Multimodal Emotion Recognition by Fusing Video Semantic in MOOC Learning Scenarios
2404.07484
0
0
👁️
Abstract
In the Massive Open Online Courses (MOOC) learning scenario, the semantic information of instructional videos has a crucial impact on learners' emotional state. Learners mainly acquire knowledge by watching instructional videos, and the semantic information in the videos directly affects learners' emotional states. However, few studies have paid attention to the potential influence of the semantic information of instructional videos on learners' emotional states. To deeply explore the impact of video semantic information on learners' emotions, this paper innovatively proposes a multimodal emotion recognition method by fusing video semantic information and physiological signals. We generate video descriptions through a pre-trained large language model (LLM) to obtain high-level semantic information about instructional videos. Using the cross-attention mechanism for modal interaction, the semantic information is fused with the eye movement and PhotoPlethysmoGraphy (PPG) signals to obtain the features containing the critical information of the three modes. The accurate recognition of learners' emotional states is realized through the emotion classifier. The experimental results show that our method has significantly improved emotion recognition performance, providing a new perspective and efficient method for emotion recognition research in MOOC learning scenarios. The method proposed in this paper not only contributes to a deeper understanding of the impact of instructional videos on learners' emotional states but also provides a beneficial reference for future research on emotion recognition in MOOC learning scenarios.
Create account to get full access
Overview
- This paper explores the impact of the semantic information in instructional videos on learners' emotional states in Massive Open Online Courses (MOOCs).
- The researchers propose a multimodal emotion recognition method that combines video semantic information, eye movement, and PhotoPlethysmoGraphy (PPG) signals to better understand learners' emotional states.
- The experiment results show that this approach significantly improves emotion recognition performance, providing a new perspective and efficient method for emotion recognition research in MOOC learning scenarios.
Plain English Explanation
In MOOC learning, the information conveyed in instructional videos has a crucial impact on how students feel. Students primarily learn by watching these videos, and the content of the videos directly affects their emotional state. However, few studies have looked at how the semantic information in the videos influences students' emotions.
To better understand this relationship, the researchers developed a new method that combines different types of information to recognize students' emotions. They used a pre-trained language model to analyze the content of the videos and extract high-level semantic information. They then combined this information with data from students' eye movements and heart rate (measured by PPG) to get a more complete picture of their emotional state.
The experiment results show that this multimodal approach is much better at recognizing students' emotions compared to previous methods. This provides a new way to understand how the content of instructional videos affects how students feel, which is important for improving the MOOC learning experience.
Technical Explanation
The researchers propose a multimodal emotion recognition method that fuses video semantic information and physiological signals to better understand learners' emotional states in MOOC scenarios.
They use a pre-trained large language model (LLM) to generate video descriptions and obtain high-level semantic information about the instructional videos. This semantic information is then fused with eye movement and PPG signals using a cross-attention mechanism to capture the critical information from the three modalities.
The combined features are used to train an emotion classifier, which is able to accurately recognize learners' emotional states. The experimental results demonstrate that this multimodal approach significantly outperforms previous emotion recognition methods in MOOC scenarios.
Critical Analysis
The paper provides a novel and promising approach to understanding the impact of instructional video content on learners' emotions in MOOC environments. However, the researchers acknowledge some limitations of their work.
First, the study was conducted in a controlled laboratory setting, so the generalizability to real-world MOOC scenarios may be limited. Further research is needed to validate the approach in more natural learning environments.
Additionally, the paper does not explore the specific mechanisms by which video semantic information influences emotional states. More investigation is required to unpack these underlying processes.
Finally, the emotion recognition model was trained and evaluated on a relatively small dataset. Expanding the dataset size and diversity could improve the model's robustness and generalization capabilities.
Despite these caveats, the research represents an important step forward in leveraging multimodal data to gain deeper insights into the emotional experiences of MOOC learners. The findings could inform the design of more engaging and effective instructional videos.
