VGBench: Evaluating Large Language Models on Vector Graphics Understanding and Generation

0

Sign in to get full access
VGBench: Evaluating Large Language Models on Vector Graphics Understanding and Generation
Overview
- This paper introduces VGBench, a new benchmark for evaluating large language models (LLMs) on tasks related to vector graphics understanding and generation.
- The benchmark includes tasks such as parsing vector graphics, generating vector graphics from text descriptions, and reasoning about vector graphics.
- The paper evaluates several prominent LLMs on the VGBench tasks and provides insights into their capabilities and limitations in working with vector graphics.
Plain English Explanation
The researchers have created a new test, called VGBench, to see how well large language models (LLMs) - powerful AI systems that can understand and generate human-like text - can work with vector graphics. Vector graphics are a type of digital image that uses mathematical formulas to define the shapes and colors, rather than storing individual pixels.
The VGBench test includes various tasks that require the LLMs to understand, interpret, and even generate vector graphics. For example, one task might ask the model to read a vector graphic and describe what it depicts in words. Another task could ask the model to create a new vector graphic based on a textual description.
By evaluating how well different LLMs perform on these vector graphics tasks, the researchers hope to better understand the capabilities and limitations of these powerful AI systems when it comes to working with this type of visual data. This could help guide the development of LLMs that are more adept at handling vector graphics, which are commonly used in areas like design, illustration, and data visualization.
Technical Explanation
The paper introduces VGBench, a new benchmark for evaluating the performance of large language models (LLMs) on vector graphics-related tasks. The benchmark includes the following tasks:
- Vector Graphics Parsing: Asking LLMs to interpret and describe the contents of a given vector graphic.
- Vector Graphics Generation: Asking LLMs to generate a vector graphic based on a textual description.
- Vector Graphics Reasoning: Asking LLMs to answer questions or perform logical reasoning about the contents and properties of a vector graphic.
The researchers evaluate the performance of several prominent LLMs, including GPT-3, DALL-E 2, and PaLM, on the VGBench tasks. The results provide insights into the strengths and limitations of these models when it comes to understanding and manipulating vector graphics data.
Critical Analysis
The VGBench benchmark represents an important step in exploring the capability of LLMs to perform low-level visual tasks beyond just high-level image classification and captioning. By focusing on vector graphics, the benchmark challenges LLMs to reason about the underlying geometric and semantic structures of visual data, rather than just recognizing broad visual patterns.
However, the paper acknowledges several limitations of the current VGBench, including the relatively small size of the dataset and the potential for biases in the task formulations. Additionally, the effectiveness assessment of recent large vision-language models on these tasks could be expanded to include a wider range of models and more diverse evaluation metrics.
Future work could also explore ways to integrate VGBench more seamlessly with real-world applications of vector graphics, such as design, data visualization, and engineering workflows. Ultimately, the VGBench benchmark serves as a valuable tool for pushing the boundaries of LLM capabilities and advancing the field of AI-powered vector graphics understanding and generation.
Conclusion
The VGBench paper presents a new benchmark for evaluating the performance of large language models (LLMs) on tasks related to vector graphics understanding and generation. By assessing the capabilities of prominent LLMs on a range of vector graphics-focused tasks, the research provides valuable insights into the strengths and limitations of these powerful AI systems when working with this type of visual data.
The development of VGBench represents an important step forward in exploring the capabilities of LLMs to handle low-level visual tasks, which could have significant implications for a variety of applications, from design and data visualization to engineering and beyond. As the field of AI continues to advance, benchmarks like VGBench will play a crucial role in guiding the development of even more capable and versatile language models that can seamlessly integrate visual and textual understanding.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
VGBench: Evaluating Large Language Models on Vector Graphics Understanding and Generation
Bocheng Zou, Mu Cai, Jianrui Zhang, Yong Jae Lee
In the realm of vision models, the primary mode of representation is using pixels to rasterize the visual world. Yet this is not always the best or unique way to represent visual content, especially for designers and artists who depict the world using geometry primitives such as polygons. Vector graphics (VG), on the other hand, offer a textual representation of visual content, which can be more concise and powerful for content like cartoons, sketches and scientific figures. Recent studies have shown promising results on processing vector graphics with capable Large Language Models (LLMs). However, such works focus solely on qualitative results, understanding, or a specific type of vector graphics. We propose VGBench, a comprehensive benchmark for LLMs on handling vector graphics through diverse aspects, including (a) both visual understanding and generation, (b) evaluation of various vector graphics formats, (c) diverse question types, (d) wide range of prompting techniques, (e) under multiple LLMs and (f) comparison with VLMs on rasterized representations. Evaluating on our collected 4279 understanding and 5845 generation samples, we find that LLMs show strong capability on both aspects while exhibiting less desirable performance on low-level formats (SVG). Both data and evaluation pipeline will be open-sourced at https://vgbench.github.io.
