VideoQA-SC: Adaptive Semantic Communication for Video Question Answering
2406.18538
0
0

Abstract
Although semantic communication (SC) has shown its potential in efficiently transmitting multi-modal data such as text, speeches and images, SC for videos has focused primarily on pixel-level reconstruction. However, these SC systems may be suboptimal for downstream intelligent tasks. Moreover, SC systems without pixel-level video reconstruction present advantages by achieving higher bandwidth efficiency and real-time performance of various intelligent tasks. The difficulty in such system design lies in the extraction of task-related compact semantic representations and their accurate delivery over noisy channels. In this paper, we propose an end-to-end SC system for video question answering (VideoQA) tasks called VideoQA-SC. Our goal is to accomplish VideoQA tasks directly based on video semantics over noisy or fading wireless channels, bypassing the need for video reconstruction at the receiver. To this end, we develop a spatiotemporal semantic encoder for effective video semantic extraction, and a learning-based bandwidth-adaptive deep joint source-channel coding (DJSCC) scheme for efficient and robust video semantic transmission. Experiments demonstrate that VideoQA-SC outperforms traditional and advanced DJSCC-based SC systems that rely on video reconstruction at the receiver under a wide range of channel conditions and bandwidth constraints. In particular, when the signal-to-noise ratio is low, VideoQA-SC can improve the answer accuracy by 5.17% while saving almost 99.5% of the bandwidth at the same time, compared with the advanced DJSCC-based SC system. Our results show the great potential of task-oriented SC system design for video applications.
Create account to get full access
Overview
- The provided paper presents a novel approach called VideoQA-SC for adaptive semantic communication in video question answering tasks.
- The system utilizes a transmitter-receiver framework that adaptively selects semantic information to transmit based on the given question, in order to improve the efficiency and accuracy of video question answering.
- The paper explores techniques for encoding and controlling global semantics in long-form videos, as well as learning compositional spatio-temporal representations for neural-symbolic video question answering.
Plain English Explanation
The paper describes a new system called VideoQA-SC that aims to improve the way computers answer questions about videos. Traditionally, video question answering systems try to extract and transmit as much information as possible about the video, but this can be inefficient and lead to errors.
VideoQA-SC takes a different approach - it adaptively selects and transmits only the most relevant semantic information needed to answer a given question. This is like a person listening carefully to a question, and then only explaining the key details from a video that are necessary to provide a good answer, rather than giving a long, detailed description of everything in the video.
The system has a transmitter component that analyzes the video and the question, and then decides what semantic information (like objects, actions, relationships) is most important to communicate to the receiver. The receiver then uses this targeted information to generate the final answer. This adaptive communication is designed to be more efficient and accurate than simply transmitting everything about the video.
The paper also explores techniques for encoding and controlling the global semantics of long videos, as well as learning compositional spatio-temporal representations for video question answering. These methods aim to allow the system to understand and reason about the overall meaning and structure of the video, not just individual details.
Technical Explanation
The core of the VideoQA-SC system is a transmitter-receiver framework for adaptive semantic communication. The transmitter analyzes the input video and question, and selects the most relevant semantic information to transmit to the receiver. This is done using attention mechanisms that focus on the aspects of the video most important for answering the specific question.
The transmitter encodes the global semantics of the long-form video, capturing the overall meaning and structure, not just local details. It then selectively transmits this semantic information based on the given question.
The receiver takes the transmitted semantic information and uses it, along with the question, to generate the final answer. The system learns compositional spatio-temporal representations to reason about the video content in a structured way.
Experiments show that this adaptive semantic communication approach outperforms baseline video question answering methods that transmit all available information about the video. The targeted transmission of relevant semantics improves both the efficiency and accuracy of the system.
Critical Analysis
The paper presents a thoughtful approach to video question answering, but there are a few potential limitations and areas for further research:
-
The system's performance is still dependent on the quality of the underlying video understanding models. Improvements to video-language alignment and reasoning capabilities could further boost the system's accuracy.
-
The adaptive communication is driven by the question, but there may be value in also considering the user's background knowledge or context when selecting what semantic information to transmit.
-
The paper focuses on open-ended video question answering, but the adaptive semantic communication approach could potentially be extended to other video understanding tasks, like agent-driven generative semantic communication for remote surveillance.
Overall, the VideoQA-SC system represents an interesting step forward in making video question answering more efficient and effective. Further research exploring the limits and potential extensions of this adaptive semantic communication approach could yield valuable insights.
