SALMONN: Towards Generic Hearing Abilities for Large Language Models
2310.13289
2
0
Abstract
Hearing is arguably an essential ability of artificial intelligence (AI) agents in the physical world, which refers to the perception and understanding of general auditory information consisting of at least three types of sounds: speech, audio events, and music. In this paper, we propose SALMONN, a speech audio language music open neural network, built by integrating a pre-trained text-based large language model (LLM) with speech and audio encoders into a single multimodal model. SALMONN enables the LLM to directly process and understand general audio inputs and achieve competitive performances on a number of speech and audio tasks used in training, such as automatic speech recognition and translation, auditory-information-based question answering, emotion recognition, speaker verification, and music and audio captioning etc. SALMONN also has a diverse set of emergent abilities unseen in the training, which includes but is not limited to speech translation to untrained languages, speech-based slot filling, spoken-query-based question answering, audio-based storytelling, and speech audio co-reasoning etc. The presence of cross-modal emergent abilities is studied, and a novel few-shot activation tuning approach is proposed to activate such abilities. To our knowledge, SALMONN is the first model of its type and can be regarded as a step towards AI with generic hearing abilities. The source code, model checkpoints and data are available at https://github.com/bytedance/SALMONN.
Get summaries of the top AI research delivered straight to your inbox:
Introduction
This paper presents SALMONN, a novel approach aimed at equipping large language models with generic hearing abilities. Large language models have become increasingly powerful in processing and generating text, but they often lack the ability to understand and interact with audio data. The SALMONN framework seeks to address this gap, enabling language models to perceive and comprehend audio input in a more natural and seamless way.
Related Work
The paper situates SALMONN within the broader context of multimodal learning, which combines various sensory inputs such as vision, audio, and text to enhance the capabilities of AI systems. It highlights relevant research in areas like SonicVisionLM: Playing with Sound and Vision in Language Models, A Review of Multimodal Large Language and Vision Models, and Multi-Level Attention Aggregation for Language-Agnostic Speaker Verification. These works demonstrate the potential of integrating audio and other modalities into language models to improve their overall understanding and performance.
Methodology
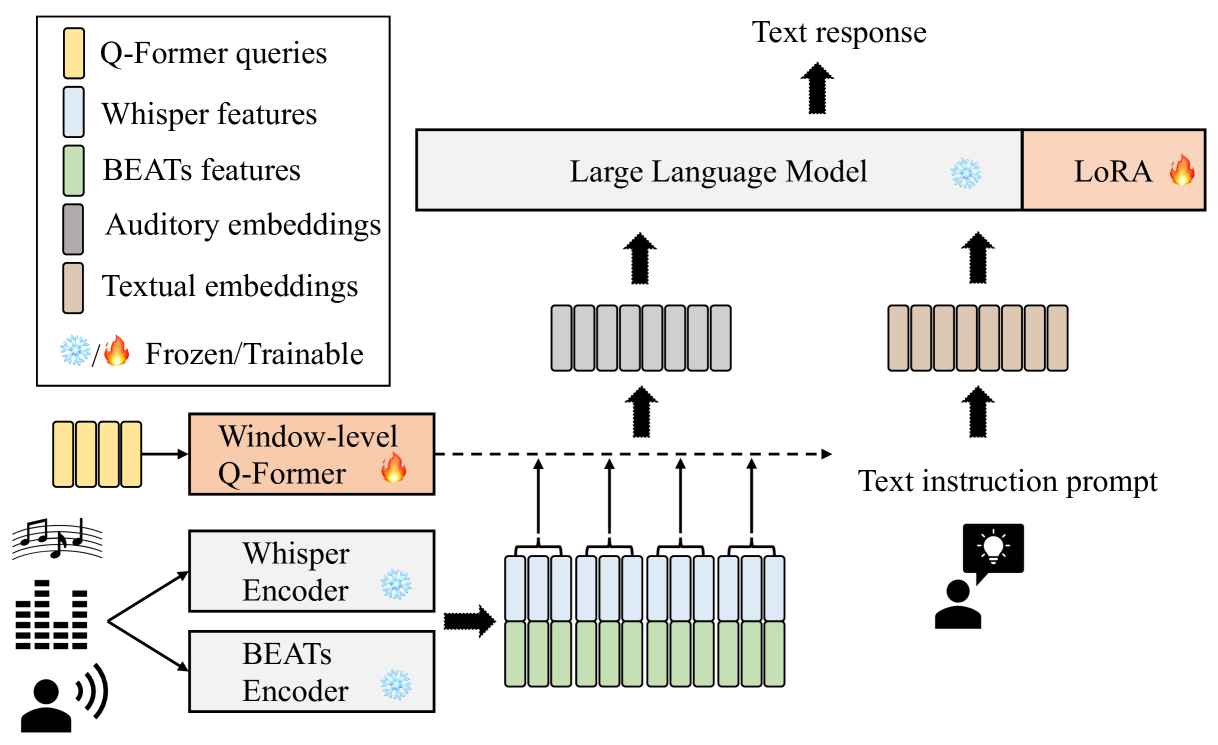
SALMONN Architecture
The core of the SALMONN framework is a novel neural network architecture that enables large language models to process and understand audio input. The architecture incorporates several key components:
- Audio Encoder: This module takes raw audio data as input and extracts meaningful features and representations, allowing the language model to comprehend the acoustic information.
