis
The ontology-guided perturbation approach presented in this paper represents a significant advancement in the evaluation of LLM mathematical abilities. By moving beyond simple benchmark tests and probing deeper into the models' conceptual understanding, the researchers have uncovered important shortcomings that were previously obscured.
However, it is important to note that the ontology developed in this work, while comprehensive, may not capture the full breadth and complexity of mathematical knowledge. There may be additional nuances and dependencies that are not fully represented, which could limit the scope of the perturbations and the conclusions drawn from them.
Additionally, the performance of LLMs on these perturbed problems may be influenced by factors beyond just their mathematical understanding, such as the way the problems are framed or the specific language used. Further research is needed to disentangle these different aspects and gain a more granular understanding of the models' strengths and weaknesses.
Despite these potential limitations, the overall approach and findings of this paper are valuable contributions to the ongoing discussions around the capabilities and limitations of large language models. By challenging the field to move beyond simplistic benchmarks and delve deeper into the models' mathematical reasoning, the authors have opened up new avenues for exploration and improvement.
Conclusion
This paper presents a novel, ontology-guided approach to evaluating the mathematical competency of large language models (LLMs). The results reveal that while these models excel on standard math benchmarks, they struggle with more nuanced, conceptually-grounded mathematical reasoning tasks.
This work underscores the importance of going beyond surface-level evaluations when assessing the capabilities of advanced AI systems. By probing the limits of the LLMs' knowledge and understanding, the researchers have exposed significant gaps that were previously overlooked.
The implications of this research extend beyond just mathematical reasoning, as it highlights the need for more comprehensive, multi-faceted approaches to evaluating the capabilities of large language models and other AI systems. As these technologies continue to evolve, it will be crucial to maintain a clear-eyed view of their strengths and weaknesses in order to guide their development and deployment in responsible and beneficial ways.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
LogicBench: Towards Systematic Evaluation of Logical Reasoning Ability of Large Language Models
Mihir Parmar, Nisarg Patel, Neeraj Varshney, Mutsumi Nakamura, Man Luo, Santosh Mashetty, Arindam Mitra, Chitta Baral
0
0
Recently developed large language models (LLMs) have been shown to perform remarkably well on a wide range of language understanding tasks. But, can they really reason over the natural language? This question has been receiving significant research attention and many reasoning skills such as commonsense, numerical, and qualitative have been studied. However, the crucial skill pertaining to 'logical reasoning' has remained underexplored. Existing work investigating this reasoning ability of LLMs has focused only on a couple of inference rules (such as modus ponens and modus tollens) of propositional and first-order logic. Addressing the above limitation, we comprehensively evaluate the logical reasoning ability of LLMs on 25 different reasoning patterns spanning over propositional, first-order, and non-monotonic logics. To enable systematic evaluation, we introduce LogicBench, a natural language question-answering dataset focusing on the use of a single inference rule. We conduct detailed analysis with a range of LLMs such as GPT-4, ChatGPT, Gemini, Llama-2, and Mistral using chain-of-thought prompting. Experimental results show that existing LLMs do not fare well on LogicBench; especially, they struggle with instances involving complex reasoning and negations. Furthermore, they sometimes overlook contextual information necessary for reasoning to arrive at the correct conclusion. We believe that our work and findings facilitate future research for evaluating and enhancing the logical reasoning ability of LLMs. Data and code are available at https://github.com/Mihir3009/LogicBench.
6/7/2024

Large Language Models for Mathematical Reasoning: Progresses and Challenges
Janice Ahn, Rishu Verma, Renze Lou, Di Liu, Rui Zhang, Wenpeng Yin
0
0
Mathematical reasoning serves as a cornerstone for assessing the fundamental cognitive capabilities of human intelligence. In recent times, there has been a notable surge in the development of Large Language Models (LLMs) geared towards the automated resolution of mathematical problems. However, the landscape of mathematical problem types is vast and varied, with LLM-oriented techniques undergoing evaluation across diverse datasets and settings. This diversity makes it challenging to discern the true advancements and obstacles within this burgeoning field. This survey endeavors to address four pivotal dimensions: i) a comprehensive exploration of the various mathematical problems and their corresponding datasets that have been investigated; ii) an examination of the spectrum of LLM-oriented techniques that have been proposed for mathematical problem-solving; iii) an overview of factors and concerns affecting LLMs in solving math; and iv) an elucidation of the persisting challenges within this domain. To the best of our knowledge, this survey stands as one of the first extensive examinations of the landscape of LLMs in the realm of mathematics, providing a holistic perspective on the current state, accomplishments, and future challenges in this rapidly evolving field.
