VideoDirectorGPT: Consistent Multi-scene Video Generation via LLM-Guided Planning

0
🛸
Sign in to get full access
Overview
- Recent text-to-video (T2V) generation methods have made significant advancements, but most focus on producing short single-scene videos.
- Large language models (LLMs) have shown the capability to generate layouts and programs to control downstream visual modules.
- The paper explores whether the knowledge embedded in LLMs can be leveraged for generating temporally consistent long videos.
Plain English Explanation
The paper proposes a new framework called VideoDirectorGPT that uses the capabilities of large language models (LLMs) to generate consistent multi-scene videos.
Traditionally, text-to-video generation methods have been able to create short video clips of single events. However, the authors wanted to see if they could use the knowledge within powerful language models, like GPT-4, to generate longer videos that have a consistent storyline and movement across multiple scenes.
The key idea is to first have the language model (GPT-4) generate a "video plan" that lays out the different scenes, the entities (objects/people) in each scene, their layouts, and how they should move between scenes. Then, a video generator called "Layout2Vid" uses this plan to produce the actual video, ensuring the layouts and movements are consistent across the multiple scenes.
This approach allows for greater control over the video generation process and helps produce longer, more coherent videos compared to previous text-to-video methods, which often struggled with maintaining consistency over multiple scenes.
Technical Explanation
The VideoDirectorGPT framework consists of two main components:
-
Video Planner (GPT-4): This large language model is tasked with expanding the input text prompt into a "video plan." The video plan includes details such as the scene descriptions, the entities (objects/people) and their respective layouts, the background for each scene, and consistency groupings of the entities.
-
Video Generator (Layout2Vid): Guided by the video plan from the GPT-4 model, the Layout2Vid generator has explicit control over the spatial layouts of entities and can maintain temporal consistency of those entities across multiple scenes. Importantly, Layout2Vid is trained only with image-level annotations, without any video-level supervision.
The experiments in the paper demonstrate that the VideoDirectorGPT framework substantially improves layout and movement control in both single- and multi-scene video generation. It can generate multi-scene videos with better consistency compared to previous approaches, while also achieving competitive performance on open-domain single-scene text-to-video generation tasks.
The paper also includes several ablation studies, such as dynamically adjusting the layout control strength using the LLM and generating videos with user-provided images. These experiments confirm the effectiveness of the individual components of the framework and its potential for future development.
Critical Analysis
The paper presents a novel and promising approach to leveraging large language models for generating more coherent and consistent multi-scene videos. By using the video plan generated by GPT-4 to guide the video generation process, the authors have found a way to better control the layouts and movements of entities across scenes.
However, the paper does acknowledge some limitations. For example, the video generation quality is still not on par with human-created videos, and the approach may struggle with generating videos that require complex narratives or interactions between entities.
Additionally, the paper does not delve into the potential biases or safety concerns that may arise from using a powerful language model like GPT-4 as part of the video generation pipeline. As these models can sometimes produce biased or inappropriate content, it would be important to consider such issues in future research.
Overall, the VideoDirectorGPT framework represents a significant step forward in text-to-video generation and highlights the potential of leveraging large language models for more sophisticated visual content creation. Further research is needed to address the remaining challenges and explore the broader implications of this approach.
Conclusion
The paper presents the VideoDirectorGPT framework, which demonstrates how the knowledge embedded in large language models can be harnessed to generate temporally consistent multi-scene videos. By using GPT-4 to plan the video content and Layout2Vid to generate the actual video, the framework achieves better layout and movement control compared to previous text-to-video methods.
