GenVideo: One-shot Target-image and Shape Aware Video Editing using T2I Diffusion Models

0
Sign in to get full access
Overview
- This paper introduces GenVideo, a novel one-shot video editing system that leverages text-to-image (T2I) diffusion models to enable target-image and shape-aware video editing.
- GenVideo allows users to edit videos by providing a single reference image, without the need for complex video editing tools or extensive training data.
- The system can perform a variety of video editing tasks, such as object insertion, scene replacement, and style transfer, while preserving the original video's spatial and temporal coherence.
Plain English Explanation
GenVideo: One-shot target-image and shape aware video editing using T2I diffusion models is a new video editing tool that makes it easy to modify videos using just a single reference image. Instead of having to use complex video editing software or provide lots of training data, GenVideo allows you to make changes to a video by providing a single example image.
For instance, you could take a video of a park and replace the trees with images of cherry blossoms, or insert a new object like a hot air balloon into the scene. GenVideo is able to do this while still keeping the video looking natural and coherent, preserving the original spatial layout and timing of the footage.
This is possible because GenVideo uses a special type of AI model called a "text-to-image diffusion model." These models can generate images from text descriptions, and GenVideo has found a way to adapt them to work with videos as well. By using just a single reference image, GenVideo can figure out how to modify the video to match that image, without needing extensive training data or manual editing.
The key innovation in GenVideo is its ability to understand the spatial and temporal relationships in a video, so that the edits it makes look natural and integrated into the scene. This sets it apart from previous video editing tools that often struggled to maintain coherence when making significant changes.
Overall, GenVideo aims to make video editing much more accessible and flexible, allowing users to easily customize their videos without needing specialized skills or tools. This could open up new creative possibilities forvideo editing and video generation, beyond what is possible with traditional approaches.
Technical Explanation
GenVideo is a novel one-shot video editing system that leverages text-to-image (T2I) diffusion models to enable target-image and shape-aware video editing. The key innovation of GenVideo is its ability to preserve the spatial and temporal coherence of the original video when making significant edits, such as object insertion, scene replacement, and style transfer.
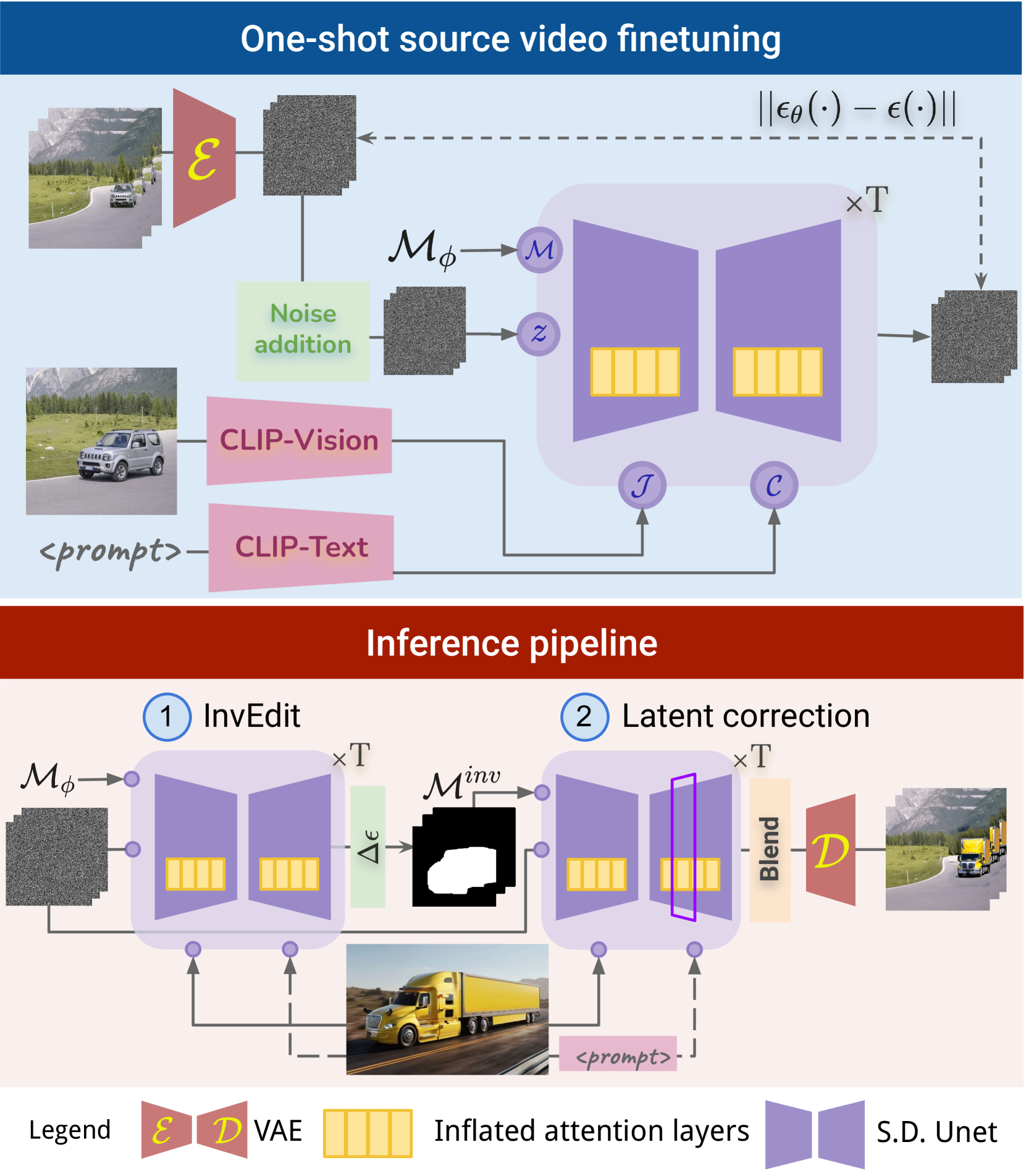
The system works by first encoding the input video into a latent representation using a convolutional neural network. It then uses a T2I diffusion model to generate a new latent representation that matches a provided reference image. This new latent is then combined with the original video latent using a spatiotemporal attention mechanism to produce the final edited video.
The spatiotemporal attention module is crucial, as it allows GenVideo to understand the 3D structure and motion of the original video and seamlessly integrate the new content. This ensures that the edits blend naturally with the existing scene and maintain temporal coherence.
GenVideo was evaluated on a range of video editing tasks, demonstrating its flexibility and effectiveness compared to prior video editing and video generation approaches. The results show that GenVideo can produce high-quality edited videos from a single reference image, without requiring complex editing tools or extensive training data.
