Listen Then See: Video Alignment with Speaker Attention
2404.13530
0
0

Abstract
Video-based Question Answering (Video QA) is a challenging task and becomes even more intricate when addressing Socially Intelligent Question Answering (SIQA). SIQA requires context understanding, temporal reasoning, and the integration of multimodal information, but in addition, it requires processing nuanced human behavior. Furthermore, the complexities involved are exacerbated by the dominance of the primary modality (text) over the others. Thus, there is a need to help the task's secondary modalities to work in tandem with the primary modality. In this work, we introduce a cross-modal alignment and subsequent representation fusion approach that achieves state-of-the-art results (82.06% accuracy) on the Social IQ 2.0 dataset for SIQA. Our approach exhibits an improved ability to leverage the video modality by using the audio modality as a bridge with the language modality. This leads to enhanced performance by reducing the prevalent issue of language overfitting and resultant video modality bypassing encountered by current existing techniques. Our code and models are publicly available at https://github.com/sts-vlcc/sts-vlcc
Create account to get full access
Overview
- This paper presents a novel approach for aligning audio and visual information in videos, with a focus on speaker attention.
- The proposed method, called "Listen Then See", aims to improve upon existing audio-visual alignment techniques by leveraging the relationship between the speaker's voice and their corresponding appearance in the video.
- The research explores the benefits of this speaker-aware alignment for downstream tasks such as video question answering and spoken question answering.
Plain English Explanation
The paper introduces a new way to align audio and video information in videos, particularly focusing on the relationship between a speaker's voice and their appearance on screen. The key idea is that by understanding how the speaker's voice corresponds to their movements and facial expressions, we can improve the overall alignment of the audio and visual data.
This is important because many applications, like video question answering and spoken question answering, rely on being able to accurately match the audio and visual information in a video. By taking the speaker's attention into account, the proposed "Listen Then See" method aims to achieve better alignment and, in turn, improve the performance of these downstream tasks.
Imagine you're watching a video of someone giving a speech. The audio of their voice and the visuals of their face and body movements should be closely synchronized for the best experience. The "Listen Then See" approach tries to capture this connection between the speaker's voice and appearance to achieve more accurate alignment, which could lead to better cross-modal understanding and visual question answering performance.
Technical Explanation
The paper proposes a novel audio-visual alignment model called "Listen Then See" that leverages speaker attention to improve the synchronization of audio and visual information in videos. The key innovation is the incorporation of a speaker attention module that learns to associate the speaker's voice with their corresponding appearance in the video.
The model consists of several main components:
- Audio Encoder: Encodes the audio input into a representation.
- Visual Encoder: Encodes the visual input into a representation.
- Speaker Attention Module: Learns to attend to the relevant visual features based on the audio input, capturing the relationship between the speaker's voice and their appearance.
- Alignment Module: Aligns the audio and visual representations using the speaker-aware attention information.
The paper demonstrates the effectiveness of the "Listen Then See" model on various audio-visual tasks, including video question answering and spoken question answering. The results show that the speaker-aware alignment approach outperforms previous state-of-the-art methods, highlighting the benefits of considering the speaker's attention in aligning audio and visual modalities.
Critical Analysis
The paper presents a compelling approach to audio-visual alignment, but there are a few potential limitations and areas for further research:
-
Generalization to Non-Speaker Scenarios: While the focus on speaker attention is a key strength of the proposed method, it may not be as effective for videos without a prominent speaker, such as those featuring multiple speakers or non-verbal content. Exploring the model's performance in these more diverse scenarios could be an interesting direction for future work.
-
Computational Efficiency: The addition of the speaker attention module may increase the overall computational complexity of the model, which could be a concern for real-time or resource-constrained applications. Investigating ways to optimize the model's efficiency without sacrificing performance would be a valuable contribution.
-
Interpretability and Explainability: The paper does not provide a detailed analysis of the learned speaker attention mechanisms and how they contribute to the improved alignment. Gaining a deeper understanding of the inner workings of the model could lead to valuable insights and inform future research in this area.
-
Potential Biases and Ethical Considerations: As with any AI system, there may be inherent biases in the data or model architecture that could lead to unintended consequences. Careful evaluation of the system's fairness and potential societal impacts would be an important consideration for real-world deployment.
Overall, the "Listen Then See" approach represents an interesting and promising step forward in audio-visual alignment, with potential applications in cross-modal understanding, visual question answering, and enhancing visual question answering. Further research addressing the identified limitations and exploring the model's broader applicability could lead to significant advancements in this field.