4/8/2024
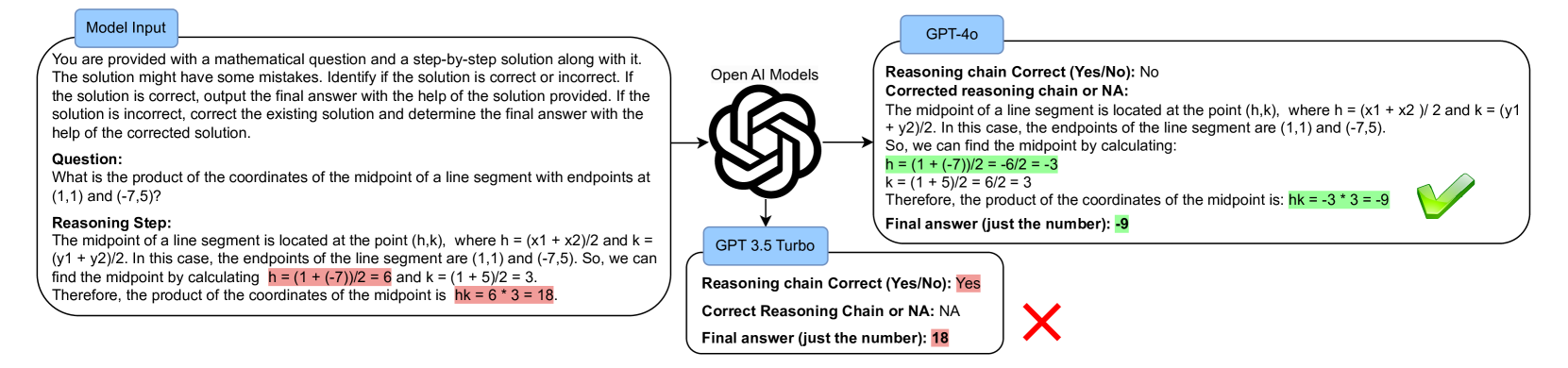
Exposing the Achilles' Heel: Evaluating LLMs Ability to Handle Mistakes in Mathematical Reasoning
Joykirat Singh, Akshay Nambi, Vibhav Vineet
0
0
Large Language Models (LLMs) have been applied to Math Word Problems (MWPs) with transformative impacts, revolutionizing how these complex problems are approached and solved in various domains including educational settings. However, the evaluation of these models often prioritizes final accuracy, overlooking the crucial aspect of reasoning capabilities. This work addresses this gap by focusing on the ability of LLMs to detect and correct reasoning mistakes. We introduce a novel dataset MWP-MISTAKE, incorporating MWPs with both correct and incorrect reasoning steps generated through rule-based methods and smaller language models. Our comprehensive benchmarking reveals significant insights into the strengths and weaknesses of state-of-the-art models, such as GPT-4o, GPT-4, GPT-3.5Turbo, and others. We highlight GPT-$o's superior performance in mistake detection and rectification and the persistent challenges faced by smaller models. Additionally, we identify issues related to data contamination and memorization, impacting the reliability of LLMs in real-world applications. Our findings emphasize the importance of rigorous evaluation of reasoning processes and propose future directions to enhance the generalization and robustness of LLMs in mathematical problem-solving.
6/18/2024

Can LLMs Reason in the Wild with Programs?
Yuan Yang, Siheng Xiong, Ali Payani, Ehsan Shareghi, Faramarz Fekri
0
0
Large Language Models (LLMs) have shown superior capability to solve reasoning problems with programs. While being a promising direction, most of such frameworks are trained and evaluated in settings with a prior knowledge of task requirements. However, as LLMs become more capable, it is necessary to assess their reasoning abilities in more realistic scenarios where many real-world problems are open-ended with ambiguous scope, and often require multiple formalisms to solve. To investigate this, we introduce the task of reasoning in the wild, where an LLM is tasked to solve a reasoning problem of unknown type by identifying the subproblems and their corresponding formalisms, and writing a program to solve each subproblem, guided by a tactic. We create a large tactic-guided trajectory dataset containing detailed solutions to a diverse set of reasoning problems, ranging from well-defined single-form reasoning (e.g., math, logic), to ambiguous and hybrid ones (e.g., commonsense, combined math and logic). This allows us to test various aspects of LLMs reasoning at the fine-grained level such as the selection and execution of tactics, and the tendency to take undesired shortcuts. In experiments, we highlight that existing LLMs fail significantly on problems with ambiguous and mixed scope, revealing critical limitations and overfitting issues (e.g. accuracy on GSM8K drops by at least 50%). We further show the potential of finetuning a local LLM on the tactic-guided trajectories in achieving better performance. Project repo is available at github.com/gblackout/Reason-in-the-Wild
6/21/2024