Critical Analysis
The GenVideo paper presents a promising approach for one-shot video editing, but there are a few potential limitations and areas for further research:
One key limitation is that the system currently only supports a fixed number of editing operations, such as object insertion, scene replacement, and style transfer. Expanding the capabilities to handle a wider range of editing tasks could further enhance the system's versatility.
Additionally, while GenVideo aims to preserve spatial and temporal coherence, there may be cases where the edits still appear unnatural or jarring to the viewer. Improving the spatiotemporal understanding and integration of new content could help address this issue.
Another area for improvement is the system's reliance on a single reference image. Allowing users to provide additional context, such as textual descriptions or multiple reference images, could potentially lead to more nuanced and personalized edits.
Overall, GenVideo represents an exciting step forward in making video editing more accessible and flexible. By leveraging the power of diffusion models, the system demonstrates the potential for AI-driven tools to revolutionize creative workflows. Continued research and development in this area could yield even more advanced and user-friendly video editing capabilities.
Conclusion
GenVideo is a novel one-shot video editing system that uses text-to-image diffusion models to enable target-image and shape-aware video editing. The key innovation is its ability to preserve the spatial and temporal coherence of the original video when making significant edits, such as object insertion, scene replacement, and style transfer.
This approach represents an exciting development in the field of video editing, as it has the potential to make video customization and creative expression more accessible to a wider audience. By leveraging the power of AI models, GenVideo demonstrates how emerging technologies can be harnessed to revolutionize traditional creative workflows.
While the current system has some limitations, the critical analysis suggests that further research and development in this area could yield even more advanced and user-friendly video editing capabilities. As the field of AI-assisted content creation continues to evolve, tools like GenVideo may become increasingly important for unlocking new creative possibilities and empowering users to bring their visions to life.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
GenVideo: One-shot Target-image and Shape Aware Video Editing using T2I Diffusion Models
Sai Sree Harsha, Ambareesh Revanur, Dhwanit Agarwal, Shradha Agrawal
Video editing methods based on diffusion models that rely solely on a text prompt for the edit are hindered by the limited expressive power of text prompts. Thus, incorporating a reference target image as a visual guide becomes desirable for precise control over edit. Also, most existing methods struggle to accurately edit a video when the shape and size of the object in the target image differ from the source object. To address these challenges, we propose GenVideo for editing videos leveraging target-image aware T2I models. Our approach handles edits with target objects of varying shapes and sizes while maintaining the temporal consistency of the edit using our novel target and shape aware InvEdit masks. Further, we propose a novel target-image aware latent noise correction strategy during inference to improve the temporal consistency of the edits. Experimental analyses indicate that GenVideo can effectively handle edits with objects of varying shapes, where existing approaches fail.
