Video-STaR: Self-Training Enables Video Instruction Tuning with Any Supervision

0
⚙️
Sign in to get full access
Overview
- Large Vision Language Models (LVLMs) perform well when trained on high-quality, diverse datasets
- Existing video instruction tuning datasets are limited as they are generated from language model prompts and tend to be descriptive
- Many labeled video datasets with diverse labels and supervision exist, but integrating them into LVLMs is challenging
- Video-STaR is a new video self-training approach that allows LVLMs to utilize existing labeled video datasets for instruction tuning
Plain English Explanation
Video-STaR: The First Video Self-Training Approach for Large Vision Language Models
Large Vision Language Models (LVLMs) are powerful AI systems that can understand and generate text and images. Their performance depends on the size and quality of their training data. However, the video instruction datasets currently used to train these models are often limited, as they are generated by prompting language models to create question-answer pairs based on video captions. This means the datasets tend to be mostly descriptive, lacking diversity.
Meanwhile, there are many existing labeled video datasets with a wide variety of information and supervision. But integrating these datasets into LVLMs has proven difficult. To address this, the researchers developed Video-STaR, the first video self-training approach.
Video-STaR allows LVLMs to utilize any labeled video dataset for instruction tuning. The model goes through a cycle of generating answers to video-based prompts and then retraining on the generated answers that contain the original video labels. This helps the LVLM learn from the diverse supervision in the existing video datasets, improving its general video understanding and ability to adapt to new tasks.
The researchers found that LVLMs trained with Video-STaR exhibited significant performance improvements. On general video question-answering, their model's TempCompass score improved by 10%. On downstream tasks like Kinetics700-QA and action quality assessment on FineDiving, Video-STaR boosted accuracy by 20% and 15%, respectively.
Technical Explanation
The core idea of Video-STaR is to leverage existing labeled video datasets to enhance the performance of Large Vision Language Models (LVLMs). Existing video instruction tuning datasets are derived by prompting large language models to generate question-answer pairs based on video captions, resulting in datasets that are mostly descriptive.
To address this, the researchers propose a video self-training approach. In Video-STaR, the LVLM cycles between two steps:
- Instruction generation: The LVLM is prompted to generate answers to video-based questions.
- Finetuning: The LVLM is retrained, but only on the generated answers that contain the original video labels.
By only training on generated answers that match the video labels, Video-STaR utilizes the existing video labels as weak supervision to help the LVLM learn from the diverse information in the labeled video datasets.
The researchers show that this approach (I) improves the LVLM's general video understanding, as measured by a 10% increase in TempCompass performance, and (II) helps the LVLM adapt to novel downstream tasks, where they observed a 20% boost in Kinetics700-QA accuracy and a 15% improvement in action quality assessment on FineDiving.
Critical Analysis
The Video-STaR approach represents an important step forward in leveraging existing labeled video datasets to enhance Large Vision Language Models (LVLMs). By using a self-training approach that filters the generated answers to only those containing the original video labels, the researchers have found a way to integrate diverse video supervision into LVLMs.
However, the paper does not address the potential limitations of this approach. For example, the quality and diversity of the generated answers may still be constrained by the initial prompting of the LVLM, even if the final training dataset is filtered. Additionally, the self-training process could potentially amplify any biases or errors present in the original video labels.
Further research is needed to explore the robustness of the Video-STaR approach, such as its sensitivity to the quality and characteristics of the initial video dataset, and to investigate ways to mitigate potential issues with the generated answers. Comparisons to other techniques for integrating diverse video supervision, such as directed domain fine-tuning or self-training for large language models, would also help contextualize the strengths and limitations of this new approach.
Conclusion
Video-STaR represents a promising new technique for enhancing Large Vision Language Models (LVLMs) by leveraging existing labeled video datasets. The self-training approach allows LVLMs to learn from diverse video supervision, leading to significant improvements in general video understanding and the ability to adapt to novel downstream tasks.