Conclusion
The "Listen Then See" paper presents a novel approach to audio-visual alignment that leverages speaker attention to improve the synchronization of audio and visual information in videos. By capturing the relationship between a speaker's voice and their corresponding appearance, the proposed model demonstrates superior performance on tasks like video question answering and spoken question answering compared to previous state-of-the-art methods.
While the paper offers a compelling solution, there are opportunities for further research to address potential limitations, such as the model's generalization to non-speaker scenarios, computational efficiency, and interpretability. Addressing these areas could lead to more robust and versatile audio-visual alignment models with a broad range of applications in cross-modal understanding and multimodal reasoning.
Overall, the "Listen Then See" research represents an important step forward in the field of audio-visual alignment, showcasing the benefits of incorporating speaker-aware attention mechanisms and opening up new avenues for exploration and advancement in this rapidly evolving area of artificial intelligence.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

ViLA: Efficient Video-Language Alignment for Video Question Answering
Xijun Wang, Junbang Liang, Chun-Kai Wang, Kenan Deng, Yu Lou, Ming Lin, Shan Yang
0
0
In this work, we propose an efficient Video-Language Alignment (ViLA) network. Our ViLA model addresses both efficient frame sampling and effective cross-modal alignment in a unified way. In our ViLA network, we design a new learnable text-guided Frame-Prompter together with a new cross-modal distillation (QFormer-Distiller) module. Pre-trained large image-language models have shown promising results on problems such as visual question answering (VQA). However, how to efficiently and effectively sample video frames when adapting pre-trained large image-language model to video-language alignment is still the major challenge. Compared with prior work, our ViLA model demonstrates the capability of selecting key frames with critical contents, thus improving the video-language alignment accuracy while reducing the inference latency +3.3% on NExT-QA Temporal with 3.0X speed up). Overall, our ViLA network outperforms the state-of-the-art methods on the video question-answering benchmarks: +4.6% on STAR Interaction, +2.2% on STAR average with 3.0X speed up, ours 2-frames out-perform SeViLA 4-frames on the VLEP dataset with 4.2X speed-up.
4/30/2024

New!VideoQA-SC: Adaptive Semantic Communication for Video Question Answering
Jiangyuan Guo, Wei Chen, Yuxuan Sun, Jialong Xu, Bo Ai
0
0
Although semantic communication (SC) has shown its potential in efficiently transmitting multi-modal data such as text, speeches and images, SC for videos has focused primarily on pixel-level reconstruction. However, these SC systems may be suboptimal for downstream intelligent tasks. Moreover, SC systems without pixel-level video reconstruction present advantages by achieving higher bandwidth efficiency and real-time performance of various intelligent tasks. The difficulty in such system design lies in the extraction of task-related compact semantic representations and their accurate delivery over noisy channels. In this paper, we propose an end-to-end SC system for video question answering (VideoQA) tasks called VideoQA-SC. Our goal is to accomplish VideoQA tasks directly based on video semantics over noisy or fading wireless channels, bypassing the need for video reconstruction at the receiver. To this end, we develop a spatiotemporal semantic encoder for effective video semantic extraction, and a learning-based bandwidth-adaptive deep joint source-channel coding (DJSCC) scheme for efficient and robust video semantic transmission. Experiments demonstrate that VideoQA-SC outperforms traditional and advanced DJSCC-based SC systems that rely on video reconstruction at the receiver under a wide range of channel conditions and bandwidth constraints. In particular, when the signal-to-noise ratio is low, VideoQA-SC can improve the answer accuracy by 5.17% while saving almost 99.5% of the bandwidth at the same time, compared with the advanced DJSCC-based SC system. Our results show the great potential of task-oriented SC system design for video applications.