Read more4/22/2024

0
I2VEdit: First-Frame-Guided Video Editing via Image-to-Video Diffusion Models
Wenqi Ouyang, Yi Dong, Lei Yang, Jianlou Si, Xingang Pan
The remarkable generative capabilities of diffusion models have motivated extensive research in both image and video editing. Compared to video editing which faces additional challenges in the time dimension, image editing has witnessed the development of more diverse, high-quality approaches and more capable software like Photoshop. In light of this gap, we introduce a novel and generic solution that extends the applicability of image editing tools to videos by propagating edits from a single frame to the entire video using a pre-trained image-to-video model. Our method, dubbed I2VEdit, adaptively preserves the visual and motion integrity of the source video depending on the extent of the edits, effectively handling global edits, local edits, and moderate shape changes, which existing methods cannot fully achieve. At the core of our method are two main processes: Coarse Motion Extraction to align basic motion patterns with the original video, and Appearance Refinement for precise adjustments using fine-grained attention matching. We also incorporate a skip-interval strategy to mitigate quality degradation from auto-regressive generation across multiple video clips. Experimental results demonstrate our framework's superior performance in fine-grained video editing, proving its capability to produce high-quality, temporally consistent outputs.
Read more5/28/2024

0
A Survey of Multimodal-Guided Image Editing with Text-to-Image Diffusion Models
Xincheng Shuai, Henghui Ding, Xingjun Ma, Rongcheng Tu, Yu-Gang Jiang, Dacheng Tao
Image editing aims to edit the given synthetic or real image to meet the specific requirements from users. It is widely studied in recent years as a promising and challenging field of Artificial Intelligence Generative Content (AIGC). Recent significant advancement in this field is based on the development of text-to-image (T2I) diffusion models, which generate images according to text prompts. These models demonstrate remarkable generative capabilities and have become widely used tools for image editing. T2I-based image editing methods significantly enhance editing performance and offer a user-friendly interface for modifying content guided by multimodal inputs. In this survey, we provide a comprehensive review of multimodal-guided image editing techniques that leverage T2I diffusion models. First, we define the scope of image editing from a holistic perspective and detail various control signals and editing scenarios. We then propose a unified framework to formalize the editing process, categorizing it into two primary algorithm families. This framework offers a design space for users to achieve specific goals. Subsequently, we present an in-depth analysis of each component within this framework, examining the characteristics and applicable scenarios of different combinations. Given that training-based methods learn to directly map the source image to target one under user guidance, we discuss them separately, and introduce injection schemes of source image in different scenarios. Additionally, we review the application of 2D techniques to video editing, highlighting solutions for inter-frame inconsistency. Finally, we discuss open challenges in the field and suggest potential future research directions. We keep tracing related works at https://github.com/xinchengshuai/Awesome-Image-Editing.
Read more6/21/2024

0
Slicedit: Zero-Shot Video Editing With Text-to-Image Diffusion Models Using Spatio-Temporal Slices
Nathaniel Cohen, Vladimir Kulikov, Matan Kleiner, Inbar Huberman-Spiegelglas, Tomer Michaeli
Text-to-image (T2I) diffusion models achieve state-of-the-art results in image synthesis and editing. However, leveraging such pretrained models for video editing is considered a major challenge. Many existing works attempt to enforce temporal consistency in the edited video through explicit correspondence mechanisms, either in pixel space or between deep features. These methods, however, struggle with strong nonrigid motion. In this paper, we introduce a fundamentally different approach, which is based on the observation that spatiotemporal slices of natural videos exhibit similar characteristics to natural images. Thus, the same T2I diffusion model that is normally used only as a prior on video frames, can also serve as a strong prior for enhancing temporal consistency by applying it on spatiotemporal slices. Based on this observation, we present Slicedit, a method for text-based video editing that utilizes a pretrained T2I diffusion model to process both spatial and spatiotemporal slices. Our method generates videos that retain the structure and motion of the original video while adhering to the target text. Through extensive experiments, we demonstrate Slicedit's ability to edit a wide range of real-world videos, confirming its clear advantages compared to existing competing methods. Webpage: https://matankleiner.github.io/slicedit/
Read more5/21/2024