Conclusion
This paper presents a innovative multimodal emotion recognition method that fuses video semantic information, eye movement, and PPG signals to better understand learners' emotional states in MOOC learning scenarios. The experimental results demonstrate the effectiveness of this approach, providing a new perspective and efficient technique for emotion recognition research in MOOC contexts.
The findings have significant implications for improving the quality of instructional videos and enhancing the overall MOOC learning experience. By understanding how the semantic content of videos impacts learners' emotions, instructors and platform developers can create more engaging and impactful educational materials.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Emotion-LLaMA: Multimodal Emotion Recognition and Reasoning with Instruction Tuning
Zebang Cheng, Zhi-Qi Cheng, Jun-Yan He, Jingdong Sun, Kai Wang, Yuxiang Lin, Zheng Lian, Xiaojiang Peng, Alexander Hauptmann
0
0
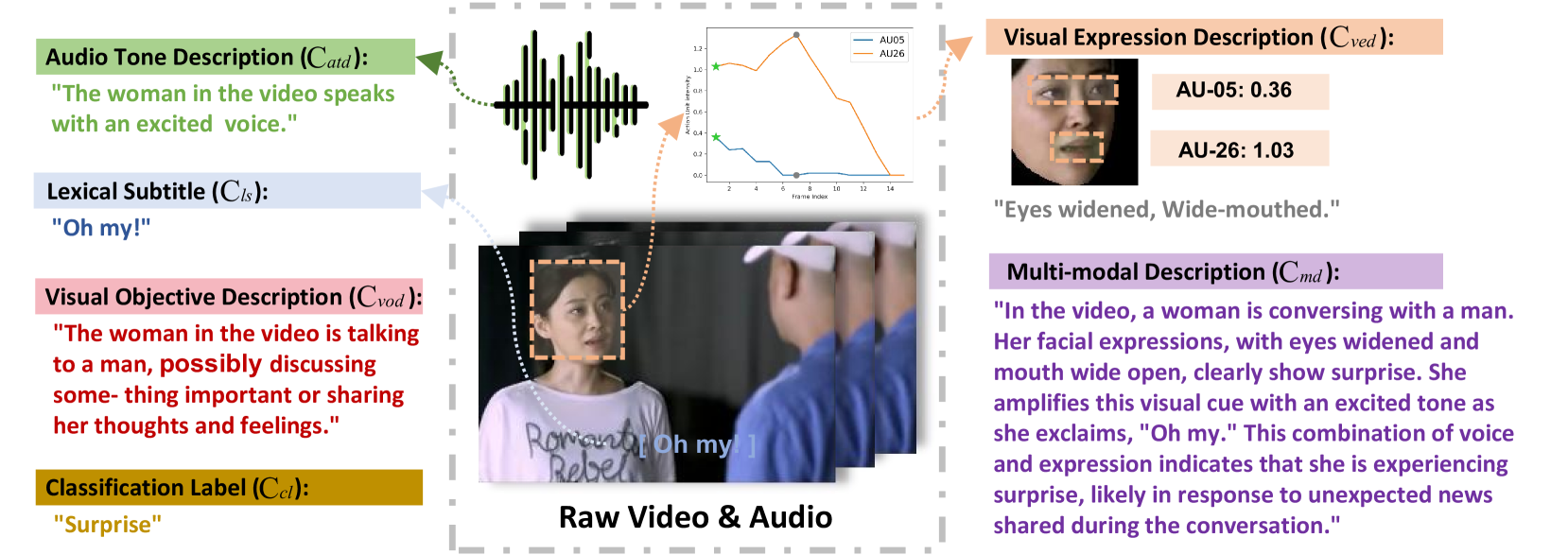
Accurate emotion perception is crucial for various applications, including human-computer interaction, education, and counseling. However, traditional single-modality approaches often fail to capture the complexity of real-world emotional expressions, which are inherently multimodal. Moreover, existing Multimodal Large Language Models (MLLMs) face challenges in integrating audio and recognizing subtle facial micro-expressions. To address this, we introduce the MERR dataset, containing 28,618 coarse-grained and 4,487 fine-grained annotated samples across diverse emotional categories. This dataset enables models to learn from varied scenarios and generalize to real-world applications. Furthermore, we propose Emotion-LLaMA, a model that seamlessly integrates audio, visual, and textual inputs through emotion-specific encoders. By aligning features into a shared space and employing a modified LLaMA model with instruction tuning, Emotion-LLaMA significantly enhances both emotional recognition and reasoning capabilities. Extensive evaluations show Emotion-LLaMA outperforms other MLLMs, achieving top scores in Clue Overlap (7.83) and Label Overlap (6.25) on EMER, an F1 score of 0.9036 on MER2023 challenge, and the highest UAR (45.59) and WAR (59.37) in zero-shot evaluations on DFEW dataset.
