VideoEval: Comprehensive Benchmark Suite for Low-Cost Evaluation of Video Foundation Model

0

Sign in to get full access
Overview
• This paper introduces VideoEval, a comprehensive benchmark suite for evaluating the performance of video foundation models, which are large-scale machine learning models trained on vast amounts of video data.
• The goal of VideoEval is to provide a standardized and low-cost way to assess the capabilities of these video foundation models across a diverse range of tasks and datasets, enabling more efficient model development and comparison.
Plain English Explanation
VideoEval is a collection of different video-based tasks and datasets that can be used to evaluate the performance of large machine learning models that have been trained on a lot of video data. These "video foundation models" are becoming increasingly important for applications like video understanding, analysis, and generation.
The key idea behind VideoEval is to provide a standardized and low-cost way for researchers and developers to assess the capabilities of their video foundation models. By running these models on the VideoEval benchmark, they can get a sense of how well the models perform on a diverse range of video-related tasks, from recognizing objects and actions to generating captions and summarizing content.
This is valuable because it allows them to identify the strengths and weaknesses of their models, compare them to other models, and make more informed decisions about how to improve and deploy them. Having a consistent, well-designed benchmark suite like VideoEval can accelerate the development of more capable and versatile video foundation models, which could then be used in a wide variety of real-world applications.
Technical Explanation
The paper introduces VideoEval, a comprehensive benchmark suite for evaluating video foundation models. It is designed to cover a diverse range of video-related tasks, including object detection, action recognition, video captioning, video summarization, and more.
The VideoEval benchmark is built upon existing datasets, such as MSRVTT, ActivityNet, and YouCook2, as well as newly curated datasets. It provides a standardized evaluation protocol, including metrics, leaderboards, and submission guidelines, to enable fair and consistent comparisons between different video foundation models.
The paper also introduces a novel "low-cost" evaluation mode, which uses a subset of the full VideoEval benchmark to provide a quicker and more efficient way to assess model performance. This can be particularly useful during the iterative development process, when researchers and engineers need to frequently evaluate their models.
The authors demonstrate the utility of VideoEval by benchmarking several state-of-the-art video foundation models, including CLIP and ViViT, and provide insights into their strengths and weaknesses across different tasks.
Critical Analysis
The VideoEval benchmark appears to be a comprehensive and well-designed suite for evaluating video foundation models. The inclusion of a diverse range of tasks and datasets, as well as the low-cost evaluation mode, are significant strengths that can help accelerate the development and deployment of these models.
That said, the paper does not address potential biases or limitations in the underlying datasets, which could affect the fairness and validity of the benchmark. It would be helpful to see a more in-depth discussion of these issues, as well as any steps taken to mitigate them.
Additionally, the paper could be strengthened by providing more insights into the performance of the benchmark models, particularly in terms of their relative strengths and weaknesses across different tasks. This could help researchers and developers better understand the current state of the art in video foundation models and identify areas for further improvement.
Conclusion
VideoEval represents a significant step forward in the evaluation of video foundation models, providing a standardized and low-cost way to assess their capabilities across a diverse range of tasks and datasets. By enabling more efficient and consistent model development and comparison, this benchmark has the potential to accelerate progress in video understanding, analysis, and generation, with wide-ranging applications in fields like entertainment, education, and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
VideoEval: Comprehensive Benchmark Suite for Low-Cost Evaluation of Video Foundation Model
Xinhao Li, Zhenpeng Huang, Jing Wang, Kunchang Li, Limin Wang
With the growth of high-quality data and advancement in visual pre-training paradigms, Video Foundation Models (VFMs) have made significant progress recently, demonstrating their remarkable performance on traditional video understanding benchmarks. However, the existing benchmarks (e.g. Kinetics) and their evaluation protocols are often limited by relatively poor diversity, high evaluation costs, and saturated performance metrics. In this paper, we build a comprehensive benchmark suite to address these issues, namely VideoEval. Specifically, we establish the Video Task Adaption Benchmark (VidTAB) and the Video Embedding Benchmark (VidEB) from two perspectives: evaluating the task adaptability of VFMs under few-shot conditions and assessing their representation power by directly applying to downstream tasks. With VideoEval, we conduct a large-scale study on 20 popular open-source vision foundation models. Our study reveals some insightful findings on VFMs: 1) overall, current VFMs exhibit weak generalization across diverse tasks, 2) increasing video data, whether labeled or weakly-labeled video-text pairs, does not necessarily improve task performance, 3) the effectiveness of some pre-training paradigms may not be fully validated in previous benchmarks, and 4) combining different pre-training paradigms can help improve the generalization capabilities. We believe this study serves as an important complement to the current evaluation for VFMs and offers valuable insights for the future research.
