Neural-Symbolic VideoQA: Learning Compositional Spatio-Temporal Reasoning for Real-world Video Question Answering
2404.04007
0
0
Abstract
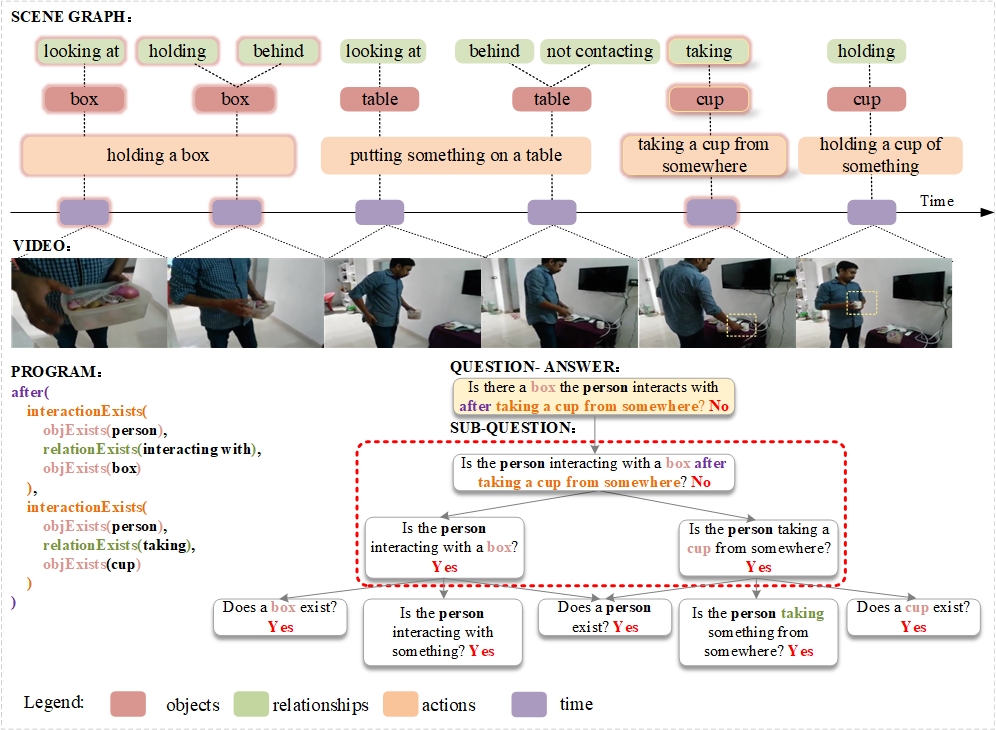
Compositional spatio-temporal reasoning poses a significant challenge in the field of video question answering (VideoQA). Existing approaches struggle to establish effective symbolic reasoning structures, which are crucial for answering compositional spatio-temporal questions. To address this challenge, we propose a neural-symbolic framework called Neural-Symbolic VideoQA (NS-VideoQA), specifically designed for real-world VideoQA tasks. The uniqueness and superiority of NS-VideoQA are two-fold: 1) It proposes a Scene Parser Network (SPN) to transform static-dynamic video scenes into Symbolic Representation (SR), structuralizing persons, objects, relations, and action chronologies. 2) A Symbolic Reasoning Machine (SRM) is designed for top-down question decompositions and bottom-up compositional reasonings. Specifically, a polymorphic program executor is constructed for internally consistent reasoning from SR to the final answer. As a result, Our NS-VideoQA not only improves the compositional spatio-temporal reasoning in real-world VideoQA task, but also enables step-by-step error analysis by tracing the intermediate results. Experimental evaluations on the AGQA Decomp benchmark demonstrate the effectiveness of the proposed NS-VideoQA framework. Empirical studies further confirm that NS-VideoQA exhibits internal consistency in answering compositional questions and significantly improves the capability of spatio-temporal and logical inference for VideoQA tasks.
Create account to get full access
Overview
- This paper proposes a novel neural-symbolic approach for video question answering (VideoQA) called Neural-Symbolic VideoQA.