This work highlights the potential of combining the strengths of large language models, like their ability to reason about complex scenarios, with specialized video generation models to produce more sophisticated and coherent visual content. As language models continue to advance, and as techniques for grounding them in visual data improve, we may see increasingly powerful text-to-video generation systems that can create videos with greater narrative complexity and realism.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛸
0
VideoDirectorGPT: Consistent Multi-scene Video Generation via LLM-Guided Planning
Han Lin, Abhay Zala, Jaemin Cho, Mohit Bansal
Recent text-to-video (T2V) generation methods have seen significant advancements. However, the majority of these works focus on producing short video clips of a single event (i.e., single-scene videos). Meanwhile, recent large language models (LLMs) have demonstrated their capability in generating layouts and programs to control downstream visual modules. This prompts an important question: can we leverage the knowledge embedded in these LLMs for temporally consistent long video generation? In this paper, we propose VideoDirectorGPT, a novel framework for consistent multi-scene video generation that uses the knowledge of LLMs for video content planning and grounded video generation. Specifically, given a single text prompt, we first ask our video planner LLM (GPT-4) to expand it into a 'video plan', which includes the scene descriptions, the entities with their respective layouts, the background for each scene, and consistency groupings of the entities. Next, guided by this video plan, our video generator, named Layout2Vid, has explicit control over spatial layouts and can maintain temporal consistency of entities across multiple scenes, while being trained only with image-level annotations. Our experiments demonstrate that our proposed VideoDirectorGPT framework substantially improves layout and movement control in both single- and multi-scene video generation and can generate multi-scene videos with consistency, while achieving competitive performance with SOTAs in open-domain single-scene T2V generation. Detailed ablation studies, including dynamic adjustment of layout control strength with an LLM and video generation with user-provided images, confirm the effectiveness of each component of our framework and its future potential.
Read more7/16/2024

0
Compositional 3D-aware Video Generation with LLM Director
Hanxin Zhu, Tianyu He, Anni Tang, Junliang Guo, Zhibo Chen, Jiang Bian
Significant progress has been made in text-to-video generation through the use of powerful generative models and large-scale internet data. However, substantial challenges remain in precisely controlling individual concepts within the generated video, such as the motion and appearance of specific characters and the movement of viewpoints. In this work, we propose a novel paradigm that generates each concept in 3D representation separately and then composes them with priors from Large Language Models (LLM) and 2D diffusion models. Specifically, given an input textual prompt, our scheme consists of three stages: 1) We leverage LLM as the director to first decompose the complex query into several sub-prompts that indicate individual concepts within the video~(textit{e.g.}, scene, objects, motions), then we let LLM to invoke pre-trained expert models to obtain corresponding 3D representations of concepts. 2) To compose these representations, we prompt multi-modal LLM to produce coarse guidance on the scales and coordinates of trajectories for the objects. 3) To make the generated frames adhere to natural image distribution, we further leverage 2D diffusion priors and use Score Distillation Sampling to refine the composition. Extensive experiments demonstrate that our method can generate high-fidelity videos from text with diverse motion and flexible control over each concept. Project page: url{https://aka.ms/c3v}.
