VIAssist: Adapting Multi-modal Large Language Models for Users with Visual Impairments
2404.02508
0
0
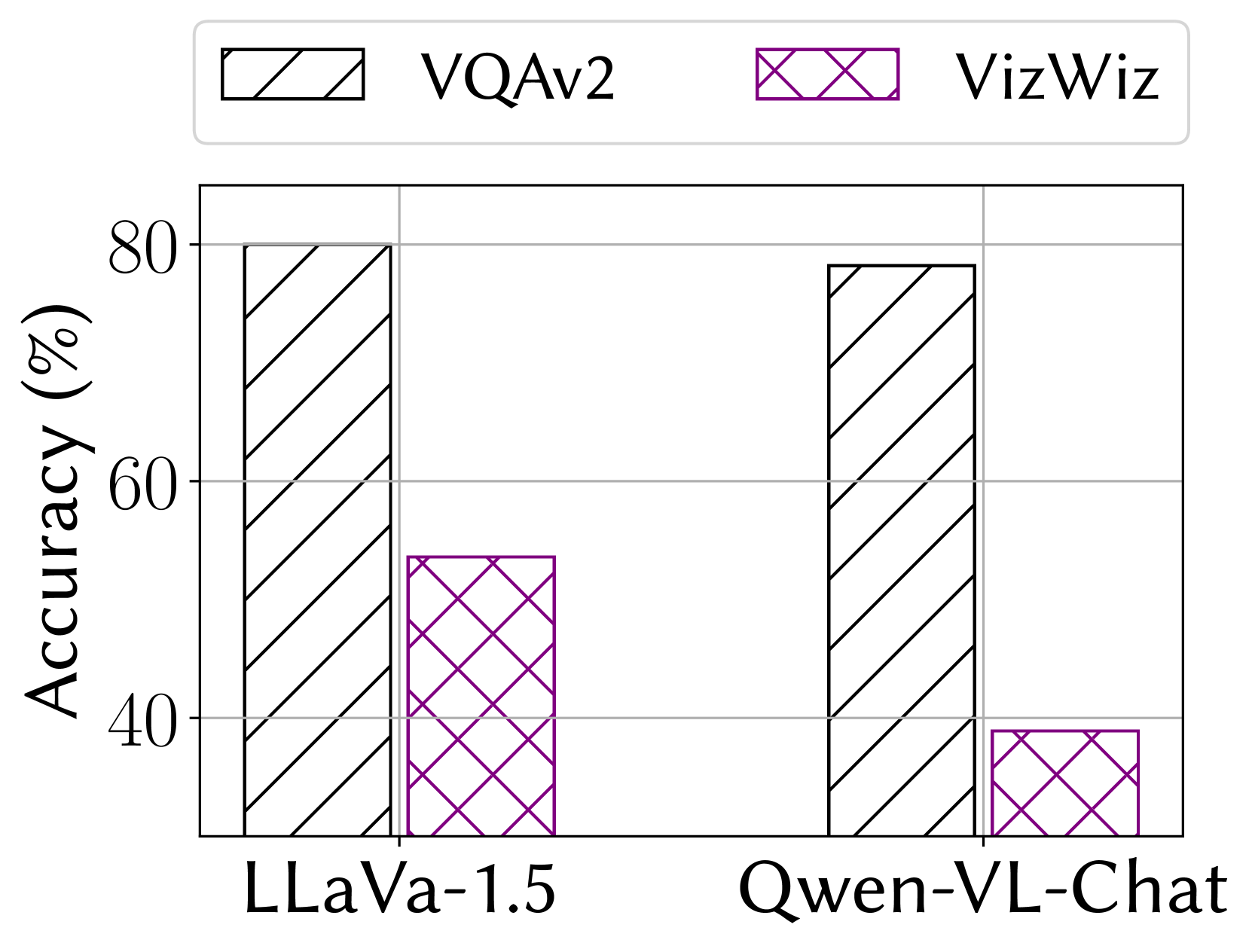
Abstract
Individuals with visual impairments, encompassing both partial and total difficulties in visual perception, are referred to as visually impaired (VI) people. An estimated 2.2 billion individuals worldwide are affected by visual impairments. Recent advancements in multi-modal large language models (MLLMs) have showcased their extraordinary capabilities across various domains. It is desirable to help VI individuals with MLLMs' great capabilities of visual understanding and reasoning. However, it is challenging for VI people to use MLLMs due to the difficulties in capturing the desirable images to fulfill their daily requests. For example, the target object is not fully or partially placed in the image. This paper explores how to leverage MLLMs for VI individuals to provide visual-question answers. VIAssist can identify undesired images and provide detailed actions. Finally, VIAssist can provide reliable answers to users' queries based on the images. Our results show that VIAssist provides +0.21 and +0.31 higher BERTScore and ROUGE scores than the baseline, respectively.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper presents VIAssist, a system that adapts multi-modal large language models (MLLMs) to assist users with visual impairments.