Read more7/10/2024

0
Foundation Models for Video Understanding: A Survey
Neelu Madan, Andreas Moegelmose, Rajat Modi, Yogesh S. Rawat, Thomas B. Moeslund
Video Foundation Models (ViFMs) aim to learn a general-purpose representation for various video understanding tasks. Leveraging large-scale datasets and powerful models, ViFMs achieve this by capturing robust and generic features from video data. This survey analyzes over 200 video foundational models, offering a comprehensive overview of benchmarks and evaluation metrics across 14 distinct video tasks categorized into 3 main categories. Additionally, we offer an in-depth performance analysis of these models for the 6 most common video tasks. We categorize ViFMs into three categories: 1) Image-based ViFMs, which adapt existing image models for video tasks, 2) Video-Based ViFMs, which utilize video-specific encoding methods, and 3) Universal Foundational Models (UFMs), which combine multiple modalities (image, video, audio, and text etc.) within a single framework. By comparing the performance of various ViFMs on different tasks, this survey offers valuable insights into their strengths and weaknesses, guiding future advancements in video understanding. Our analysis surprisingly reveals that image-based foundation models consistently outperform video-based models on most video understanding tasks. Additionally, UFMs, which leverage diverse modalities, demonstrate superior performance on video tasks. We share the comprehensive list of ViFMs studied in this work at: url{https://github.com/NeeluMadan/ViFM_Survey.git}
Read more5/8/2024

0
TWLV-I: Analysis and Insights from Holistic Evaluation on Video Foundation Models
Hyeongmin Lee, Jin-Young Kim, Kyungjune Baek, Jihwan Kim, Hyojun Go, Seongsu Ha, Seokjin Han, Jiho Jang, Raehyuk Jung, Daewoo Kim, GeunOh Kim, JongMok Kim, Jongseok Kim, Junwan Kim, Soonwoo Kwon, Jangwon Lee, Seungjoon Park, Minjoon Seo, Jay Suh, Jaehyuk Yi, Aiden Lee
In this work, we discuss evaluating video foundation models in a fair and robust manner. Unlike language or image foundation models, many video foundation models are evaluated with differing parameters (such as sampling rate, number of frames, pretraining steps, etc.), making fair and robust comparisons challenging. Therefore, we present a carefully designed evaluation framework for measuring two core capabilities of video comprehension: appearance and motion understanding. Our findings reveal that existing video foundation models, whether text-supervised like UMT or InternVideo2, or self-supervised like V-JEPA, exhibit limitations in at least one of these capabilities. As an alternative, we introduce TWLV-I, a new video foundation model that constructs robust visual representations for both motion- and appearance-based videos. Based on the average top-1 accuracy of linear probing on five action recognition benchmarks, pretrained only on publicly accessible datasets, our model shows a 4.6%p improvement compared to V-JEPA (ViT-L) and a 7.7%p improvement compared to UMT (ViT-L). Even when compared to much larger models, our model demonstrates a 7.2%p improvement compared to DFN (ViT-H), a 2.7%p improvement compared to V-JEPA (ViT-H) and a 2.8%p improvement compared to InternVideo2 (ViT-g). We provide embedding vectors obtained by TWLV-I from videos of several commonly used video benchmarks, along with evaluation source code that can directly utilize these embeddings. The code is available at https://github.com/twelvelabs-io/video-embeddings-evaluation-framework.