- The key idea is to combine the strengths of deep learning and symbolic reasoning to enable more compositional and generalizable video understanding for real-world VideoQA tasks.
- The model learns to decompose questions into sub-tasks, reason about them through a neural network, and then aggregate the results using a symbolic reasoner.
Plain English Explanation
The paper presents a new way to approach the problem of answering questions about videos. Current video question answering (VideoQA) systems often struggle with complex, multi-part questions that require deep reasoning about the content of the video. The researchers behind this work believe that combining neural networks (which are good at learning from data) with symbolic reasoning (which is good at logical inference) can lead to more powerful and generalizable VideoQA models.
The core idea is to break down questions into smaller, more manageable sub-tasks that the neural network can handle. For example, if asked "What color is the car and how many people are in the video?", the system would first use a neural network to identify the color of the car, then use a separate module to count the number of people. These individual results would then be combined using a symbolic reasoner to produce the final answer.
By decomposing the reasoning process in this way, the researchers hope to create VideoQA systems that are more compositional (able to handle complex questions by breaking them down) and generalizable (able to apply the learned reasoning skills to new videos and questions, rather than just memorizing patterns). This could lead to significant improvements in the real-world performance of VideoQA technology.
Technical Explanation
The paper introduces a Neural-Symbolic VideoQA model that leverages both deep learning and symbolic reasoning to address the limitations of existing transformer-based VideoQA approaches.
The key components of the model are:
-
Question Decomposition: The system first analyzes the input question and breaks it down into a set of sub-tasks, such as identifying objects, counting people, or recognizing actions.
-
Neural Reasoning: For each sub-task, a neural network module is used to extract relevant information from the video and produce an intermediate result, such as the color of a car or the number of people.
-
Symbolic Aggregation: A symbolic reasoner then takes the outputs of the neural modules and combines them using logical rules to produce the final answer to the original question.
The researchers evaluate their approach on several real-world VideoQA datasets and show that it outperforms state-of-the-art transformer-based models, particularly on questions that require complex, compositional reasoning. They also demonstrate the model's ability to generalize to new videos and questions better than previous methods.
Critical Analysis
The Neural-Symbolic VideoQA approach presented in this paper is a promising step towards more robust and generalizable video understanding for question answering. By explicitly modeling the compositional nature of complex questions, the system is able to better handle the diversity and nuance of real-world VideoQA tasks.
However, the paper does not address the potential limitations of the symbolic reasoning component, such as its reliance on predefined rules and the difficulty of scaling to large, open-ended knowledge bases. Additionally, the model's performance on more open-ended, free-form questions is not thoroughly explored, and the paper does not discuss potential biases or failures modes of the system.
Further research is needed to fully understand the strengths and weaknesses of this neural-symbolic approach, as well as to explore ways to improve the compositionality and generalization of VideoQA models more broadly. Comparisons to other emerging approaches, such as learning-based reasoning or multi-modal question answering, would also help situate the contributions of this work within the larger context of video understanding research.
Conclusion
The Neural-Symbolic VideoQA model presented in this paper represents an important step towards more robust and generalizable video question answering. By combining the strengths of deep learning and symbolic reasoning, the system is able to better handle the complexity and diversity of real-world VideoQA tasks, particularly those that require compositional, multi-step reasoning.
While the paper does not address all the potential limitations of this approach, it demonstrates the value of integrating different AI paradigms to tackle challenging problems in video understanding. As the field of VideoQA continues to evolve, this work highlights the importance of exploring hybrid architectures and the potential benefits they can bring to real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Towards Truly Zero-shot Compositional Visual Reasoning with LLMs as Programmers
Aleksandar Stani'c, Sergi Caelles, Michael Tschannen
0
0
Visual reasoning is dominated by end-to-end neural networks scaled to billions of model parameters and training examples. However, even the largest models struggle with compositional reasoning, generalization, fine-grained spatial and temporal reasoning, and counting. Visual reasoning with large language models (LLMs) as controllers can, in principle, address these limitations by decomposing the task and solving subtasks by orchestrating a set of (visual) tools. Recently, these models achieved great performance on tasks such as compositional visual question answering, visual grounding, and video temporal reasoning. Nevertheless, in their current form, these models heavily rely on human engineering of in-context examples in the prompt, which are often dataset- and task-specific and require significant labor by highly skilled programmers. In this work, we present a framework that mitigates these issues by introducing spatially and temporally abstract routines and by leveraging a small number of labeled examples to automatically generate in-context examples, thereby avoiding human-created in-context examples. On a number of visual reasoning tasks, we show that our framework leads to consistent gains in performance, makes LLMs as controllers setup more robust, and removes the need for human engineering of in-context examples.
