Video Emotion Open-vocabulary Recognition Based on Multimodal Large Language Model

0
👁️
Sign in to get full access
Overview
- Develops a multimodal large language model for open-vocabulary video emotion recognition
- Leverages cross-modal interactions to enable zero-shot and few-shot learning
- Outperforms state-of-the-art methods on multiple video emotion recognition benchmarks
Plain English Explanation
This paper presents a new approach to video emotion recognition that uses a multimodal large language model. The key idea is to capture the complex relationships between visual, textual, and audio cues to enable more accurate and flexible emotion recognition, even for concepts not seen during training.
The model is trained on a large, diverse dataset that includes video clips, associated text descriptions, and emotion labels. By learning the connections between these different modalities, the model can leverage cross-modal interactions to recognize emotions in new videos, even if the specific emotions or concepts have not been encountered before (zero-shot and few-shot learning).
Compared to previous approaches, this multimodal large language model-based method achieves state-of-the-art performance on several standard video emotion recognition benchmarks. The authors argue that this flexible, open-vocabulary approach represents an important step forward for practical emotion recognition systems, which often need to handle a wide range of emotional expressions in real-world scenarios.
Technical Explanation
The proposed method is built around a multimodal large language model that jointly encodes video, text, and audio inputs. The model consists of separate transformer-based encoders for each modality, which are then combined through cross-attention and fusion layers to capture multimodal interactions.
During training, the model is exposed to a large dataset of video clips, associated text descriptions, and emotion labels. By learning to predict the emotion labels given the multimodal inputs, the model develops an understanding of how visual, textual, and audio cues relate to different emotional states.
This multimodal learning approach enables the model to generalize to new, unseen emotions through zero-shot and few-shot learning. When presented with a video depicting an unfamiliar emotion, the model can leverage its knowledge of related concepts and cross-modal associations to make an informed prediction.
The authors evaluate their approach on several benchmark datasets for video emotion recognition, including EMOTIC, AFEW, and EmotiW. The results show that the multimodal large language model outperforms state-of-the-art methods, demonstrating the benefits of its open-vocabulary and cross-modal learning capabilities.
Critical Analysis
The paper introduces a promising approach to video emotion recognition that leverages the power of multimodal large language models. By capturing the complex relationships between visual, textual, and audio cues, the model is able to achieve strong performance, even on unseen emotional concepts.
However, the paper does not provide a deep analysis of the model's limitations or potential failure cases. For example, it would be interesting to understand how the model's performance degrades as the emotional complexity or ambiguity of the video increases. Additionally, the authors could explore the interpretability of the model's predictions and investigate whether the cross-modal associations learned by the model align with human intuitions about emotional expression.
Further research could also investigate the model's robustness to noise, semi-supervised learning techniques, and the potential to extend the approach to versatile audio-visual emotion recognition scenarios.
Conclusion
This paper presents a novel approach to video emotion recognition that leverages a multimodal large language model to capture the rich interplay between visual, textual, and audio cues. By enabling open-vocabulary and few-shot learning, the proposed method outperforms state-of-the-art techniques on several benchmark datasets.
The model's strong performance and flexibility suggest that this type of multimodal approach could be a valuable tool for practical emotion recognition systems, which often need to handle a wide range of emotional expressions in real-world scenarios. Further research exploring the model's limitations and potential extensions could lead to even more powerful and versatile emotion recognition capabilities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👁️
0
Video Emotion Open-vocabulary Recognition Based on Multimodal Large Language Model
Mengying Ge, Dongkai Tang, Mingyang Li
Multimodal emotion recognition is a task of great concern. However, traditional data sets are based on fixed labels, resulting in models that often focus on main emotions and ignore detailed emotional changes in complex scenes. This report introduces the solution of using MLLMs technology to generate open-vocabulary emotion labels from a video. The solution includes the use of framework, data generation and processing, training methods, results generation and multi-model co-judgment. In the MER-OV (Open-Word Emotion Recognition) of the MER2024 challenge, our method achieved significant advantages, leading to its superior capabilities in complex emotion computation.
