VIMI: Grounding Video Generation through Multi-modal Instruction

0

Sign in to get full access
Overview
- This paper introduces ViMi, a model that can generate videos based on multi-modal instructions, including text, images, and 3D object descriptions.
- ViMi is designed to ground video generation in a rich set of multi-modal inputs, allowing for more precise and controllable video generation.
- The model is evaluated on a novel dataset of instructional videos, showing that ViMi can generate diverse and relevant videos from various instruction modalities.
Plain English Explanation
ViMi is a new artificial intelligence (AI) model that can create videos based on different types of instructions, like text, images, and 3D object descriptions. Instead of just taking a single type of input, ViMi uses a combination of these multi-modal inputs to generate the videos. This allows the model to create more detailed and tailored videos that closely match the instructions.
The researchers tested ViMi on a new dataset of "how-to" videos, where the model was given various types of instructions and asked to generate a corresponding video. The results showed that ViMi can produce a wide range of relevant and diverse videos from these multi-modal inputs, demonstrating its ability to ground video generation in rich instruction signals.
Technical Explanation
The key innovation of ViMi: Grounding Video Generation through Multi-modal Instruction is its use of multi-modal inputs to guide the video generation process. While prior work has often relied on a single input modality, such as text or images, ViMi takes advantage of a richer set of instructions, including text, images, and 3D object descriptions.
The model architecture consists of several components that encode the different input modalities and then fuse them to generate the final video. The text encoder uses a large language model to extract semantic information from the instruction text. The image encoder utilizes a vision transformer to process visual inputs. And the 3D object encoder encodes detailed 3D shape and appearance data.
These encoded representations are then combined using a multi-modal fusion module, which learns to integrate the complementary information from the different modalities. This fused representation is then used to condition a video generation module, which produces the final video output.
The researchers evaluate ViMi on a new dataset of instructional videos, where the model is tasked with generating videos that match multi-modal instructions. The results show that ViMi can produce diverse and relevant videos, outperforming baselines that use only a single input modality.
Critical Analysis
The ViMi paper presents a promising approach to grounding video generation in rich, multi-modal instructions. By leveraging complementary information from text, images, and 3D object data, the model can generate more precise and controllable videos compared to using a single input modality.
However, the paper does not discuss the model's limitations or potential issues in depth. For example, the dataset used for evaluation is relatively small and may not capture the full complexity of real-world instructional videos. Additionally, the paper does not explore the model's robustness to noisy or incomplete instructions, which would be an important consideration for practical applications.
Further research could also investigate the model's ability to generalize to different domains beyond the specific instructional video task, as well as its scalability to longer and more complex video generation. Exploring ways to make the model more interpretable and explainable would also be a valuable direction for future work.
Conclusion
ViMi represents an important step forward in video generation, demonstrating how multi-modal instruction signals can be leveraged to produce more controlled and relevant video outputs. By grounding the generation process in a rich set of inputs, the model can create videos that closely match the user's intent and requirements.
The potential applications of this technology are broad, ranging from automated content creation and educational tools to assistive technologies for people with disabilities. As AI models continue to advance in their ability to understand and generate multimedia content, the ViMi approach could pave the way for more natural and intuitive human-AI interaction.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
VIMI: Grounding Video Generation through Multi-modal Instruction
Yuwei Fang, Willi Menapace, Aliaksandr Siarohin, Tsai-Shien Chen, Kuan-Chien Wang, Ivan Skorokhodov, Graham Neubig, Sergey Tulyakov
Existing text-to-video diffusion models rely solely on text-only encoders for their pretraining. This limitation stems from the absence of large-scale multimodal prompt video datasets, resulting in a lack of visual grounding and restricting their versatility and application in multimodal integration. To address this, we construct a large-scale multimodal prompt dataset by employing retrieval methods to pair in-context examples with the given text prompts and then utilize a two-stage training strategy to enable diverse video generation tasks within the same model. In the first stage, we propose a multimodal conditional video generation framework for pretraining on these augmented datasets, establishing a foundational model for grounded video generation. Secondly, we finetune the model from the first stage on three video generation tasks, incorporating multi-modal instructions. This process further refines the model's ability to handle diverse inputs and tasks, ensuring seamless integration of multi-modal information. After this two-stage train-ing process, VIMI demonstrates multimodal understanding capabilities, producing contextually rich and personalized videos grounded in the provided inputs, as shown in Figure 1. Compared to previous visual grounded video generation methods, VIMI can synthesize consistent and temporally coherent videos with large motion while retaining the semantic control. Lastly, VIMI also achieves state-of-the-art text-to-video generation results on UCF101 benchmark.
