VMambaMorph: a Visual Mamba-based Framework with Cross-Scan Module for Deformable 3D Image Registration

0

Sign in to get full access
Overview
- This paper introduces a visual framework called VMambaMorph for deformable 3D image registration, which is the process of aligning two or more images of the same scene or object.
- The framework is based on the Visual Mamba (VMamba) model, a state-space representation for image processing tasks.
- The paper also presents a cross-scan module that helps improve the registration process by considering information across different image slices or scans.
Plain English Explanation
VMambaMorph: a Visual Mamba-based Framework with Cross-Scan Module for Deformable 3D Image Registration is a research paper that describes a new tool for aligning 3D medical images, like CT scans or MRI images. Aligning these images is important for tasks like tracking changes over time or combining information from different scans.
The key idea is to use a model called Visual Mamba (VMamba), which is a way of representing images as a series of states or steps. This allows the alignment process to consider the 3D structure of the images, not just the 2D slices. The paper also introduces a "cross-scan" module, which looks at information across different slices or scans to improve the alignment.
Overall, this new framework, called VMambaMorph, aims to make the process of aligning 3D medical images more accurate and efficient, which could have important applications in medical imaging and other areas that rely on precise image registration.
Technical Explanation
VMambaMorph: a Visual Mamba-based Framework with Cross-Scan Module for Deformable 3D Image Registration builds on the Visual Mamba (VMamba) model, a state-space representation for image processing tasks. The framework represents 3D images as a sequence of 2D slices or scans, and uses this structure to perform deformable registration, aligning the images by warping and deforming them.
A key innovation is the introduction of a "cross-scan" module, which considers information across the different slices or scans, rather than just within each individual slice. This helps the system better understand the 3D structure of the images and can improve the accuracy of the registration process.
The paper evaluates the VMambaMorph framework on several 3D medical imaging datasets, comparing its performance to other state-of-the-art registration methods. The results demonstrate the effectiveness of the approach, particularly the cross-scan module, in achieving accurate 3D image alignment.
Critical Analysis
The VMambaMorph framework introduces an interesting and potentially valuable approach to 3D image registration, leveraging the state-space structure of the VMamba model and incorporating cross-scan information. However, the paper does not provide a thorough exploration of the limitations or potential drawbacks of the method.
For example, the computational complexity of the cross-scan module and its impact on runtime performance is not discussed. Additionally, the paper does not address how the framework might handle cases with significant occlusions or large deformations between the images being registered.
Further research could also investigate the generalizability of the VMambaMorph approach to other types of 3D imaging data, beyond the medical datasets used in the current evaluation. Exploring the integration of the framework with other Mamba-based models could also lead to interesting synergies and improvements.
Conclusion
VMambaMorph: a Visual Mamba-based Framework with Cross-Scan Module for Deformable 3D Image Registration presents a novel framework for aligning 3D medical images, leveraging the state-space structure of the Visual Mamba model and introducing a cross-scan module to improve registration accuracy. The results demonstrate the effectiveness of the approach, which could have important applications in medical imaging and other fields that rely on precise image alignment.
While the paper provides a solid technical foundation, further research is needed to explore the limitations, scalability, and broader applicability of the VMambaMorph framework. Nonetheless, this work represents an interesting and potentially impactful contribution to the field of 3D image registration.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
VMambaMorph: a Visual Mamba-based Framework with Cross-Scan Module for Deformable 3D Image Registration
Ziyang Wang, Jian-Qing Zheng, Chao Ma, Tao Guo
Image registration, a critical process in medical imaging, involves aligning different sets of medical imaging data into a single unified coordinate system. Deep learning networks, such as the Convolutional Neural Network (CNN)-based VoxelMorph, Vision Transformer (ViT)-based TransMorph, and State Space Model (SSM)-based MambaMorph, have demonstrated effective performance in this domain. The recent Visual State Space Model (VMamba), which incorporates a cross-scan module with SSM, has exhibited promising improvements in modeling global-range dependencies with efficient computational cost in computer vision tasks. This paper hereby introduces an exploration of VMamba with image registration, named VMambaMorph. This novel hybrid VMamba-CNN network is designed specifically for 3D image registration. Utilizing a U-shaped network architecture, VMambaMorph computes the deformation field based on target and source volumes. The VMamba-based block with 2D cross-scan module is redesigned for 3D volumetric feature processing. To overcome the complex motion and structure on multi-modality images, we further propose a fine-tune recursive registration framework. We validate VMambaMorph using a public benchmark brain MR-CT registration dataset, comparing its performance against current state-of-the-art methods. The results indicate that VMambaMorph achieves competitive registration quality. The code for VMambaMorph with all baseline methods is available on GitHub.