6/18/2024
Dynamic Modality and View Selection for Multimodal Emotion Recognition with Missing Modalities
Luciana Trinkaus Menon, Luiz Carlos Ribeiro Neduziak, Jean Paul Barddal, Alessandro Lameiras Koerich, Alceu de Souza Britto Jr
0
0
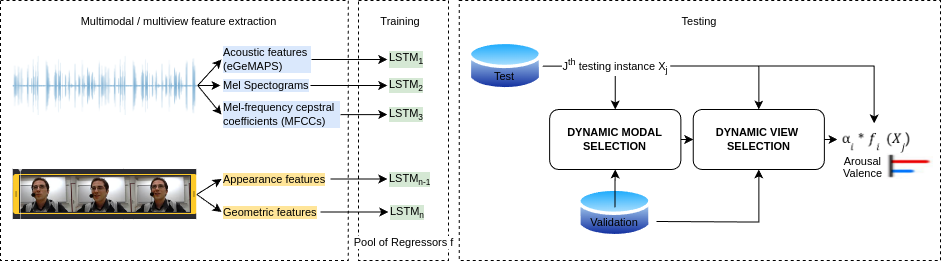
The study of human emotions, traditionally a cornerstone in fields like psychology and neuroscience, has been profoundly impacted by the advent of artificial intelligence (AI). Multiple channels, such as speech (voice) and facial expressions (image), are crucial in understanding human emotions. However, AI's journey in multimodal emotion recognition (MER) is marked by substantial technical challenges. One significant hurdle is how AI models manage the absence of a particular modality - a frequent occurrence in real-world situations. This study's central focus is assessing the performance and resilience of two strategies when confronted with the lack of one modality: a novel multimodal dynamic modality and view selection and a cross-attention mechanism. Results on the RECOLA dataset show that dynamic selection-based methods are a promising approach for MER. In the missing modalities scenarios, all dynamic selection-based methods outperformed the baseline. The study concludes by emphasizing the intricate interplay between audio and video modalities in emotion prediction, showcasing the adaptability of dynamic selection methods in handling missing modalities.
4/19/2024
EmoLLM: Multimodal Emotional Understanding Meets Large Language Models
Qu Yang, Mang Ye, Bo Du
0
0
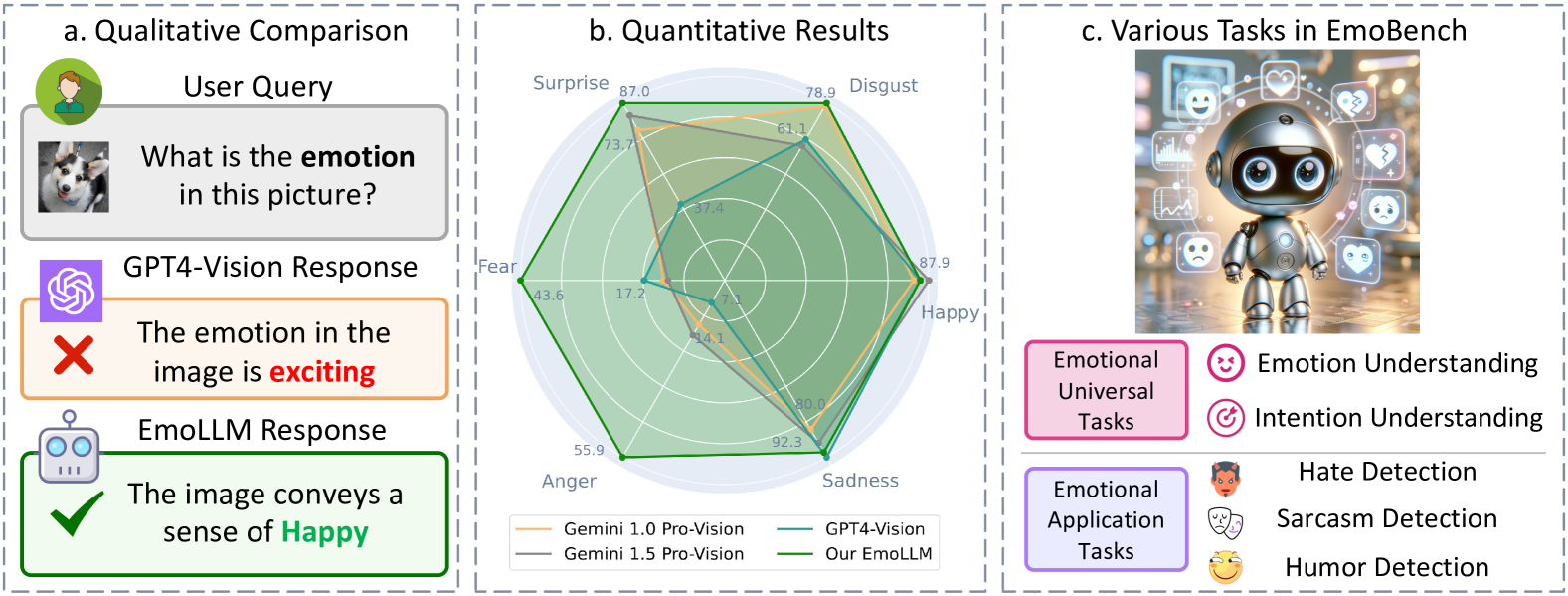
Multi-modal large language models (MLLMs) have achieved remarkable performance on objective multimodal perception tasks, but their ability to interpret subjective, emotionally nuanced multimodal content remains largely unexplored. Thus, it impedes their ability to effectively understand and react to the intricate emotions expressed by humans through multimodal media. To bridge this gap, we introduce EmoBench, the first comprehensive benchmark designed specifically to evaluate the emotional capabilities of MLLMs across five popular emotional tasks, using a diverse dataset of 287k images and videos paired with corresponding textual instructions. Meanwhile, we propose EmoLLM, a novel model for multimodal emotional understanding, incorporating with two core techniques. 1) Multi-perspective Visual Projection, it captures diverse emotional cues from visual data from multiple perspectives. 2) EmoPrompt, it guides MLLMs to reason about emotions in the correct direction. Experimental results demonstrate that EmoLLM significantly elevates multimodal emotional understanding performance, with an average improvement of 12.1% across multiple foundation models on EmoBench. Our work contributes to the advancement of MLLMs by facilitating a deeper and more nuanced comprehension of intricate human emotions, paving the way for the development of artificial emotional intelligence capabilities with wide-ranging applications in areas such as human-computer interaction, mental health support, and empathetic AI systems. Code, data, and model will be released.