Read more7/10/2024
🌐
0
Towards Multi-Task Multi-Modal Models: A Video Generative Perspective
Lijun Yu
Advancements in language foundation models have primarily fueled the recent surge in artificial intelligence. In contrast, generative learning of non-textual modalities, especially videos, significantly trails behind language modeling. This thesis chronicles our endeavor to build multi-task models for generating videos and other modalities under diverse conditions, as well as for understanding and compression applications. Given the high dimensionality of visual data, we pursue concise and accurate latent representations. Our video-native spatial-temporal tokenizers preserve high fidelity. We unveil a novel approach to mapping bidirectionally between visual observation and interpretable lexical terms. Furthermore, our scalable visual token representation proves beneficial across generation, compression, and understanding tasks. This achievement marks the first instances of language models surpassing diffusion models in visual synthesis and a video tokenizer outperforming industry-standard codecs. Within these multi-modal latent spaces, we study the design of multi-task generative models. Our masked multi-task transformer excels at the quality, efficiency, and flexibility of video generation. We enable a frozen language model, trained solely on text, to generate visual content. Finally, we build a scalable generative multi-modal transformer trained from scratch, enabling the generation of videos containing high-fidelity motion with the corresponding audio given diverse conditions. Throughout the course, we have shown the effectiveness of integrating multiple tasks, crafting high-fidelity latent representation, and generating multiple modalities. This work suggests intriguing potential for future exploration in generating non-textual data and enabling real-time, interactive experiences across various media forms.
Read more5/28/2024
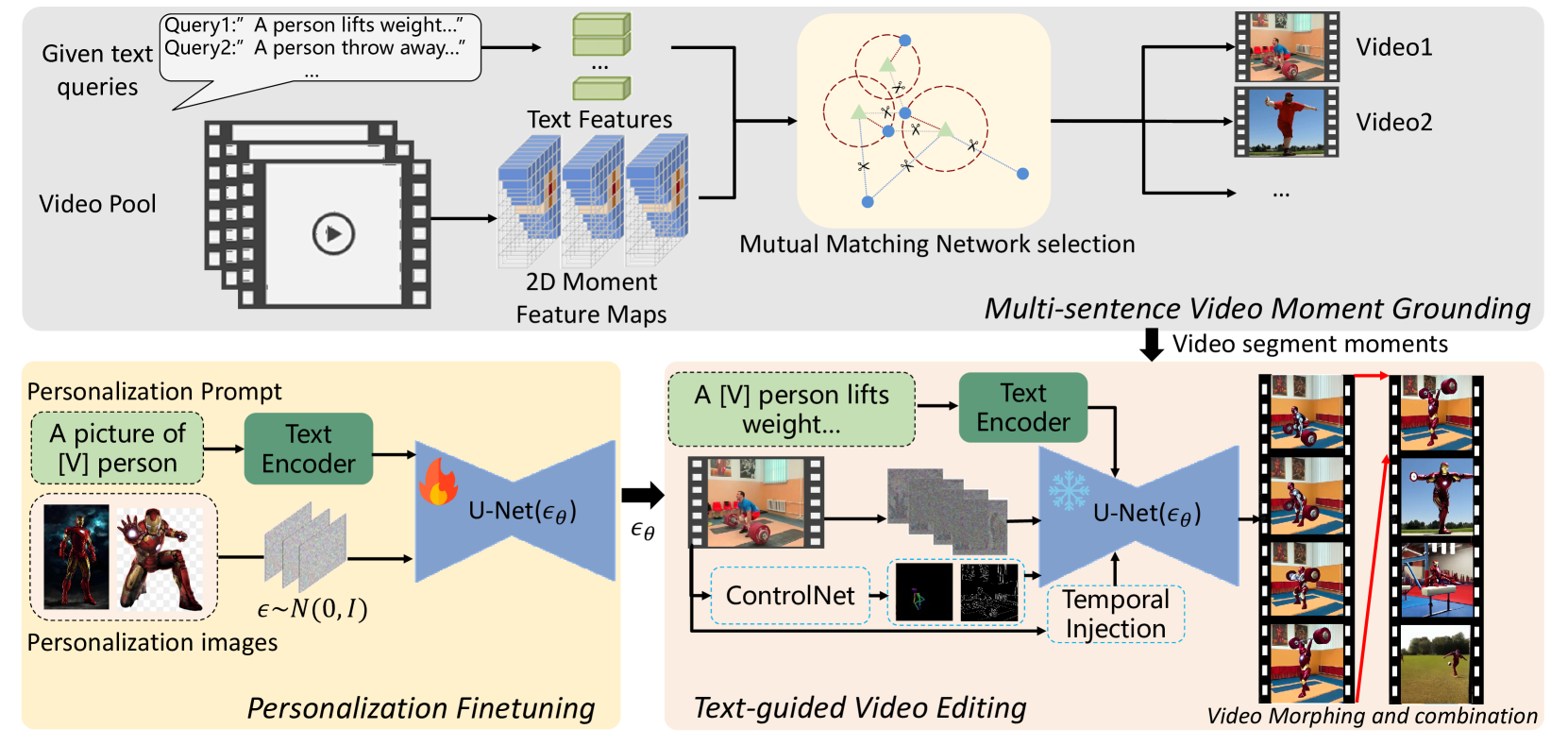
0
Multi-sentence Video Grounding for Long Video Generation
Wei Feng, Xin Wang, Hong Chen, Zeyang Zhang, Wenwu Zhu