6/28/2024
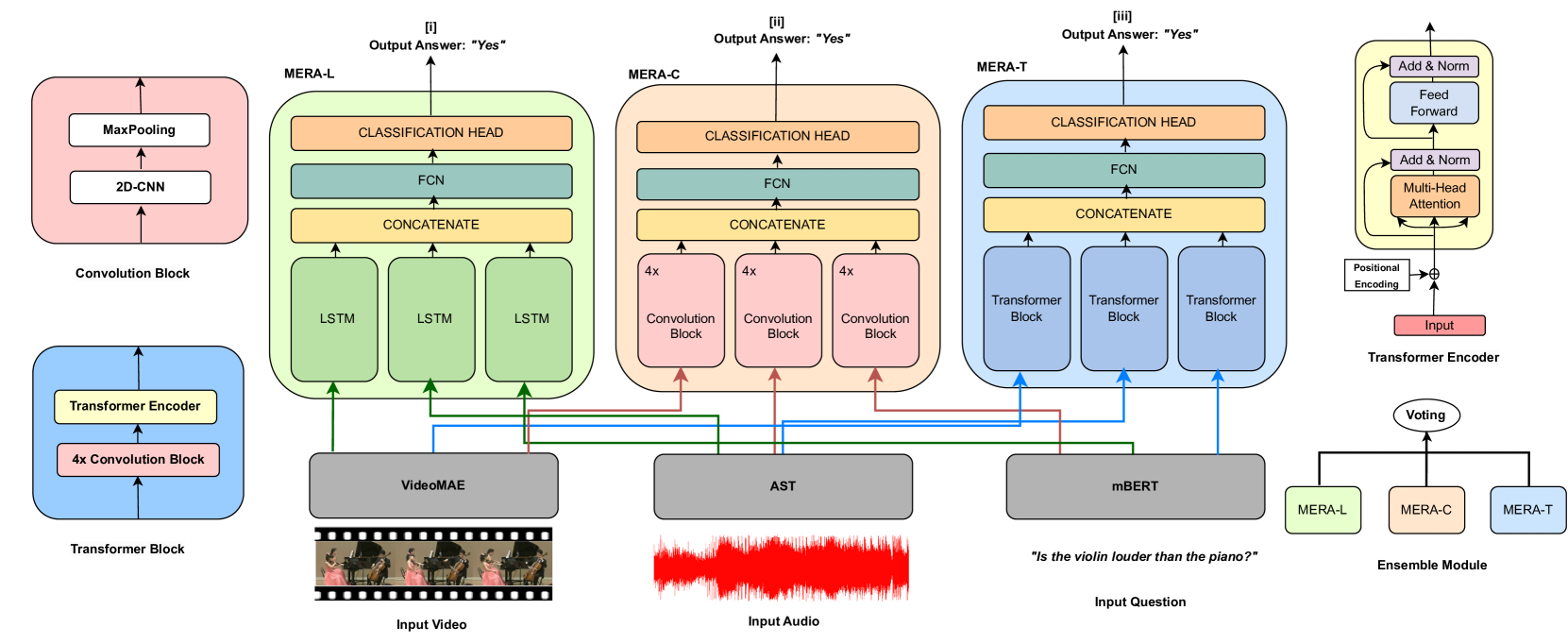
Towards Multilingual Audio-Visual Question Answering
Orchid Chetia Phukan, Priyabrata Mallick, Swarup Ranjan Behera, Aalekhya Satya Narayani, Arun Balaji Buduru, Rajesh Sharma
0
0
In this paper, we work towards extending Audio-Visual Question Answering (AVQA) to multilingual settings. Existing AVQA research has predominantly revolved around English and replicating it for addressing AVQA in other languages requires a substantial allocation of resources. As a scalable solution, we leverage machine translation and present two multilingual AVQA datasets for eight languages created from existing benchmark AVQA datasets. This prevents extra human annotation efforts of collecting questions and answers manually. To this end, we propose, MERA framework, by leveraging state-of-the-art (SOTA) video, audio, and textual foundation models for AVQA in multiple languages. We introduce a suite of models namely MERA-L, MERA-C, MERA-T with varied model architectures to benchmark the proposed datasets. We believe our work will open new research directions and act as a reference benchmark for future works in multilingual AVQA.
6/14/2024
👀
Enhancing Visual-Language Modality Alignment in Large Vision Language Models via Self-Improvement
Xiyao Wang, Jiuhai Chen, Zhaoyang Wang, Yuhang Zhou, Yiyang Zhou, Huaxiu Yao, Tianyi Zhou, Tom Goldstein, Parminder Bhatia, Furong Huang, Cao Xiao
0
0
Large vision-language models (LVLMs) have achieved impressive results in various visual question-answering and reasoning tasks through vision instruction tuning on specific datasets. However, there is still significant room for improvement in the alignment between visual and language modalities. Previous methods to enhance this alignment typically require external models or data, heavily depending on their capabilities and quality, which inevitably sets an upper bound on performance. In this paper, we propose SIMA, a framework that enhances visual and language modality alignment through self-improvement, eliminating the needs for external models or data. SIMA leverages prompts from existing vision instruction tuning datasets to self-generate responses and employs an in-context self-critic mechanism to select response pairs for preference tuning. The key innovation is the introduction of three vision metrics during the in-context self-critic process, which can guide the LVLM in selecting responses that enhance image comprehension. Through experiments across 14 hallucination and comprehensive benchmarks, we demonstrate that SIMA not only improves model performance across all benchmarks but also achieves superior modality alignment, outperforming previous approaches.
6/11/2024