Read more8/23/2024
0
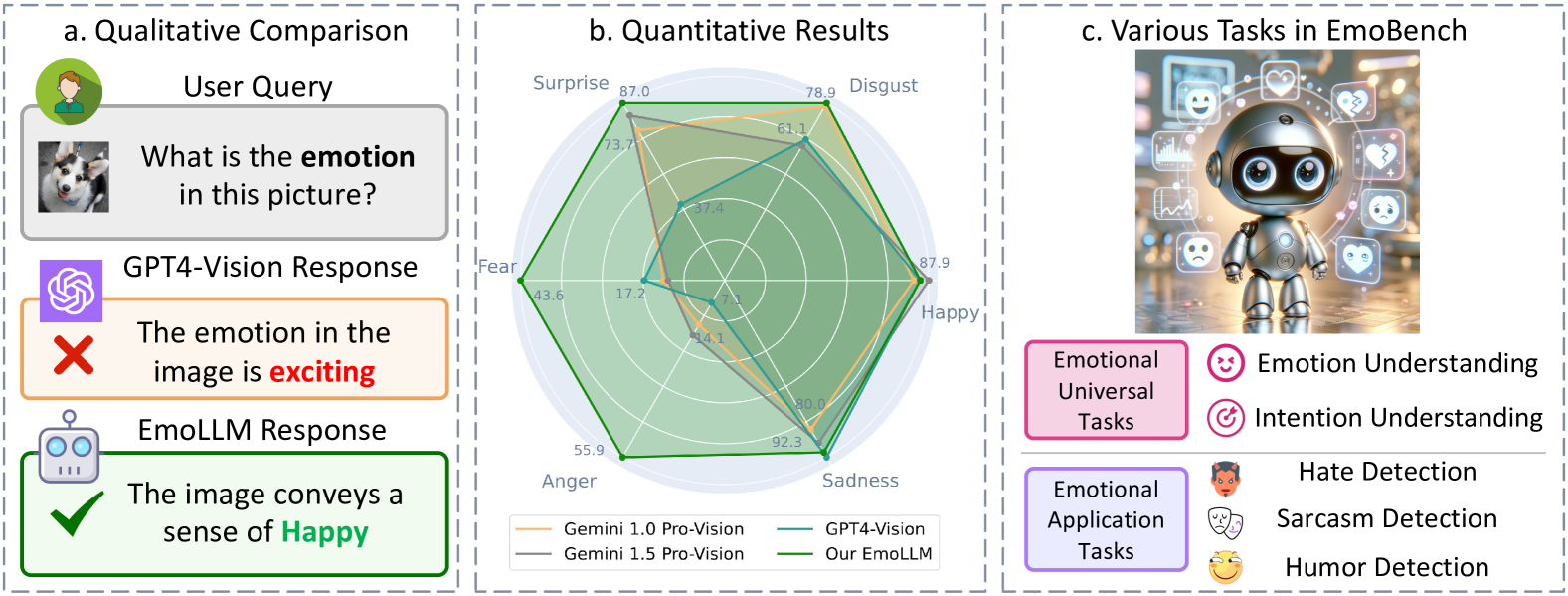
EmoLLM: Multimodal Emotional Understanding Meets Large Language Models
Qu Yang, Mang Ye, Bo Du
Multi-modal large language models (MLLMs) have achieved remarkable performance on objective multimodal perception tasks, but their ability to interpret subjective, emotionally nuanced multimodal content remains largely unexplored. Thus, it impedes their ability to effectively understand and react to the intricate emotions expressed by humans through multimodal media. To bridge this gap, we introduce EmoBench, the first comprehensive benchmark designed specifically to evaluate the emotional capabilities of MLLMs across five popular emotional tasks, using a diverse dataset of 287k images and videos paired with corresponding textual instructions. Meanwhile, we propose EmoLLM, a novel model for multimodal emotional understanding, incorporating with two core techniques. 1) Multi-perspective Visual Projection, it captures diverse emotional cues from visual data from multiple perspectives. 2) EmoPrompt, it guides MLLMs to reason about emotions in the correct direction. Experimental results demonstrate that EmoLLM significantly elevates multimodal emotional understanding performance, with an average improvement of 12.1% across multiple foundation models on EmoBench. Our work contributes to the advancement of MLLMs by facilitating a deeper and more nuanced comprehension of intricate human emotions, paving the way for the development of artificial emotional intelligence capabilities with wide-ranging applications in areas such as human-computer interaction, mental health support, and empathetic AI systems. Code, data, and model will be released.