Read more4/16/2024
0
VMamba: Visual State Space Model
Yue Liu, Yunjie Tian, Yuzhong Zhao, Hongtian Yu, Lingxi Xie, Yaowei Wang, Qixiang Ye, Yunfan Liu
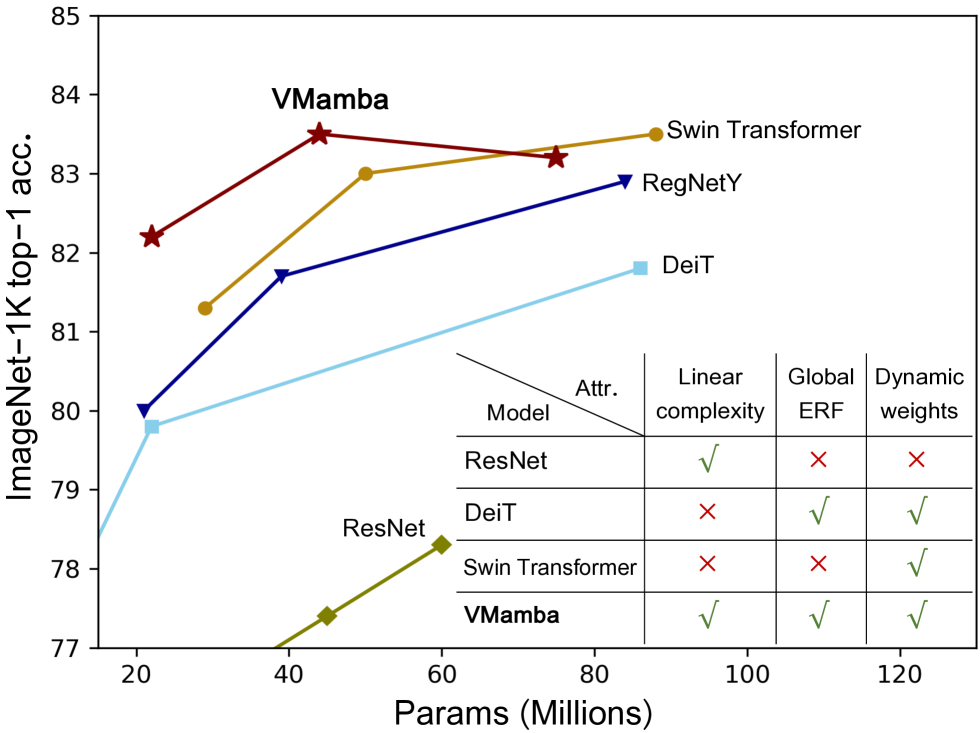
Designing computationally efficient network architectures persists as an ongoing necessity in computer vision. In this paper, we transplant Mamba, a state-space language model, into VMamba, a vision backbone that works in linear time complexity. At the core of VMamba lies a stack of Visual State-Space (VSS) blocks with the 2D Selective Scan (SS2D) module. By traversing along four scanning routes, SS2D helps bridge the gap between the ordered nature of 1D selective scan and the non-sequential structure of 2D vision data, which facilitates the gathering of contextual information from various sources and perspectives. Based on the VSS blocks, we develop a family of VMamba architectures and accelerate them through a succession of architectural and implementation enhancements. Extensive experiments showcase VMamba's promising performance across diverse visual perception tasks, highlighting its advantages in input scaling efficiency compared to existing benchmark models. Source code is available at https://github.com/MzeroMiko/VMamba.
Read more5/28/2024

0
LoG-VMamba: Local-Global Vision Mamba for Medical Image Segmentation
Trung Dinh Quoc Dang, Huy Hoang Nguyen, Aleksei Tiulpin
Mamba, a State Space Model (SSM), has recently shown competitive performance to Convolutional Neural Networks (CNNs) and Transformers in Natural Language Processing and general sequence modeling. Various attempts have been made to adapt Mamba to Computer Vision tasks, including medical image segmentation (MIS). Vision Mamba (VM)-based networks are particularly attractive due to their ability to achieve global receptive fields, similar to Vision Transformers, while also maintaining linear complexity in the number of tokens. However, the existing VM models still struggle to maintain both spatially local and global dependencies of tokens in high dimensional arrays due to their sequential nature. Employing multiple and/or complicated scanning strategies is computationally costly, which hinders applications of SSMs to high-dimensional 2D and 3D images that are common in MIS problems. In this work, we propose Local-Global Vision Mamba, LoG-VMamba, that explicitly enforces spatially adjacent tokens to remain nearby on the channel axis, and retains the global context in a compressed form. Our method allows the SSMs to access the local and global contexts even before reaching the last token while requiring only a simple scanning strategy. Our segmentation models are computationally efficient and substantially outperform both CNN and Transformers-based baselines on a diverse set of 2D and 3D MIS tasks. The implementation of LoG-VMamba is available at url{https://github.com/Oulu-IMEDS/LoG-VMamba}.