Video generation has witnessed great success recently, but their application in generating long videos still remains challenging due to the difficulty in maintaining the temporal consistency of generated videos and the high memory cost during generation. To tackle the problems, in this paper, we propose a brave and new idea of Multi-sentence Video Grounding for Long Video Generation, connecting the massive video moment retrieval to the video generation task for the first time, providing a new paradigm for long video generation. The method of our work can be summarized as three steps: (i) We design sequential scene text prompts as the queries for video grounding, utilizing the massive video moment retrieval to search for video moment segments that meet the text requirements in the video database. (ii) Based on the source frames of retrieved video moment segments, we adopt video editing methods to create new video content while preserving the temporal consistency of the retrieved video. Since the editing can be conducted segment by segment, and even frame by frame, it largely reduces the memory cost. (iii) We also attempt video morphing and personalized generation methods to improve the subject consistency of long video generation, providing ablation experimental results for the subtasks of long video generation. Our approach seamlessly extends the development in image/video editing, video morphing and personalized generation, and video grounding to the long video generation, offering effective solutions for generating long videos at low memory cost.
Read more7/19/2024

0
Text as Images: Can Multimodal Large Language Models Follow Printed Instructions in Pixels?
Xiujun Li, Yujie Lu, Zhe Gan, Jianfeng Gao, William Yang Wang, Yejin Choi
Recent multimodal large language models (MLLMs) have shown promising instruction following capabilities on vision-language tasks. In this work, we introduce VISUAL MODALITY INSTRUCTION (VIM), and investigate how well multimodal models can understand textual instructions provided in pixels, despite not being explicitly trained on such data during pretraining or fine-tuning. We adapt VIM to eight benchmarks, including OKVQA, MM-Vet, MathVista, MMMU, and probe diverse MLLMs in both the text-modality instruction (TEM) setting and VIM setting. Notably, we observe a significant performance disparity between the original TEM and VIM settings for open-source MLLMs, indicating that open-source MLLMs face greater challenges when text instruction is presented solely in image form. To address this issue, we train v-MLLM, a generalizable model that is capable to conduct robust instruction following in both text-modality and visual-modality instructions.
Read more6/12/2024