Read more7/2/2024
0
Emotion-LLaMA: Multimodal Emotion Recognition and Reasoning with Instruction Tuning
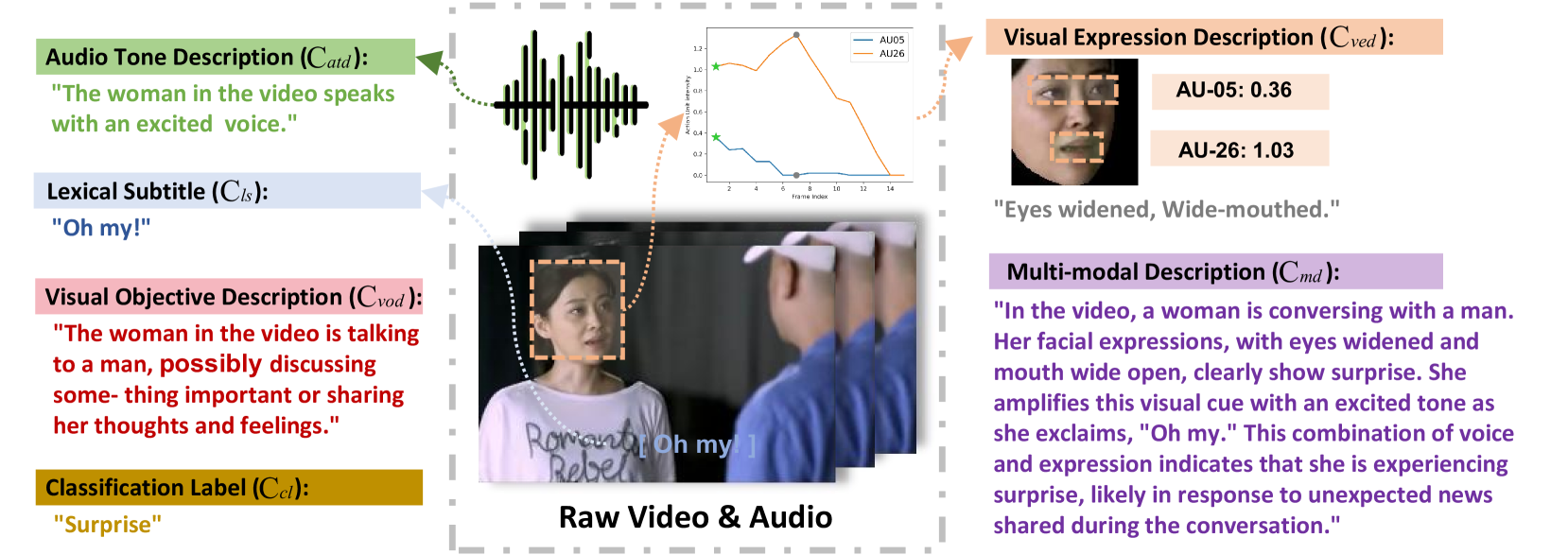
Zebang Cheng, Zhi-Qi Cheng, Jun-Yan He, Jingdong Sun, Kai Wang, Yuxiang Lin, Zheng Lian, Xiaojiang Peng, Alexander Hauptmann
Accurate emotion perception is crucial for various applications, including human-computer interaction, education, and counseling. However, traditional single-modality approaches often fail to capture the complexity of real-world emotional expressions, which are inherently multimodal. Moreover, existing Multimodal Large Language Models (MLLMs) face challenges in integrating audio and recognizing subtle facial micro-expressions. To address this, we introduce the MERR dataset, containing 28,618 coarse-grained and 4,487 fine-grained annotated samples across diverse emotional categories. This dataset enables models to learn from varied scenarios and generalize to real-world applications. Furthermore, we propose Emotion-LLaMA, a model that seamlessly integrates audio, visual, and textual inputs through emotion-specific encoders. By aligning features into a shared space and employing a modified LLaMA model with instruction tuning, Emotion-LLaMA significantly enhances both emotional recognition and reasoning capabilities. Extensive evaluations show Emotion-LLaMA outperforms other MLLMs, achieving top scores in Clue Overlap (7.83) and Label Overlap (6.25) on EMER, an F1 score of 0.9036 on MER2023 challenge, and the highest UAR (45.59) and WAR (59.37) in zero-shot evaluations on DFEW dataset.