- The researchers explore how MLLMs can be leveraged to enhance accessibility and enable visually impaired individuals to interact with digital content more effectively.
- The proposed approach involves various techniques, including visual question answering, Internet of Things (IoT) integration, and model fine-tuning, to create a comprehensive assistive solution.
Plain English Explanation
The paper introduces VIAssist, a system designed to help people with visual impairments use digital technologies more easily. Traditional AI models struggle to understand the needs and experiences of users with visual disabilities. VIAssist aims to address this by adapting powerful language models to work better for visually impaired individuals.
The key idea is to take large, multi-purpose AI models that can process both text and images, and customize them to assist users who can't fully see the screen. This might involve enhancing the model's ability to answer questions about visual content, or integrating it with smart home devices to provide a more seamless experience.
By tailoring these advanced AI systems to the needs of people with visual impairments, the researchers hope to empower them to more effectively engage with digital information and services. The goal is to make technology more accessible and inclusive, giving visually impaired users greater independence and access to the benefits of modern computing.
Technical Explanation
The paper proposes VIAssist, a system that adapts multi-modal large language models (MLLMs) to assist users with visual impairments. MLLMs are AI models that can process both text and visual information, enabling them to understand and reason about multimedia content.
The key technical contributions of VIAssist include:
-
Visual Question Answering: The researchers fine-tune the MLLMs to excel at visual question answering, allowing visually impaired users to ask questions about images and receive detailed, informative responses.
-
IoT Integration: VIAssist integrates the adapted MLLMs with smart home devices and the Internet of Things (IoT), enabling users to control their environment and access information through voice commands and other accessible interfaces.
-
Model Customization: The paper explores techniques for further fine-tuning and customizing the MLLMs to better match the needs and preferences of users with visual impairments, improving the overall usability and effectiveness of the system.
The proposed architecture and evaluation methodology demonstrate the potential of VIAssist to enhance the digital experiences of visually impaired individuals, empowering them to engage with multimedia content and control their surrounding environment more effectively.
Critical Analysis
The paper presents a thoughtful and well-designed approach to adapting multi-modal language models for users with visual impairments. The researchers have identified a critical accessibility gap and propose a compelling solution to address it.
One potential limitation is the reliance on specific smart home devices and IoT integration, which may limit the system's broader applicability or require significant infrastructure investments. Additionally, the paper does not fully explore the challenges of ensuring the adapted models maintain high accuracy and reliability across diverse user needs and environments.
Further research could examine ways to make the VIAssist system more platform-agnostic and explore the long-term user experience implications, such as the effects on mental workload, task completion times, and user satisfaction. Investigating potential biases or ethical concerns in the underlying language models would also be a valuable area for further study.
Overall, the VIAssist approach represents a promising step towards making advanced AI technologies more accessible and inclusive for individuals with visual impairments. The researchers have demonstrated the potential of this approach and laid the groundwork for further innovations in this important domain.
Conclusion
The VIAssist system presents a innovative approach to adapting multi-modal language models to better serve users with visual impairments. By enhancing the models' visual understanding capabilities and integrating them with smart home technologies, the researchers aim to empower visually impaired individuals to more effectively engage with digital content and control their environments.
The technical contributions and evaluation methodology outlined in the paper suggest that VIAssist has the potential to significantly improve the accessibility and usability of modern computing and smart home technologies for users with visual disabilities. As AI systems become increasingly ubiquitous, this work highlights the importance of designing inclusive solutions that cater to the diverse needs of all users.
The VIAssist project represents an important step towards a more accessible and equitable digital landscape. By continuing to explore ways to adapt and customize advanced language models, the research community can work to ensure that the benefits of emerging technologies are accessible to individuals of all abilities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📈
A Multi-Modal Foundation Model to Assist People with Blindness and Low Vision in Environmental Interaction
Yu Hao, Fan Yang, Hao Huang, Shuaihang Yuan, Sundeep Rangan, John-Ross Rizzo, Yao Wang, Yi Fang
0
0
People with blindness and low vision (pBLV) encounter substantial challenges when it comes to comprehensive scene recognition and precise object identification in unfamiliar environments. Additionally, due to the vision loss, pBLV have difficulty in accessing and identifying potential tripping hazards on their own. In this paper, we present a pioneering approach that leverages a large vision-language model to enhance visual perception for pBLV, offering detailed and comprehensive descriptions of the surrounding environments and providing warnings about the potential risks. Our method begins by leveraging a large image tagging model (i.e., Recognize Anything (RAM)) to identify all common objects present in the captured images. The recognition results and user query are then integrated into a prompt, tailored specifically for pBLV using prompt engineering. By combining the prompt and input image, a large vision-language model (i.e., InstructBLIP) generates detailed and comprehensive descriptions of the environment and identifies potential risks in the environment by analyzing the environmental objects and scenes, relevant to the prompt. We evaluate our approach through experiments conducted on both indoor and outdoor datasets. Our results demonstrate that our method is able to recognize objects accurately and provide insightful descriptions and analysis of the environment for pBLV.