- Multimodal Fusion: The audio representations are then seamlessly integrated with the language model's text processing capabilities, enabling the model to jointly reason about both audio and textual data.
- Downstream Tasks: The fused multimodal representations can be leveraged for a variety of downstream tasks, such as audio-based question answering, audio transcription, and audio-guided text generation.
By combining these elements, SALMONN aims to provide large language models with the ability to understand and interact with audio data, expanding their capabilities beyond pure text processing.
Technical Explanation
The SALMONN architecture builds upon existing large language models, such as BERT and GPT-3, by integrating an audio encoder module. This audio encoder is responsible for extracting meaningful features from raw audio input, which are then combined with the text-based representations using a multimodal fusion mechanism.
The specific implementation details of the audio encoder and multimodal fusion components are not provided in the paper, but the authors indicate that they leverage well-established techniques from the fields of audio processing and multimodal learning. The resulting combined representations can then be used as input to various downstream tasks, such as audio-based question answering or audio-guided text generation.
Critical Analysis
The SALMONN approach represents an important step towards equipping large language models with generic hearing abilities. By integrating audio processing capabilities, the authors aim to create more comprehensive and versatile AI systems that can seamlessly interact with both textual and audio data.
One potential limitation of the SALMONN framework is the lack of detailed information about the specific architectural choices and training procedures. Without access to these technical details, it can be challenging to fully assess the model's performance and robustness across a range of audio-based tasks.
Additionally, the paper does not provide a comprehensive evaluation of SALMONN's capabilities compared to other state-of-the-art approaches in multimodal learning, such as MusiLingo: Bridging Music and Text with Pre-trained Language Models or Weakly Supervised Audio Separation via Bi-Modal Signals. Further comparative analysis could help better understand the strengths and limitations of the SALMONN approach.
Conclusion
The SALMONN framework represents a promising step towards equipping large language models with generic hearing abilities. By integrating audio processing capabilities into these powerful text-based models, the authors aim to create more versatile and multimodal AI systems that can better understand and interact with the world around them.
While the technical details of the SALMONN architecture are not fully disclosed, the overall concept of bridging the gap between language models and audio input is a significant contribution to the field of multimodal learning. As this area of research continues to evolve, further advancements in integrating audio, vision, and other modalities into language models could lead to even more intelligent and adaptive AI systems capable of understanding and engaging with the rich, multimodal nature of human communication and interaction.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🗣️
AudioChatLlama: Towards General-Purpose Speech Abilities for LLMs
Yassir Fathullah, Chunyang Wu, Egor Lakomkin, Ke Li, Junteng Jia, Yuan Shangguan, Jay Mahadeokar, Ozlem Kalinli, Christian Fuegen, Mike Seltzer
0
0
In this work, we extend the instruction-tuned Llama-2 model with end-to-end general-purpose speech processing and reasoning abilities while maintaining the wide range of original LLM capabilities, without using any carefully curated paired data. The resulting end-to-end model, named AudioChatLlama, can utilize audio prompts as a replacement for text and sustain a conversation. Such a model also has extended cross-modal capabilities such as being able to perform spoken question answering (QA), speech translation, and audio summarization amongst many other closed and open-domain tasks. This is unlike prior approaches in speech, in which LLMs are extended to handle audio for a limited number of pre-designated tasks. On both synthesized and recorded speech QA test sets, evaluations show that our end-to-end approach is on par with or outperforms cascaded systems (speech recognizer + LLM) in terms of modeling the response to a prompt. Furthermore, unlike cascades, our approach can interchange text and audio modalities and intrinsically utilize prior context in a conversation to provide better results.