Read more8/27/2024
0
VM-DDPM: Vision Mamba Diffusion for Medical Image Synthesis
Zhihan Ju, Wanting Zhou
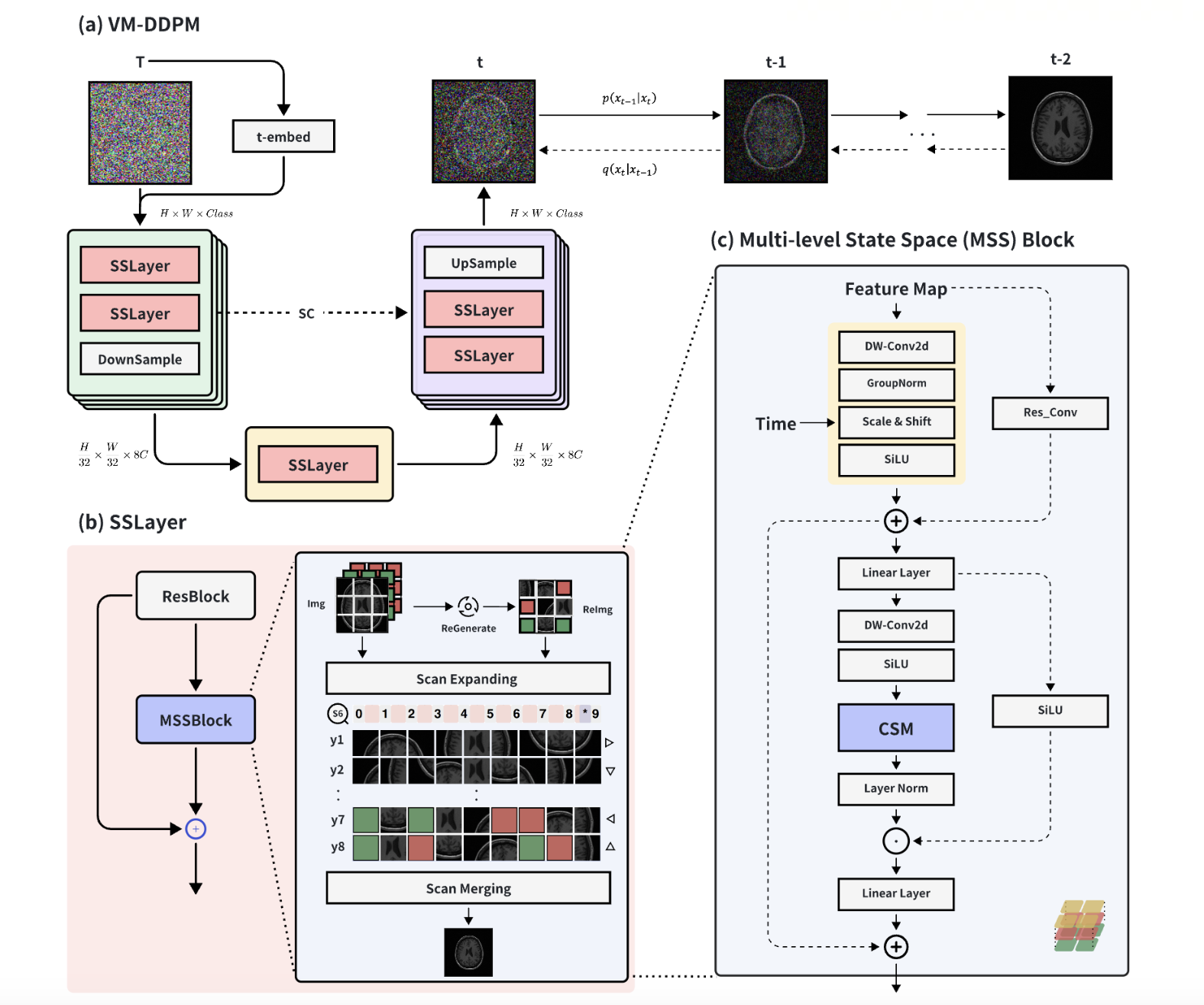
In the realm of smart healthcare, researchers enhance the scale and diversity of medical datasets through medical image synthesis. However, existing methods are limited by CNN local perception and Transformer quadratic complexity, making it difficult to balance structural texture consistency. To this end, we propose the Vision Mamba DDPM (VM-DDPM) based on State Space Model (SSM), fully combining CNN local perception and SSM global modeling capabilities, while maintaining linear computational complexity. Specifically, we designed a multi-level feature extraction module called Multi-level State Space Block (MSSBlock), and a basic unit of encoder-decoder structure called State Space Layer (SSLayer) for medical pathological images. Besides, we designed a simple, Plug-and-Play, zero-parameter Sequence Regeneration strategy for the Cross-Scan Module (CSM), which enabled the S6 module to fully perceive the spatial features of the 2D image and stimulate the generalization potential of the model. To our best knowledge, this is the first medical image synthesis model based on the SSM-CNN hybrid architecture. Our experimental evaluation on three datasets of different scales, i.e., ACDC, BraTS2018, and ChestXRay, as well as qualitative evaluation by radiologists, demonstrate that VM-DDPM achieves state-of-the-art performance.
Read more5/10/2024