While the results are encouraging, further research is needed to fully understand the capabilities and limitations of Video-STaR. Exploring the robustness of the approach and comparing it to other techniques for integrating video data will be important next steps. Overall, this work highlights the potential of self-training methods to distill vision and language models from millions of videos and extend video understanding in powerful AI models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
⚙️
0
Video-STaR: Self-Training Enables Video Instruction Tuning with Any Supervision
Orr Zohar, Xiaohan Wang, Yonatan Bitton, Idan Szpektor, Serena Yeung-Levy
The performance of Large Vision Language Models (LVLMs) is dependent on the size and quality of their training datasets. Existing video instruction tuning datasets lack diversity as they are derived by prompting large language models with video captions to generate question-answer pairs, and are therefore mostly descriptive. Meanwhile, many labeled video datasets with diverse labels and supervision exist - however, we find that their integration into LVLMs is non-trivial. Herein, we present Video Self-Training with augmented Reasoning (Video-STaR), the first video self-training approach. Video-STaR allows the utilization of any labeled video dataset for video instruction tuning. In Video-STaR, an LVLM cycles between instruction generation and finetuning, which we show (I) improves general video understanding and (II) adapts LVLMs to novel downstream tasks with existing supervision. During generation, an LVLM is prompted to propose an answer. The answers are then filtered only to those that contain the original video labels, and the LVLM is then re-trained on the generated dataset. By only training on generated answers that contain the correct video labels, Video-STaR utilizes these existing video labels as weak supervision for video instruction tuning. Our results demonstrate that Video-STaR-enhanced LVLMs exhibit improved performance in (I) general video QA, where TempCompass performance improved by 10%, and (II) on downstream tasks, where Video-STaR improved Kinetics700-QA accuracy by 20% and action quality assessment on FineDiving by 15%.
Read more7/9/2024

0
Distilling Vision-Language Models on Millions of Videos
Yue Zhao, Long Zhao, Xingyi Zhou, Jialin Wu, Chun-Te Chu, Hui Miao, Florian Schroff, Hartwig Adam, Ting Liu, Boqing Gong, Philipp Krahenbuhl, Liangzhe Yuan
The recent advance in vision-language models is largely attributed to the abundance of image-text data. We aim to replicate this success for video-language models, but there simply is not enough human-curated video-text data available. We thus resort to fine-tuning a video-language model from a strong image-language baseline with synthesized instructional data. The resulting video model by video-instruction-tuning (VIIT) is then used to auto-label millions of videos to generate high-quality captions. We show the adapted video-language model performs well on a wide range of video-language benchmarks. For instance, it surpasses the best prior result on open-ended NExT-QA by 2.8%. Besides, our model generates detailed descriptions for previously unseen videos, which provide better textual supervision than existing methods. Experiments show that a video-language dual-encoder model contrastively trained on these auto-generated captions is 3.8% better than the strongest baseline that also leverages vision-language models. Our best model outperforms state-of-the-art methods on MSR-VTT zero-shot text-to-video retrieval by 6%. As a side product, we generate the largest video caption dataset to date.
