VideoGUI: A Benchmark for GUI Automation from Instructional Videos

0
Sign in to get full access
Overview
- This paper introduces VideoGUI, a new benchmark for evaluating the ability of AI systems to automate graphical user interface (GUI) interactions based on instructional videos.
- The benchmark aims to facilitate research on multimodal AI models that can understand both visual and textual information from videos to control software applications.
- The dataset includes over 1,000 videos of people completing various GUI-based tasks, along with corresponding annotations of the GUI elements and user actions.
Plain English Explanation
The researchers have created a new dataset and benchmark called VideoGUI to help advance the development of AI systems that can automate interactions with graphical user interfaces (GUIs). GUIs are the visual windows, buttons, menus, and other elements that allow us to control software applications on our computers and phones.
The key idea behind VideoGUI is to provide a way for AI models to learn how to perform GUI-based tasks by watching instructional videos of humans completing those tasks. The dataset includes over 1,000 videos of people using various software applications, along with detailed annotations that identify the specific GUI elements the users are interacting with and the actions they are performing.
By providing this rich, multimodal data, the researchers hope to spur progress on developing AI models that can understand both visual and textual information to control software in more natural, human-like ways. This could lead to breakthroughs in areas like GUI-based search engines, GUI automation, and the creation of high-quality evaluation benchmarks for large language models.
Overall, the VideoGUI dataset and benchmark represent an important step forward in enabling AI systems to interact with and understand graphical user interfaces in more natural and intelligent ways.
Technical Explanation
The VideoGUI benchmark is designed to evaluate the ability of AI models to automate GUI-based tasks by learning from instructional videos. The dataset includes 1,057 videos of users completing a variety of GUI-based tasks, such as editing documents, browsing the web, and using productivity software. Each video is annotated with bounding boxes around the relevant GUI elements and labels for the user's actions.
The researchers propose two main tasks for evaluating AI systems on VideoGUI:
- GUI Element Detection: Identifying the GUI elements (e.g., buttons, menus, text fields) present in each video frame.
- GUI Action Prediction: Predicting the user's actions (e.g., clicking, typing, scrolling) on the GUI elements.
To establish baseline performance, the authors evaluate several state-of-the-art computer vision and language models on these tasks. Their results show that existing models struggle to accurately detect GUI elements and predict user actions, highlighting the need for more advanced multimodal AI approaches.
The VideoGUI dataset and benchmark are intended to catalyze research on developing AI systems that can truly understand and interact with graphical user interfaces in a more natural, human-like way. By providing a standardized evaluation framework, the researchers hope to drive progress in areas such as GUI-based search, GUI automation, and the creation of high-quality benchmarks for large language models.
Critical Analysis
The VideoGUI benchmark represents an important contribution to the field of multimodal AI and GUI automation. By providing a standardized dataset and evaluation framework, the researchers have created a valuable tool for advancing the state of the art in this area.
One potential limitation of the VideoGUI dataset is the relatively small size of the video corpus, with just over 1,000 annotated examples. While this is a substantial dataset, it may not be sufficient to fully capture the diversity of GUI-based tasks and interactions that exist in the real world. Expanding the dataset with more videos and task types could help to make the benchmark more comprehensive and representative.
Additionally, the current evaluation tasks (GUI element detection and action prediction) may not fully capture the complexity of GUI automation, which often involves understanding the underlying functionality and flow of an application. Incorporating more holistic, end-to-end GUI automation tasks could provide a richer assessment of an AI system's capabilities.
Despite these minor concerns, the VideoGUI benchmark represents a valuable contribution to the field and has the potential to drive significant progress in the development of AI systems that can interact with and understand graphical user interfaces in more natural and intelligent ways.
Conclusion
The VideoGUI benchmark introduced in this paper represents an important step forward in the development of AI systems that can automate interactions with graphical user interfaces (GUIs). By providing a standardized dataset and evaluation framework, the researchers have created a valuable tool for advancing research in this area.
The key idea behind VideoGUI is to leverage instructional videos to teach AI models how to perform GUI-based tasks, leveraging both visual and textual information to control software applications in more natural, human-like ways. This could lead to breakthroughs in areas like GUI-based search engines, GUI automation, and the creation of high-quality evaluation benchmarks for large language models.