Conclusion
The VideoQA-SC paper presents a novel framework for adaptive semantic communication in video question answering tasks. By selectively transmitting the most relevant semantic information based on the given question, the system is able to improve both the efficiency and accuracy of video question answering compared to traditional approaches.
The techniques explored in this paper, including encoding and controlling global video semantics and learning compositional spatio-temporal representations, demonstrate the value of structured video understanding for tasks like question answering. As video data continues to grow, such advancements in adaptive and efficient video-language communication will become increasingly important.
While the current system has some limitations, the overall approach of VideoQA-SC represents a promising direction for making video question answering more practical and scalable. Further research building on these ideas could lead to significant improvements in our ability to effectively extract meaning and knowledge from video data.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Agent-driven Generative Semantic Communication for Remote Surveillance
Wanting Yang, Zehui Xiong, Yanli Yuan, Wenchao Jiang, Tony Q. S. Quek, Merouane Debbah
0
0
In the era of 6G, featuring compelling visions of intelligent transportation system, digital twins, remote surveillance is poised to become a ubiquitous practice. The substantial data volume and frequent updates present challenges in wireless networks. To address this, we propose a novel agent-driven generative semantic communication (A-GSC) framework based on reinforcement learning. In contrast to the existing research on semantic communication (SemCom), which mainly focuses on semantic compression or semantic sampling, we seamlessly cascade both together by jointly considering the intrinsic attributes of source information and the contextual information regarding the task. Notably, the introduction of the generative artificial intelligence (GAI) enables the independent design of semantic encoders and decoders. In this work, we develop an agent-assisted semantic encoder leveraging the knowledge based soft actor-critic algorithm, which can track the semantic changes, channel condition, and sampling intervals, so as to perform adaptive semantic sampling. Accordingly, we design a semantic decoder with both predictive and generative capabilities, which consists of two tailored modules. Moreover, the effectiveness of the designed models has been verified based on the dataset generated from CDNet2014, and the performance gain of the overall A-GSC framework in both energy saving and reconstruction accuracy have been demonstrated.
4/11/2024

New!Visual Language Model based Cross-modal Semantic Communication Systems
Feibo Jiang, Chuanguo Tang, Li Dong, Kezhi Wang, Kun Yang, Cunhua Pan
0
0
Semantic Communication (SC) has emerged as a novel communication paradigm in recent years, successfully transcending the Shannon physical capacity limits through innovative semantic transmission concepts. Nevertheless, extant Image Semantic Communication (ISC) systems face several challenges in dynamic environments, including low semantic density, catastrophic forgetting, and uncertain Signal-to-Noise Ratio (SNR). To address these challenges, we propose a novel Vision-Language Model-based Cross-modal Semantic Communication (VLM-CSC) system. The VLM-CSC comprises three novel components: (1) Cross-modal Knowledge Base (CKB) is used to extract high-density textual semantics from the semantically sparse image at the transmitter and reconstruct the original image based on textual semantics at the receiver. The transmission of high-density semantics contributes to alleviating bandwidth pressure. (2) Memory-assisted Encoder and Decoder (MED) employ a hybrid long/short-term memory mechanism, enabling the semantic encoder and decoder to overcome catastrophic forgetting in dynamic environments when there is a drift in the distribution of semantic features. (3) Noise Attention Module (NAM) employs attention mechanisms to adaptively adjust the semantic coding and the channel coding based on SNR, ensuring the robustness of the CSC system. The experimental simulations validate the effectiveness, adaptability, and robustness of the CSC system.