Read more6/18/2024
0
MER 2024: Semi-Supervised Learning, Noise Robustness, and Open-Vocabulary Multimodal Emotion Recognition
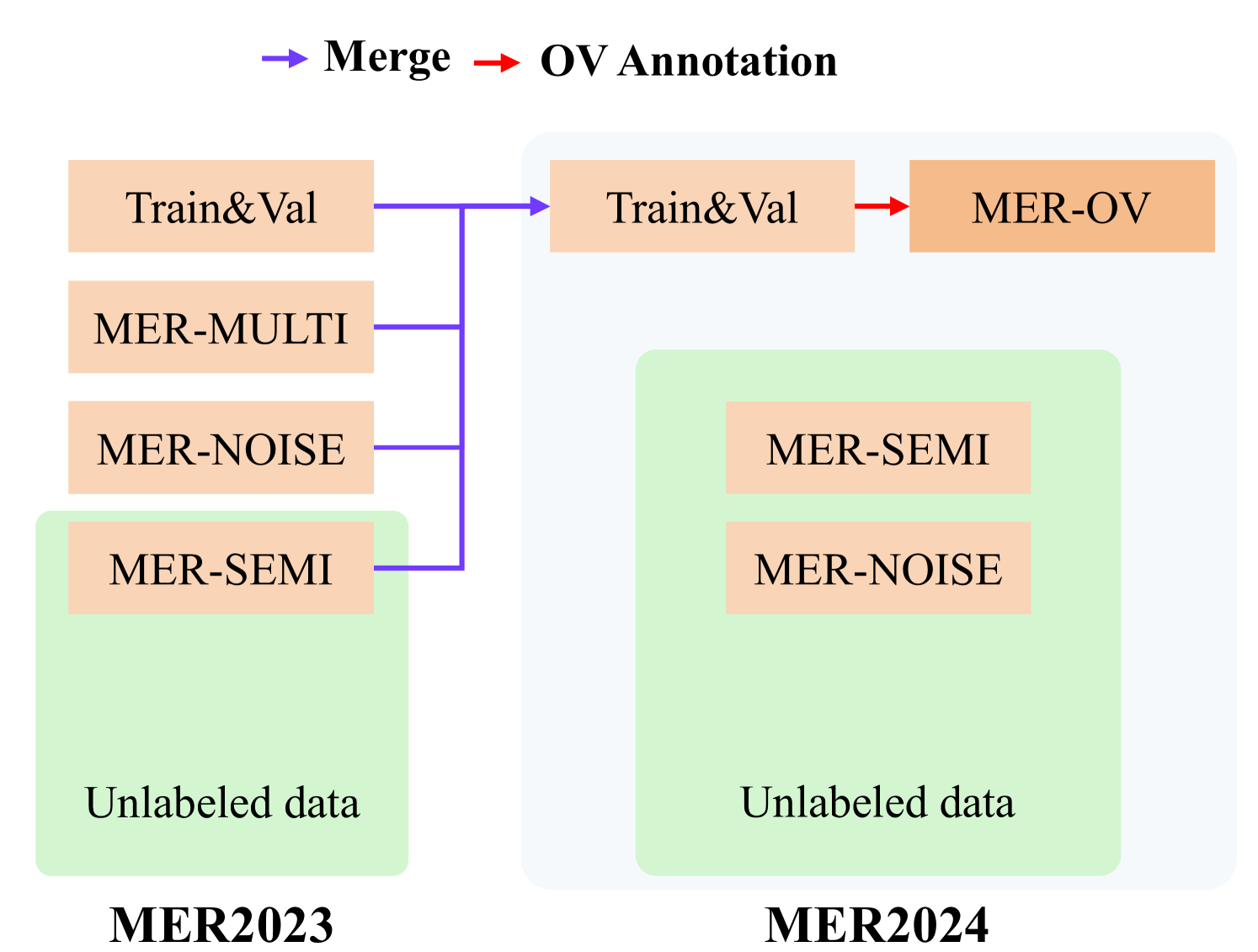
Zheng Lian, Haiyang Sun, Licai Sun, Zhuofan Wen, Siyuan Zhang, Shun Chen, Hao Gu, Jinming Zhao, Ziyang Ma, Xie Chen, Jiangyan Yi, Rui Liu, Kele Xu, Bin Liu, Erik Cambria, Guoying Zhao, Bjorn W. Schuller, Jianhua Tao
Multimodal emotion recognition is an important research topic in artificial intelligence. Over the past few decades, researchers have made remarkable progress by increasing the dataset size and building more effective algorithms. However, due to problems such as complex environments and inaccurate annotations, current systems are hard to meet the demands of practical applications. Therefore, we organize the MER series of competitions to promote the development of this field. Last year, we launched MER2023, focusing on three interesting topics: multi-label learning, noise robustness, and semi-supervised learning. In this year's MER2024, besides expanding the dataset size, we further introduce a new track around open-vocabulary emotion recognition. The main purpose of this track is that existing datasets usually fix the label space and use majority voting to enhance the annotator consistency. However, this process may lead to inaccurate annotations, such as ignoring non-majority or non-candidate labels. In this track, we encourage participants to generate any number of labels in any category, aiming to describe emotional states as accurately as possible. Our baseline code relies on MERTools and is available at: https://github.com/zeroQiaoba/MERTools/tree/master/MER2024.
Read more7/19/2024