4/30/2024

ViP-LLaVA: Making Large Multimodal Models Understand Arbitrary Visual Prompts
Mu Cai, Haotian Liu, Dennis Park, Siva Karthik Mustikovela, Gregory P. Meyer, Yuning Chai, Yong Jae Lee
0
0
While existing large vision-language multimodal models focus on whole image understanding, there is a prominent gap in achieving region-specific comprehension. Current approaches that use textual coordinates or spatial encodings often fail to provide a user-friendly interface for visual prompting. To address this challenge, we introduce a novel multimodal model capable of decoding arbitrary visual prompts. This allows users to intuitively mark images and interact with the model using natural cues like a red bounding box or pointed arrow. Our simple design directly overlays visual markers onto the RGB image, eliminating the need for complex region encodings, yet achieves state-of-the-art performance on region-understanding tasks like Visual7W, PointQA, and Visual Commonsense Reasoning benchmark. Furthermore, we present ViP-Bench, a comprehensive benchmark to assess the capability of models in understanding visual prompts across multiple dimensions, enabling future research in this domain. Code, data, and model are publicly available.
4/30/2024

Exploring the Frontier of Vision-Language Models: A Survey of Current Methodologies and Future Directions
Akash Ghosh, Arkadeep Acharya, Sriparna Saha, Vinija Jain, Aman Chadha
0
0
The advent of Large Language Models (LLMs) has significantly reshaped the trajectory of the AI revolution. Nevertheless, these LLMs exhibit a notable limitation, as they are primarily adept at processing textual information. To address this constraint, researchers have endeavored to integrate visual capabilities with LLMs, resulting in the emergence of Vision-Language Models (VLMs). These advanced models are instrumental in tackling more intricate tasks such as image captioning and visual question answering. In our comprehensive survey paper, we delve into the key advancements within the realm of VLMs. Our classification organizes VLMs into three distinct categories: models dedicated to vision-language understanding, models that process multimodal inputs to generate unimodal (textual) outputs and models that both accept and produce multimodal inputs and outputs.This classification is based on their respective capabilities and functionalities in processing and generating various modalities of data.We meticulously dissect each model, offering an extensive analysis of its foundational architecture, training data sources, as well as its strengths and limitations wherever possible, providing readers with a comprehensive understanding of its essential components. We also analyzed the performance of VLMs in various benchmark datasets. By doing so, we aim to offer a nuanced understanding of the diverse landscape of VLMs. Additionally, we underscore potential avenues for future research in this dynamic domain, anticipating further breakthroughs and advancements.
4/16/2024
🖼️
Enhancing Interactive Image Retrieval With Query Rewriting Using Large Language Models and Vision Language Models
Hongyi Zhu, Jia-Hong Huang, Stevan Rudinac, Evangelos Kanoulas
0
0
Image search stands as a pivotal task in multimedia and computer vision, finding applications across diverse domains, ranging from internet search to medical diagnostics. Conventional image search systems operate by accepting textual or visual queries, retrieving the top-relevant candidate results from the database. However, prevalent methods often rely on single-turn procedures, introducing potential inaccuracies and limited recall. These methods also face the challenges, such as vocabulary mismatch and the semantic gap, constraining their overall effectiveness. To address these issues, we propose an interactive image retrieval system capable of refining queries based on user relevance feedback in a multi-turn setting. This system incorporates a vision language model (VLM) based image captioner to enhance the quality of text-based queries, resulting in more informative queries with each iteration. Moreover, we introduce a large language model (LLM) based denoiser to refine text-based query expansions, mitigating inaccuracies in image descriptions generated by captioning models. To evaluate our system, we curate a new dataset by adapting the MSR-VTT video retrieval dataset to the image retrieval task, offering multiple relevant ground truth images for each query. Through comprehensive experiments, we validate the effectiveness of our proposed system against baseline methods, achieving state-of-the-art performance with a notable 10% improvement in terms of recall. Our contributions encompass the development of an innovative interactive image retrieval system, the integration of an LLM-based denoiser, the curation of a meticulously designed evaluation dataset, and thorough experimental validation.
4/30/2024