7/2/2024

Listen Then See: Video Alignment with Speaker Attention
Aviral Agrawal (Carnegie Mellon University), Carlos Mateo Samudio Lezcano (Carnegie Mellon University), Iqui Balam Heredia-Marin (Carnegie Mellon University), Prabhdeep Singh Sethi (Carnegie Mellon University)
0
0
Video-based Question Answering (Video QA) is a challenging task and becomes even more intricate when addressing Socially Intelligent Question Answering (SIQA). SIQA requires context understanding, temporal reasoning, and the integration of multimodal information, but in addition, it requires processing nuanced human behavior. Furthermore, the complexities involved are exacerbated by the dominance of the primary modality (text) over the others. Thus, there is a need to help the task's secondary modalities to work in tandem with the primary modality. In this work, we introduce a cross-modal alignment and subsequent representation fusion approach that achieves state-of-the-art results (82.06% accuracy) on the Social IQ 2.0 dataset for SIQA. Our approach exhibits an improved ability to leverage the video modality by using the audio modality as a bridge with the language modality. This leads to enhanced performance by reducing the prevalent issue of language overfitting and resultant video modality bypassing encountered by current existing techniques. Our code and models are publicly available at https://github.com/sts-vlcc/sts-vlcc
4/23/2024
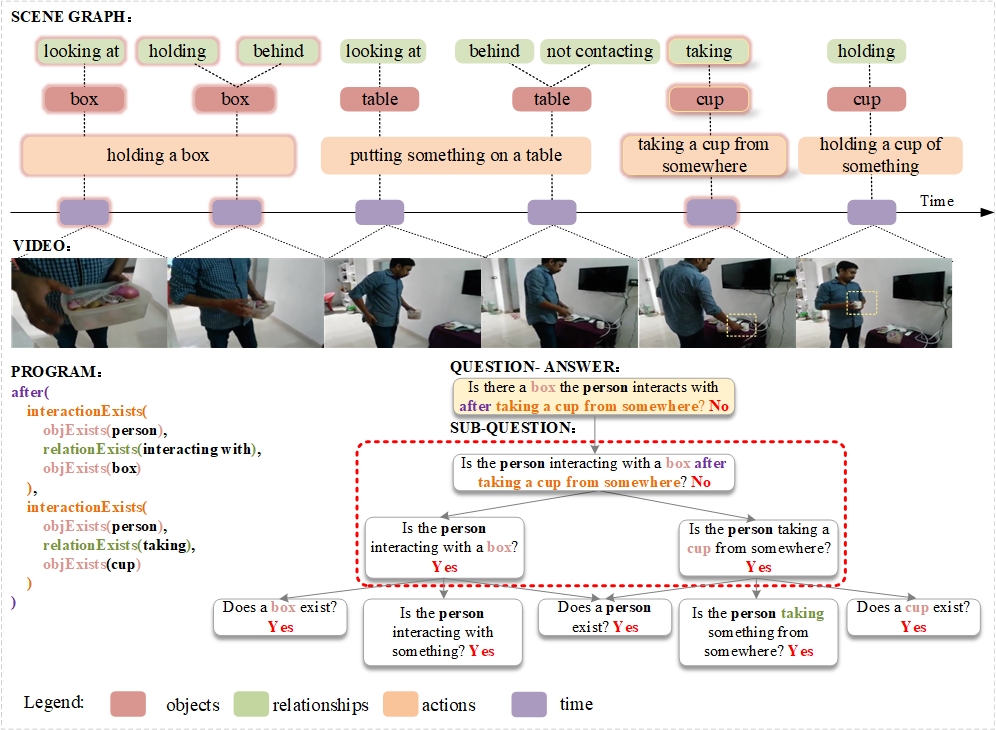
Neural-Symbolic VideoQA: Learning Compositional Spatio-Temporal Reasoning for Real-world Video Question Answering
Lili Liang, Guanglu Sun, Jin Qiu, Lizhong Zhang
0
0
Compositional spatio-temporal reasoning poses a significant challenge in the field of video question answering (VideoQA). Existing approaches struggle to establish effective symbolic reasoning structures, which are crucial for answering compositional spatio-temporal questions. To address this challenge, we propose a neural-symbolic framework called Neural-Symbolic VideoQA (NS-VideoQA), specifically designed for real-world VideoQA tasks. The uniqueness and superiority of NS-VideoQA are two-fold: 1) It proposes a Scene Parser Network (SPN) to transform static-dynamic video scenes into Symbolic Representation (SR), structuralizing persons, objects, relations, and action chronologies. 2) A Symbolic Reasoning Machine (SRM) is designed for top-down question decompositions and bottom-up compositional reasonings. Specifically, a polymorphic program executor is constructed for internally consistent reasoning from SR to the final answer. As a result, Our NS-VideoQA not only improves the compositional spatio-temporal reasoning in real-world VideoQA task, but also enables step-by-step error analysis by tracing the intermediate results. Experimental evaluations on the AGQA Decomp benchmark demonstrate the effectiveness of the proposed NS-VideoQA framework. Empirical studies further confirm that NS-VideoQA exhibits internal consistency in answering compositional questions and significantly improves the capability of spatio-temporal and logical inference for VideoQA tasks.
4/8/2024