Read more8/30/2024

0
Text-Based Reasoning About Vector Graphics
Zhenhailong Wang, Joy Hsu, Xingyao Wang, Kuan-Hao Huang, Manling Li, Jiajun Wu, Heng Ji
While large multimodal models excel in broad vision-language benchmarks, they often struggle with tasks requiring precise perception of low-level visual details, such as comparing line lengths or solving simple mazes. In particular, this failure mode persists in question-answering tasks about vector graphics -- images composed purely of 2D objects and shapes. To address this challenge, we propose the Visually Descriptive Language Model (VDLM), which performs text-based reasoning about vector graphics. VDLM leverages Scalable Vector Graphics (SVG) for a more precise visual description and first uses an off-the-shelf raster-to-SVG algorithm for encoding. Since existing language models cannot understand raw SVGs in a zero-shot setting, VDLM then bridges SVG with pretrained language models through a newly introduced intermediate symbolic representation, Primal Visual Description (PVD), comprising primitive attributes (e.g., shape, position, measurement) with their corresponding predicted values. PVD is task-agnostic and represents visual primitives that are universal across all vector graphics. It can be learned with procedurally generated (SVG, PVD) pairs and also enables the direct use of LLMs for generalization to complex reasoning tasks. By casting an image to a text-based representation, we can leverage the power of language models to learn alignment from SVG to visual primitives and generalize to unseen question-answering tasks. Empirical results show that VDLM achieves stronger zero-shot performance compared to state-of-the-art LMMs, such as GPT-4V, in various low-level multimodal perception and reasoning tasks on vector graphics. We additionally present extensive analyses on VDLM's performance, demonstrating that our framework offers better interpretability due to its disentangled perception and reasoning processes. Project page: https://mikewangwzhl.github.io/VDLM/
Read more5/28/2024
💬
0
Leveraging Large Language Models for Scalable Vector Graphics-Driven Image Understanding
Mu Cai, Zeyi Huang, Yuheng Li, Utkarsh Ojha, Haohan Wang, Yong Jae Lee
Large language models (LLMs) have made significant advancements in natural language understanding. However, through that enormous semantic representation that the LLM has learnt, is it somehow possible for it to understand images as well? This work investigates this question. To enable the LLM to process images, we convert them into a representation given by Scalable Vector Graphics (SVG). To study what the LLM can do with this XML-based textual description of images, we test the LLM on three broad computer vision tasks: (i) visual reasoning and question answering, (ii) image classification under distribution shift, few-shot learning, and (iii) generating new images using visual prompting. Even though we do not naturally associate LLMs with any visual understanding capabilities, our results indicate that the LLM can often do a decent job in many of these tasks, potentially opening new avenues for research into LLMs' ability to understand image data. Our code, data, and models can be found here https://github.com/mu-cai/svg-llm.