6/26/2024
Contextual Emotion Recognition using Large Vision Language Models
Yasaman Etesam, Ozge Nilay Yalc{c}{i}n, Chuxuan Zhang, Angelica Lim
0
0
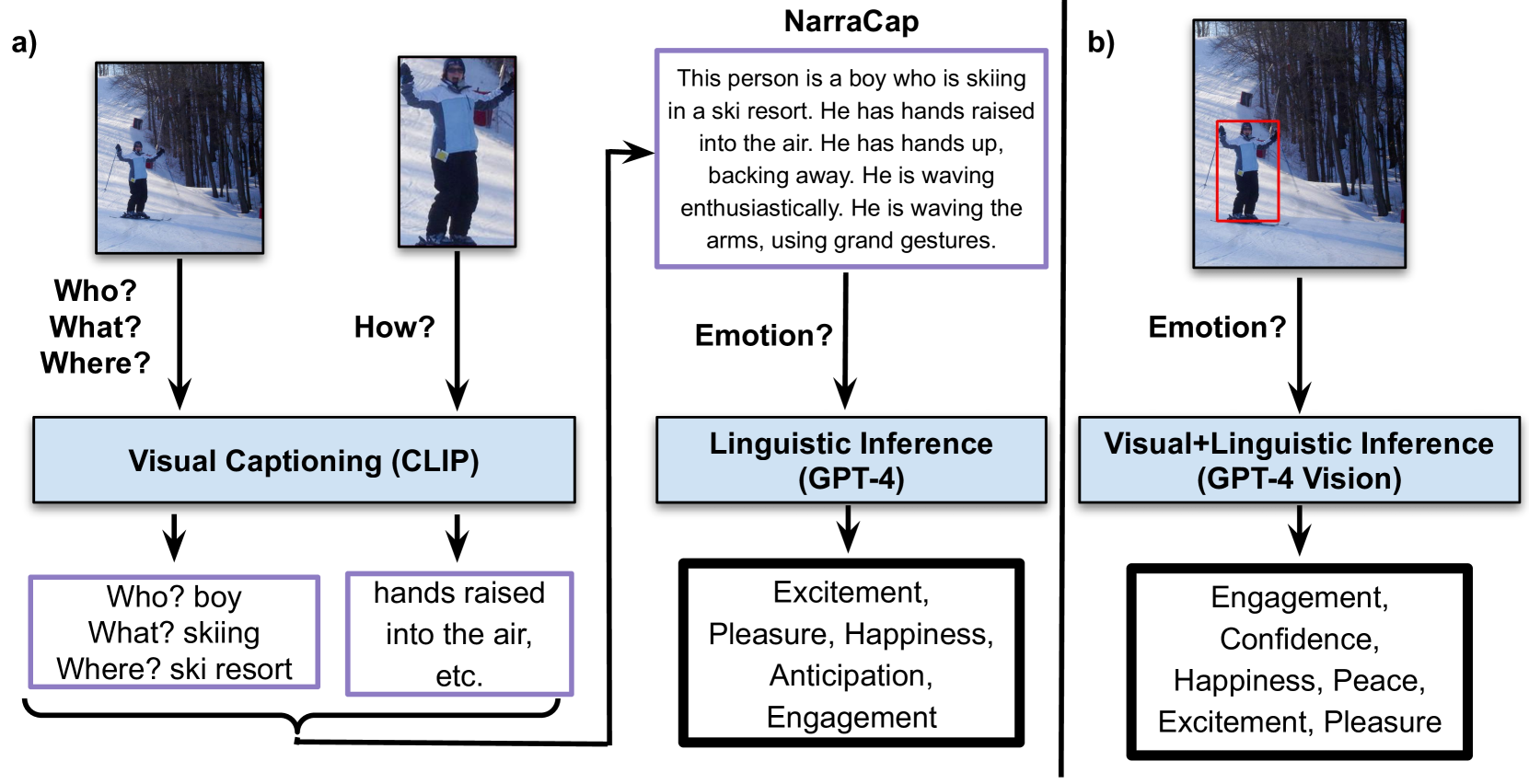
How does the person in the bounding box feel? Achieving human-level recognition of the apparent emotion of a person in real world situations remains an unsolved task in computer vision. Facial expressions are not enough: body pose, contextual knowledge, and commonsense reasoning all contribute to how humans perform this emotional theory of mind task. In this paper, we examine two major approaches enabled by recent large vision language models: 1) image captioning followed by a language-only LLM, and 2) vision language models, under zero-shot and fine-tuned setups. We evaluate the methods on the Emotions in Context (EMOTIC) dataset and demonstrate that a vision language model, fine-tuned even on a small dataset, can significantly outperform traditional baselines. The results of this work aim to help robots and agents perform emotionally sensitive decision-making and interaction in the future.
5/16/2024