Overall, the VideoGUI benchmark represents an important contribution to the field of multimodal AI and GUI automation, and has the potential to drive significant progress in enabling AI systems to interact with and understand graphical user interfaces in more natural and intelligent ways.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
VideoGUI: A Benchmark for GUI Automation from Instructional Videos
Kevin Qinghong Lin, Linjie Li, Difei Gao, Qinchen WU, Mingyi Yan, Zhengyuan Yang, Lijuan Wang, Mike Zheng Shou
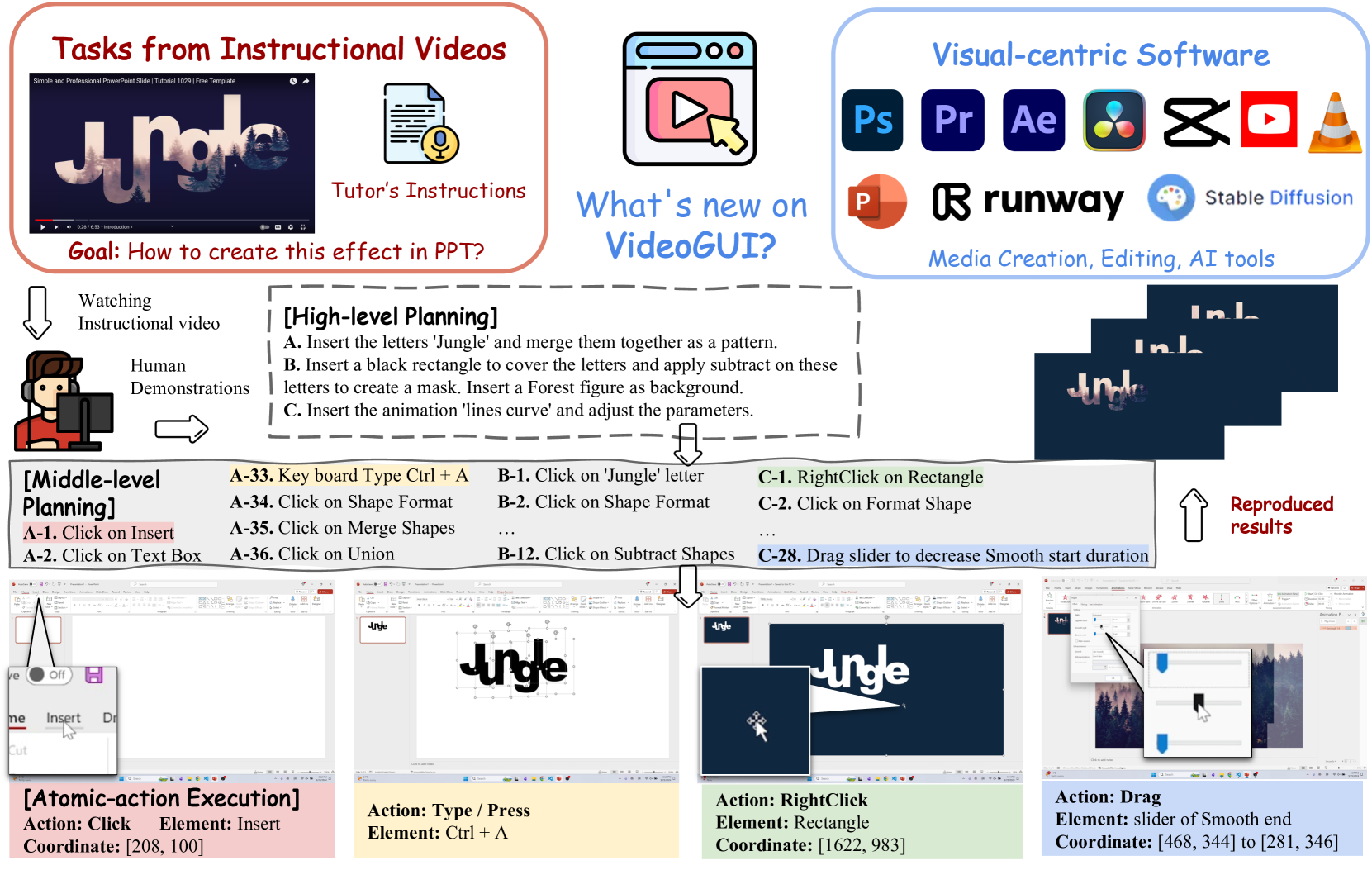
Graphical User Interface (GUI) automation holds significant promise for enhancing human productivity by assisting with computer tasks. Existing task formulations primarily focus on simple tasks that can be specified by a single, language-only instruction, such as Insert a new slide. In this work, we introduce VideoGUI, a novel multi-modal benchmark designed to evaluate GUI assistants on visual-centric GUI tasks. Sourced from high-quality web instructional videos, our benchmark focuses on tasks involving professional and novel software (e.g., Adobe Photoshop or Stable Diffusion WebUI) and complex activities (e.g., video editing). VideoGUI evaluates GUI assistants through a hierarchical process, allowing for identification of the specific levels at which they may fail: (i) high-level planning: reconstruct procedural subtasks from visual conditions without language descriptions; (ii) middle-level planning: generate sequences of precise action narrations based on visual state (i.e., screenshot) and goals; (iii) atomic action execution: perform specific actions such as accurately clicking designated elements. For each level, we design evaluation metrics across individual dimensions to provide clear signals, such as individual performance in clicking, dragging, typing, and scrolling for atomic action execution. Our evaluation on VideoGUI reveals that even the SoTA large multimodal model GPT4o performs poorly on visual-centric GUI tasks, especially for high-level planning.