Read more7/12/2024
0
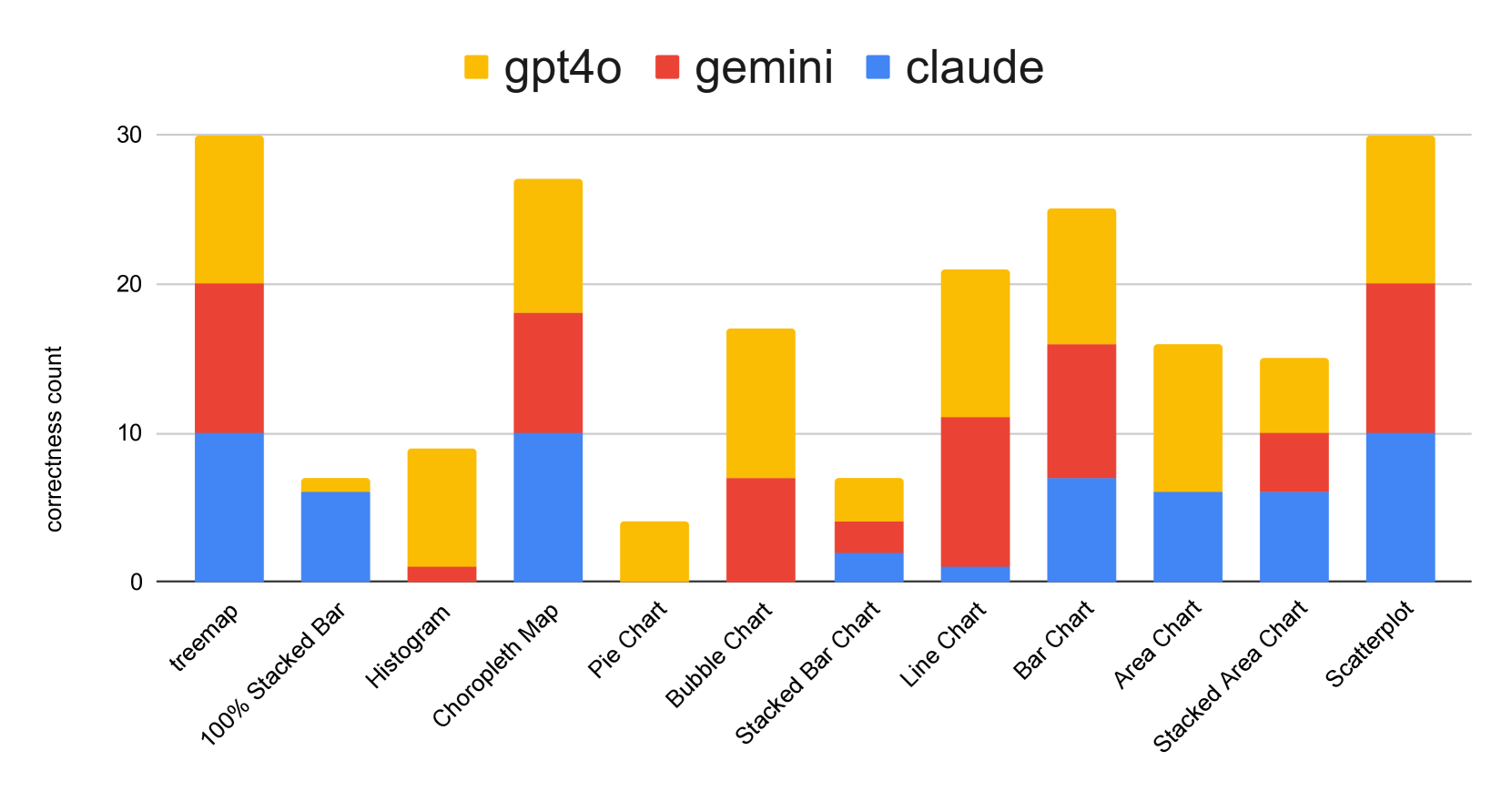
Visualization Literacy of Multimodal Large Language Models: A Comparative Study
Zhimin Li, Haichao Miao, Valerio Pascucci, Shusen Liu
The recent introduction of multimodal large language models (MLLMs) combine the inherent power of large language models (LLMs) with the renewed capabilities to reason about the multimodal context. The potential usage scenarios for MLLMs significantly outpace their text-only counterparts. Many recent works in visualization have demonstrated MLLMs' capability to understand and interpret visualization results and explain the content of the visualization to users in natural language. In the machine learning community, the general vision capabilities of MLLMs have been evaluated and tested through various visual understanding benchmarks. However, the ability of MLLMs to accomplish specific visualization tasks based on visual perception has not been properly explored and evaluated, particularly, from a visualization-centric perspective. In this work, we aim to fill the gap by utilizing the concept of visualization literacy to evaluate MLLMs. We assess MLLMs' performance over two popular visualization literacy evaluation datasets (VLAT and mini-VLAT). Under the framework of visualization literacy, we develop a general setup to compare different multimodal large language models (e.g., GPT4-o, Claude 3 Opus, Gemini 1.5 Pro) as well as against existing human baselines. Our study demonstrates MLLMs' competitive performance in visualization literacy, where they outperform humans in certain tasks such as identifying correlations, clusters, and hierarchical structures.
Read more7/17/2024