5/16/2024
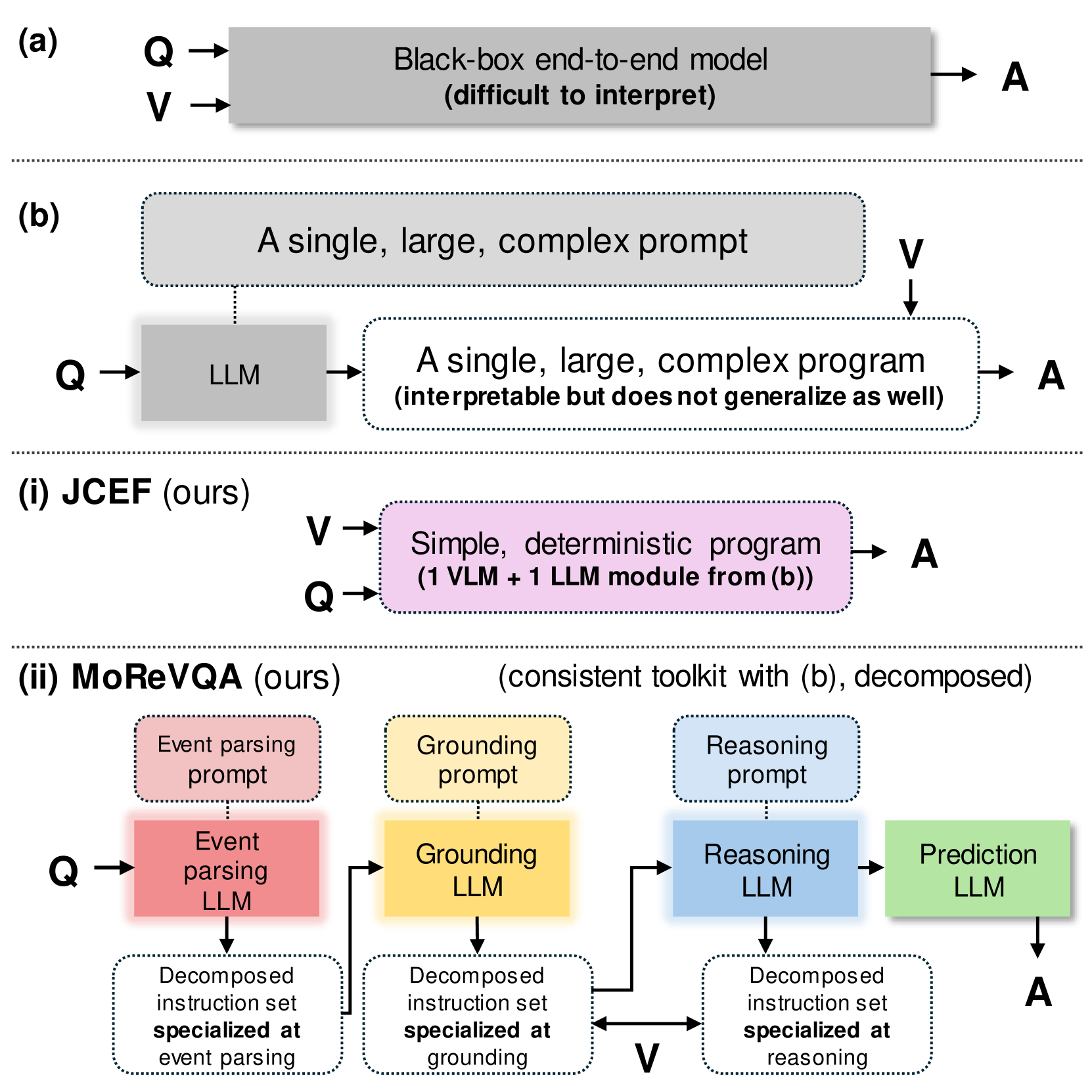
MoReVQA: Exploring Modular Reasoning Models for Video Question Answering
Juhong Min, Shyamal Buch, Arsha Nagrani, Minsu Cho, Cordelia Schmid
0
0
This paper addresses the task of video question answering (videoQA) via a decomposed multi-stage, modular reasoning framework. Previous modular methods have shown promise with a single planning stage ungrounded in visual content. However, through a simple and effective baseline, we find that such systems can lead to brittle behavior in practice for challenging videoQA settings. Thus, unlike traditional single-stage planning methods, we propose a multi-stage system consisting of an event parser, a grounding stage, and a final reasoning stage in conjunction with an external memory. All stages are training-free, and performed using few-shot prompting of large models, creating interpretable intermediate outputs at each stage. By decomposing the underlying planning and task complexity, our method, MoReVQA, improves over prior work on standard videoQA benchmarks (NExT-QA, iVQA, EgoSchema, ActivityNet-QA) with state-of-the-art results, and extensions to related tasks (grounded videoQA, paragraph captioning).
4/10/2024

New!VideoQA-SC: Adaptive Semantic Communication for Video Question Answering
Jiangyuan Guo, Wei Chen, Yuxuan Sun, Jialong Xu, Bo Ai
0
0
Although semantic communication (SC) has shown its potential in efficiently transmitting multi-modal data such as text, speeches and images, SC for videos has focused primarily on pixel-level reconstruction. However, these SC systems may be suboptimal for downstream intelligent tasks. Moreover, SC systems without pixel-level video reconstruction present advantages by achieving higher bandwidth efficiency and real-time performance of various intelligent tasks. The difficulty in such system design lies in the extraction of task-related compact semantic representations and their accurate delivery over noisy channels. In this paper, we propose an end-to-end SC system for video question answering (VideoQA) tasks called VideoQA-SC. Our goal is to accomplish VideoQA tasks directly based on video semantics over noisy or