4/16/2024
⛏️
SALMON: Self-Alignment with Instructable Reward Models
Zhiqing Sun, Yikang Shen, Hongxin Zhang, Qinhong Zhou, Zhenfang Chen, David Cox, Yiming Yang, Chuang Gan
0
0
Supervised Fine-Tuning (SFT) on response demonstrations combined with Reinforcement Learning from Human Feedback (RLHF) constitutes a powerful paradigm for aligning LLM-based AI agents. However, a significant limitation of such an approach is its dependency on high-quality human annotations, making its application to intricate tasks challenging due to difficulties in obtaining consistent response demonstrations and in-distribution response preferences. This paper presents a novel approach, namely SALMON, to align base language models with minimal human supervision, using only a small set of human-defined principles, yet achieving superior performance. Central to our approach is an instructable reward model. Trained on synthetic preference data, this model can generate reward scores based on arbitrary human-defined principles. By merely adjusting these principles during the RL training phase, we gain full control over the preferences with the instructable reward model, subsequently influencing the behavior of the RL-trained policy models, and reducing the reliance on the collection of online human preferences. Applying our method to the LLaMA-2-70b base language model, we developed an AI assistant named Dromedary-2. With only 6 exemplars for in-context learning and 31 human-defined principles, Dromedary-2 significantly surpasses the performance of several state-of-the-art AI systems, including LLaMA-2-Chat-70b, on various benchmark datasets. We have open-sourced the code and model weights to encourage further research into aligning LLM-based AI agents with enhanced supervision efficiency, improved controllability, and scalable oversight.
4/11/2024
🛸
AudioLDM 2: Learning Holistic Audio Generation with Self-supervised Pretraining
Haohe Liu, Yi Yuan, Xubo Liu, Xinhao Mei, Qiuqiang Kong, Qiao Tian, Yuping Wang, Wenwu Wang, Yuxuan Wang, Mark D. Plumbley
0
0
Although audio generation shares commonalities across different types of audio, such as speech, music, and sound effects, designing models for each type requires careful consideration of specific objectives and biases that can significantly differ from those of other types. To bring us closer to a unified perspective of audio generation, this paper proposes a framework that utilizes the same learning method for speech, music, and sound effect generation. Our framework introduces a general representation of audio, called language of audio (LOA). Any audio can be translated into LOA based on AudioMAE, a self-supervised pre-trained representation learning model. In the generation process, we translate any modalities into LOA by using a GPT-2 model, and we perform self-supervised audio generation learning with a latent diffusion model conditioned on LOA. The proposed framework naturally brings advantages such as in-context learning abilities and reusable self-supervised pretrained AudioMAE and latent diffusion models. Experiments on the major benchmarks of text-to-audio, text-to-music, and text-to-speech demonstrate state-of-the-art or competitive performance against previous approaches. Our code, pretrained model, and demo are available at https://audioldm.github.io/audioldm2.
5/14/2024
📈
Audio is all in one: speech-driven gesture synthetics using WavLM pre-trained model
Fan Zhang, Naye Ji, Fuxing Gao, Siyuan Zhao, Zhaohan Wang, Shunman Li
0
0
The generation of co-speech gestures for digital humans is an emerging area in the field of virtual human creation. Prior research has made progress by using acoustic and semantic information as input and adopting classify method to identify the person's ID and emotion for driving co-speech gesture generation. However, this endeavour still faces significant challenges. These challenges go beyond the intricate interplay between co-speech gestures, speech acoustic, and semantics; they also encompass the complexities associated with personality, emotion, and other obscure but important factors. This paper introduces diffmotion-v2, a speech-conditional diffusion-based and non-autoregressive transformer-based generative model with WavLM pre-trained model. It can produce individual and stylized full-body co-speech gestures only using raw speech audio, eliminating the need for complex multimodal processing and manually annotated. Firstly, considering that speech audio not only contains acoustic and semantic features but also conveys personality traits, emotions, and more subtle information related to accompanying gestures, we pioneer the adaptation of WavLM, a large-scale pre-trained model, to extract low-level and high-level audio information. Secondly, we introduce an adaptive layer norm architecture in the transformer-based layer to learn the relationship between speech information and accompanying gestures. Extensive subjective evaluation experiments are conducted on the Trinity, ZEGGS, and BEAT datasets to confirm the WavLM and the model's ability to synthesize natural co-speech gestures with various styles.
4/16/2024