Read more4/17/2024
0
Enhancing Large Vision Language Models with Self-Training on Image Comprehension
Yihe Deng, Pan Lu, Fan Yin, Ziniu Hu, Sheng Shen, James Zou, Kai-Wei Chang, Wei Wang
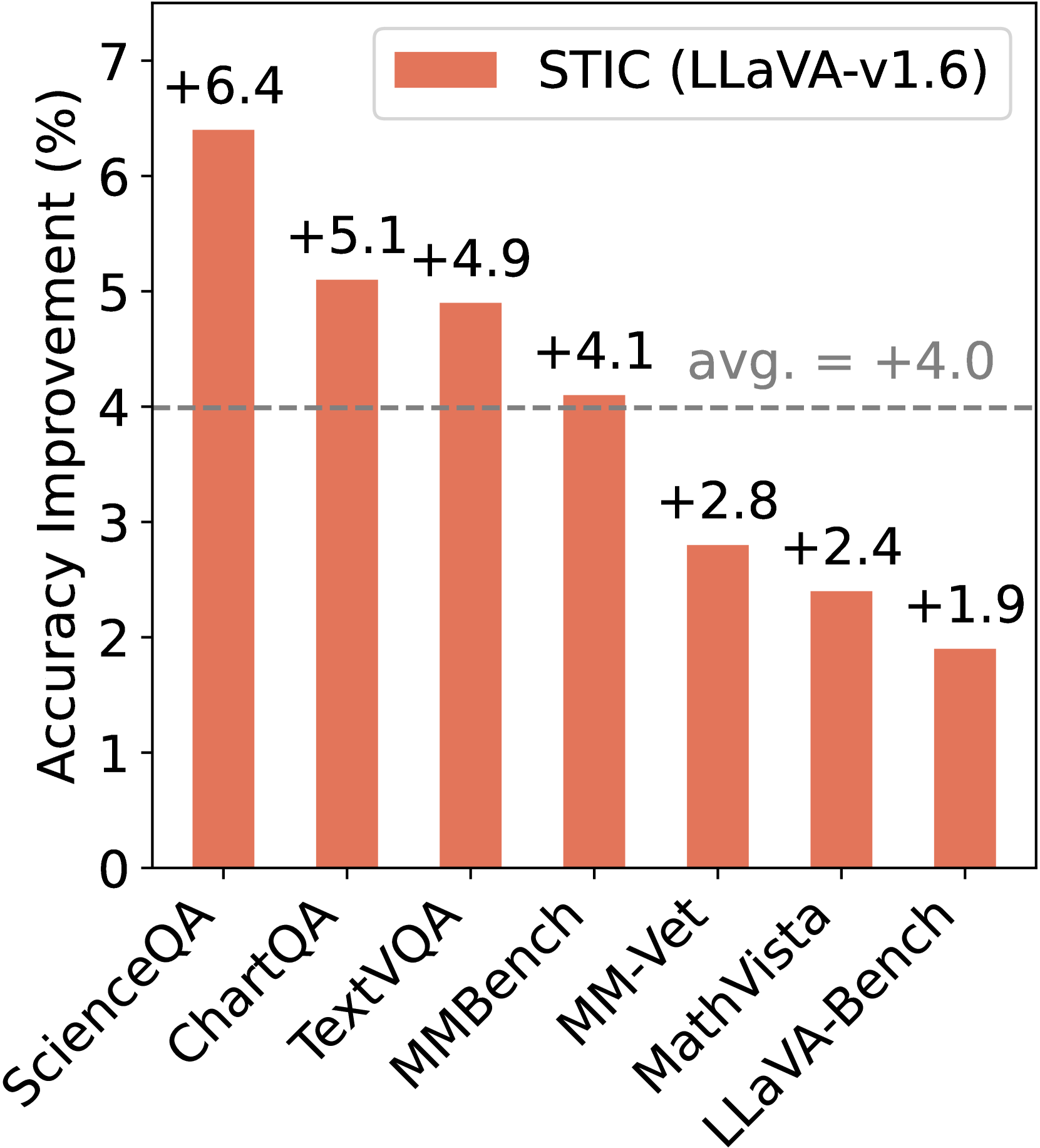
Large vision language models (LVLMs) integrate large language models (LLMs) with pre-trained vision encoders, thereby activating the perception capability of the model to understand image inputs for different queries and conduct subsequent reasoning. Improving this capability requires high-quality vision-language data, which is costly and labor-intensive to acquire. Self-training approaches have been effective in single-modal settings to alleviate the need for labeled data by leveraging model's own generation. However, effective self-training remains a challenge regarding the unique visual perception and reasoning capability of LVLMs. To address this, we introduce Self-Training on Image Comprehension (STIC), which emphasizes a self-training approach specifically for image comprehension. First, the model self-constructs a preference dataset for image descriptions using unlabeled images. Preferred responses are generated through a step-by-step prompt, while dis-preferred responses are generated from either corrupted images or misleading prompts. To further self-improve reasoning on the extracted visual information, we let the model reuse a small portion of existing instruction-tuning data and append its self-generated image descriptions to the prompts. We validate the effectiveness of STIC across seven different benchmarks, demonstrating substantial performance gains of 4.0% on average while using 70% less supervised fine-tuning data than the current method. Further studies investigate various components of STIC and highlight its potential to leverage vast quantities of unlabeled images for self-training. Code and data are made publicly available.
Read more5/31/2024
🏋️
0
V-STaR: Training Verifiers for Self-Taught Reasoners
Arian Hosseini, Xingdi Yuan, Nikolay Malkin, Aaron Courville, Alessandro Sordoni, Rishabh Agarwal
Common self-improvement approaches for large language models (LLMs), such as STaR, iteratively fine-tune LLMs on self-generated solutions to improve their problem-solving ability. However, these approaches discard the large amounts of incorrect solutions generated during this process, potentially neglecting valuable information in such solutions. To address this shortcoming, we propose V-STaR that utilizes both the correct and incorrect solutions generated during the self-improvement process to train a verifier using DPO that judges correctness of model-generated solutions. This verifier is used at inference time to select one solution among many candidate solutions. Running V-STaR for multiple iterations results in progressively better reasoners and verifiers, delivering a 4% to 17% test accuracy improvement over existing self-improvement and verification approaches on common code generation and math reasoning benchmarks with LLaMA2 models.
Read more8/15/2024