Read more8/26/2024
0
MVBench: A Comprehensive Multi-modal Video Understanding Benchmark
Kunchang Li, Yali Wang, Yinan He, Yizhuo Li, Yi Wang, Yi Liu, Zun Wang, Jilan Xu, Guo Chen, Ping Luo, Limin Wang, Yu Qiao
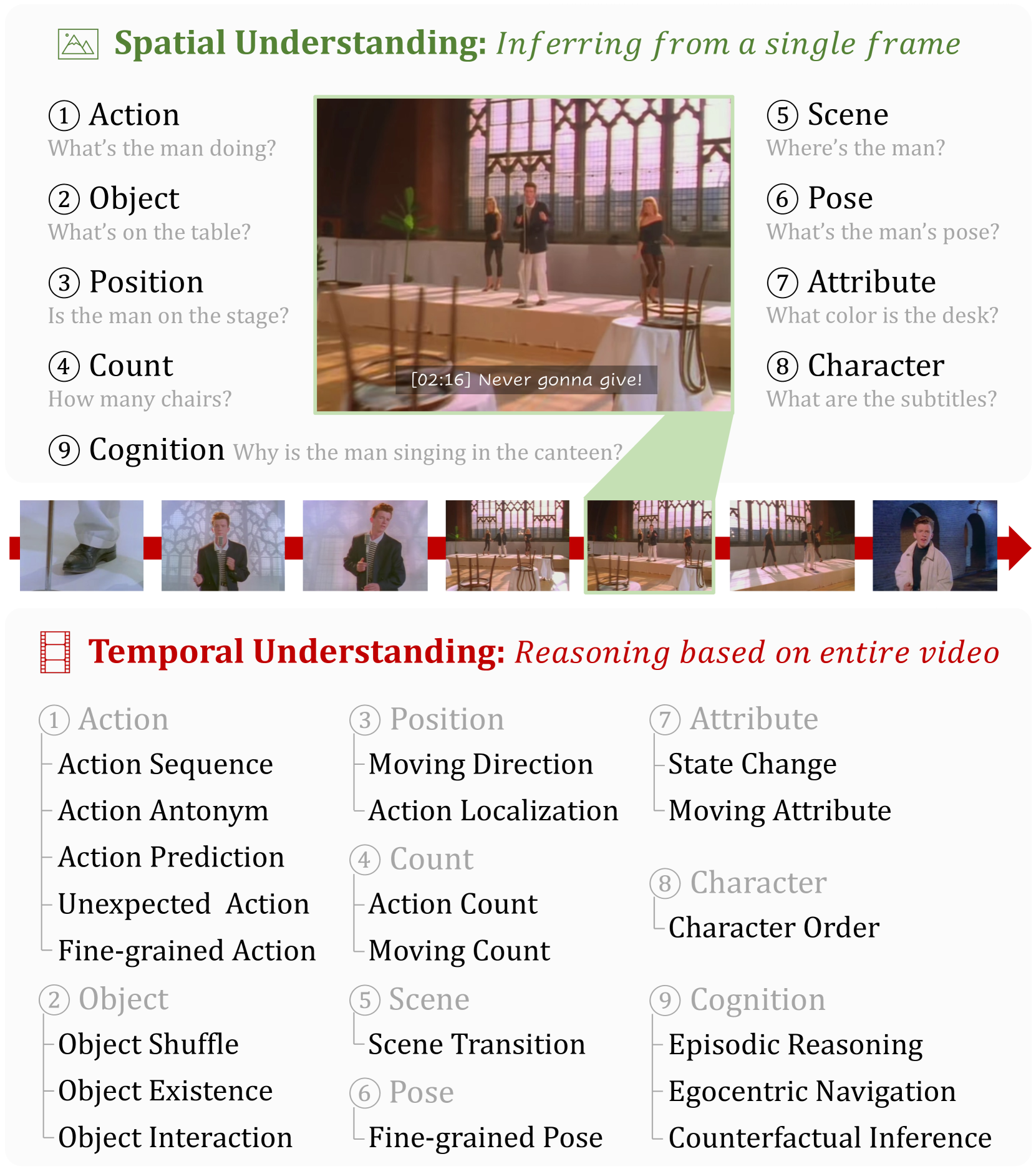
With the rapid development of Multi-modal Large Language Models (MLLMs), a number of diagnostic benchmarks have recently emerged to evaluate the comprehension capabilities of these models. However, most benchmarks predominantly assess spatial understanding in the static image tasks, while overlooking temporal understanding in the dynamic video tasks. To alleviate this issue, we introduce a comprehensive Multi-modal Video understanding Benchmark, namely MVBench, which covers 20 challenging video tasks that cannot be effectively solved with a single frame. Specifically, we first introduce a novel static-to-dynamic method to define these temporal-related tasks. By transforming various static tasks into dynamic ones, we enable the systematic generation of video tasks that require a broad spectrum of temporal skills, ranging from perception to cognition. Then, guided by the task definition, we automatically convert public video annotations into multiple-choice QA to evaluate each task. On one hand, such a distinct paradigm allows us to build MVBench efficiently, without much manual intervention. On the other hand, it guarantees evaluation fairness with ground-truth video annotations, avoiding the biased scoring of LLMs. Moreover, we further develop a robust video MLLM baseline, i.e., VideoChat2, by progressive multi-modal training with diverse instruction-tuning data. The extensive results on our MVBench reveal that, the existing MLLMs are far from satisfactory in temporal understanding, while our VideoChat2 largely surpasses these leading models by over 15% on MVBench. All models and data are available at https://github.com/OpenGVLab/Ask-Anything.
Read more5/24/2024