Read more9/4/2024
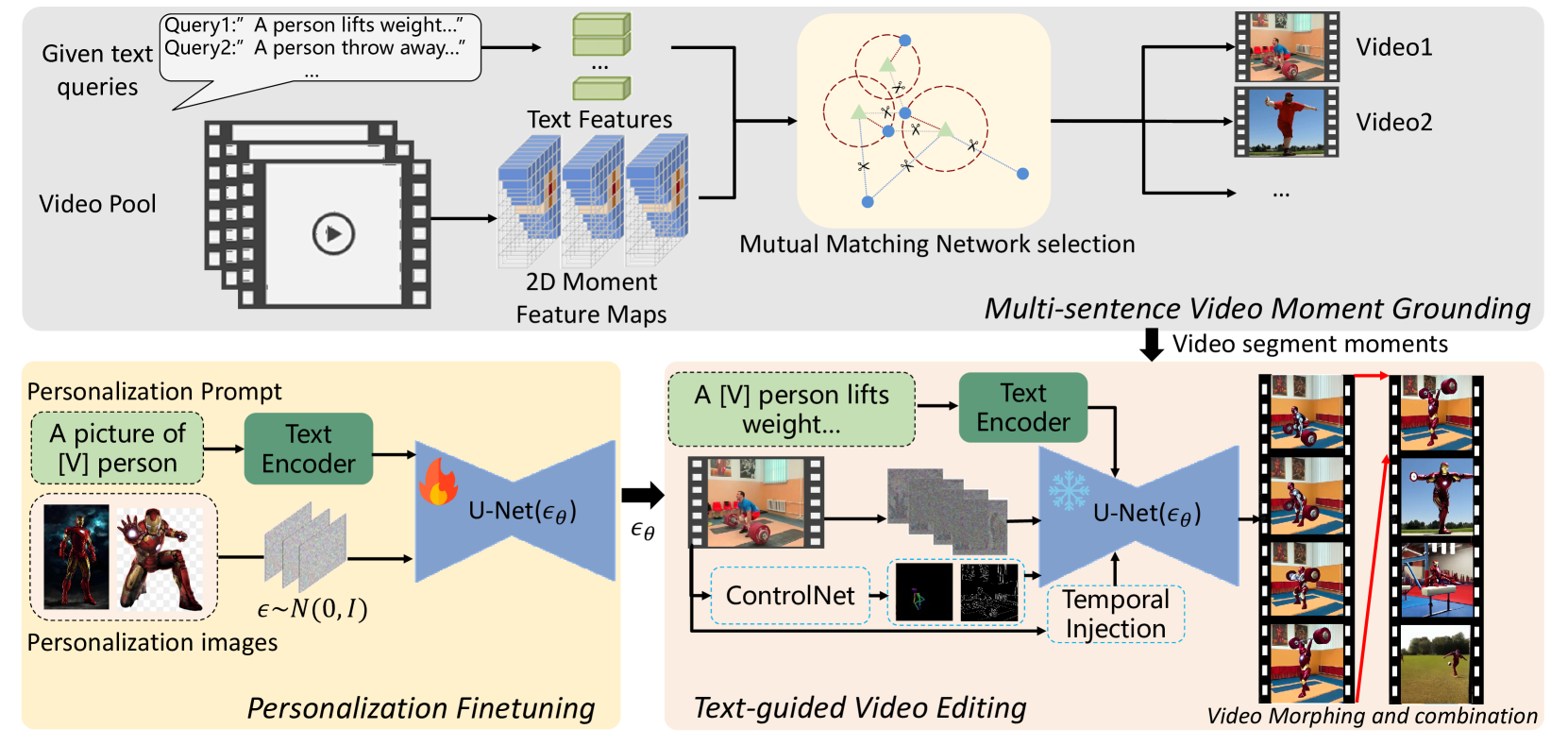
0
Multi-sentence Video Grounding for Long Video Generation
Wei Feng, Xin Wang, Hong Chen, Zeyang Zhang, Wenwu Zhu
Video generation has witnessed great success recently, but their application in generating long videos still remains challenging due to the difficulty in maintaining the temporal consistency of generated videos and the high memory cost during generation. To tackle the problems, in this paper, we propose a brave and new idea of Multi-sentence Video Grounding for Long Video Generation, connecting the massive video moment retrieval to the video generation task for the first time, providing a new paradigm for long video generation. The method of our work can be summarized as three steps: (i) We design sequential scene text prompts as the queries for video grounding, utilizing the massive video moment retrieval to search for video moment segments that meet the text requirements in the video database. (ii) Based on the source frames of retrieved video moment segments, we adopt video editing methods to create new video content while preserving the temporal consistency of the retrieved video. Since the editing can be conducted segment by segment, and even frame by frame, it largely reduces the memory cost. (iii) We also attempt video morphing and personalized generation methods to improve the subject consistency of long video generation, providing ablation experimental results for the subtasks of long video generation. Our approach seamlessly extends the development in image/video editing, video morphing and personalized generation, and video grounding to the long video generation, offering effective solutions for generating long videos at low memory cost.
Read more7/19/2024
🤖
0
LLM-grounded Video Diffusion Models
Long Lian, Baifeng Shi, Adam Yala, Trevor Darrell, Boyi Li
Text-conditioned diffusion models have emerged as a promising tool for neural video generation. However, current models still struggle with intricate spatiotemporal prompts and often generate restricted or incorrect motion. To address these limitations, we introduce LLM-grounded Video Diffusion (LVD). Instead of directly generating videos from the text inputs, LVD first leverages a large language model (LLM) to generate dynamic scene layouts based on the text inputs and subsequently uses the generated layouts to guide a diffusion model for video generation. We show that LLMs are able to understand complex spatiotemporal dynamics from text alone and generate layouts that align closely with both the prompts and the object motion patterns typically observed in the real world. We then propose to guide video diffusion models with these layouts by adjusting the attention maps. Our approach is training-free and can be integrated into any video diffusion model that admits classifier guidance. Our results demonstrate that LVD significantly outperforms its base video diffusion model and several strong baseline methods in faithfully generating videos with the desired attributes and motion patterns.
Read more5/7/2024