fading wireless channels, bypassing the need for video reconstruction at the receiver. To this end, we develop a spatiotemporal semantic encoder for effective video semantic extraction, and a learning-based bandwidth-adaptive deep joint source-channel coding (DJSCC) scheme for efficient and robust video semantic transmission. Experiments demonstrate that VideoQA-SC outperforms traditional and advanced DJSCC-based SC systems that rely on video reconstruction at the receiver under a wide range of channel conditions and bandwidth constraints. In particular, when the signal-to-noise ratio is low, VideoQA-SC can improve the answer accuracy by 5.17% while saving almost 99.5% of the bandwidth at the same time, compared with the advanced DJSCC-based SC system. Our results show the great potential of task-oriented SC system design for video applications.
6/28/2024

Encoding and Controlling Global Semantics for Long-form Video Question Answering
Thong Thanh Nguyen, Zhiyuan Hu, Xiaobao Wu, Cong-Duy T Nguyen, See-Kiong Ng, Anh Tuan Luu
0
0
Seeking answers effectively for long videos is essential to build video question answering (videoQA) systems. Previous methods adaptively select frames and regions from long videos to save computations. However, this fails to reason over the whole sequence of video, leading to sub-optimal performance. To address this problem, we introduce a state space layer (SSL) into multi-modal Transformer to efficiently integrate global semantics of the video, which mitigates the video information loss caused by frame and region selection modules. Our SSL includes a gating unit to enable controllability over the flow of global semantics into visual representations. To further enhance the controllability, we introduce a cross-modal compositional congruence (C^3) objective to encourage global semantics aligned with the question. To rigorously evaluate long-form videoQA capacity, we construct two new benchmarks Ego-QA and MAD-QA featuring videos of considerably long length, i.e. 17.5 minutes and 1.9 hours, respectively. Extensive experiments demonstrate the superiority of our framework on these new as well as existing datasets.
5/31/2024