Read more6/17/2024

0
GUI Action Narrator: Where and When Did That Action Take Place?
Qinchen Wu, Difei Gao, Kevin Qinghong Lin, Zhuoyu Wu, Xiangwu Guo, Peiran Li, Weichen Zhang, Hengxu Wang, Mike Zheng Shou
The advent of Multimodal LLMs has significantly enhanced image OCR recognition capabilities, making GUI automation a viable reality for increasing efficiency in digital tasks. One fundamental aspect of developing a GUI automation system is understanding primitive GUI actions. This comprehension is crucial as it enables agents to learn from user demonstrations, an essential element of automation. To rigorously evaluate such capabilities, we developed a video captioning benchmark for GUI actions, comprising 4,189 diverse video captioning samples. This task presents unique challenges compared to natural scene video captioning: 1) GUI screenshots typically contain denser information than natural scenes, and 2) events within GUIs are subtler and occur more rapidly, requiring precise attention to the appropriate time span and spatial region for accurate understanding. To address these challenges, we introduce our GUI action dataset textbf{Act2Cap} as well as a simple yet effective framework, textbf{GUI Narrator}, for GUI video captioning that utilizes the cursor as a visual prompt to enhance the interpretation of high-resolution screenshots. Specifically, a cursor detector is trained on our dataset, and a multimodal LLM model with mechanisms for selecting keyframes and key regions generates the captions. Experimental results indicate that even for today's most advanced multimodal models, such as GPT-4o, the task remains highly challenging. Additionally, our evaluations show that our strategy effectively enhances model performance, whether integrated into the fine-tuning of open-source models or employed as a prompting strategy in closed-source models.
Read more6/21/2024
👁️
0
You Only Look at Screens: Multimodal Chain-of-Action Agents
Zhuosheng Zhang, Aston Zhang
Autonomous graphical user interface (GUI) agents aim to facilitate task automation by interacting with the user interface without manual intervention. Recent studies have investigated eliciting the capabilities of large language models (LLMs) for effective engagement in diverse environments. To align with the input-output requirement of LLMs, most existing approaches are developed under a sandbox setting where they rely on external tools and application-specific APIs to parse the environment into textual elements and interpret the predicted actions. Consequently, those approaches often grapple with inference inefficiency and error propagation risks. To mitigate the challenges, we introduce Auto-GUI, a multimodal solution that directly interacts with the interface, bypassing the need for environment parsing or reliance on application-dependent APIs. Moreover, we propose a chain-of-action technique -- leveraging a series of intermediate previous action histories and future action plans -- to help the agent decide what action to execute. We evaluate our approach on a new device-control benchmark AITW with 30$K$ unique instructions, spanning multi-step tasks such as application operation, web searching, and web shopping. Experimental results show that Auto-GUI achieves state-of-the-art performance with an action type prediction accuracy of 90% and an overall action success rate of 74%. Code is publicly available at https://github.com/cooelf/Auto-GUI.
Read more6/10/2024

0
GUICourse: From General Vision Language Models to Versatile GUI Agents
Wentong Chen, Junbo Cui, Jinyi Hu, Yujia Qin, Junjie Fang, Yue Zhao, Chongyi Wang, Jun Liu, Guirong Chen, Yupeng Huo, Yuan Yao, Yankai Lin, Zhiyuan Liu, Maosong Sun
Utilizing Graphic User Interface (GUI) for human-computer interaction is essential for accessing a wide range of digital tools. Recent advancements in Vision Language Models (VLMs) highlight the compelling potential to develop versatile agents to help humans finish GUI navigation tasks. However, current VLMs are challenged in terms of fundamental abilities (OCR and grounding) and GUI knowledge (the functions and control methods of GUI elements), preventing them from becoming practical GUI agents. To solve these challenges, we contribute GUICourse, a suite of datasets to train visual-based GUI agents from general VLMs. First, we introduce the GUIEnv dataset to strengthen the OCR and grounding capabilities of VLMs. Then, we introduce the GUIAct and GUIChat datasets to enrich their knowledge of GUI components and interactions. Experiments demonstrate that our GUI agents have better performance on common GUI tasks than their baseline VLMs. Even the small-size GUI agent (with 3.1B parameters) can still work well on single-step and multi-step GUI tasks. Finally, we analyze the different varieties in the training stage of this agent by ablation study. Our source codes and datasets are released at https://github.com/yiye3/GUICourse.
Read more6/18/2024