VISA: Reasoning Video Object Segmentation via Large Language Models

0

Sign in to get full access
Overview
- This paper introduces VISA (Reasoning Video Object Segmentation via Large Language Models), a novel approach to video object segmentation that leverages large language models (LLMs) to reason about video content.
- VISA aims to address the limitations of existing video object segmentation methods, which often struggle with complex scenes and require extensive training data.
- The paper explores how LLMs, which have shown impressive capabilities in various language-related tasks, can be adapted to the video object segmentation domain.
Plain English Explanation
VISA is a new way to segment, or separate, objects in video footage. Existing methods for this task can have trouble with complex scenes and need a lot of training data. This paper explores using large language models (LLMs) - powerful AI systems that can understand and generate human-like text - to help with video object segmentation.
The key insight is that LLMs, which have shown they can reason about the world in sophisticated ways, could also be useful for understanding the contents of videos. By combining LLMs with computer vision techniques, the researchers believe VISA can overcome the limitations of current video object segmentation approaches.
VISA: Reasoning Video Object Segmentation via Large Language Models could be particularly helpful for applications like self-driving cars, video editing, and video surveillance, where accurately identifying objects in videos is crucial.
Technical Explanation
The VISA framework combines a vision transformer-based backbone with a large language model (such as GPT-3) to segment objects in videos. The vision transformer encodes visual information from the video frames, while the LLM reasons about the semantic and relational aspects of the scene.
VISA operates in two stages. First, it generates a set of object proposals by processing the video frames through the vision transformer. Then, the LLM is used to score and refine these proposals, reasoning about the relationships between objects and their contextual relevance to the video.
The researchers evaluate VISA on several video object segmentation benchmarks, including DAVIS and YouTube-VIS. They show that VISA outperforms state-of-the-art video object segmentation methods, particularly in complex scenes with multiple, interacting objects.
Critical Analysis
The VISA paper presents a promising approach to video object segmentation, but there are a few areas that could be explored further:
-
Computational Efficiency: While VISA demonstrates strong performance, the authors note that the LLM component can be computationally expensive. Optimizing the inference speed of VISA or exploring more efficient LLM architectures could make it more practical for real-world applications.
-
Generalization Capabilities: The paper focuses on evaluating VISA on existing benchmarks, but it would be valuable to test its performance on a wider range of video content, including user-generated footage or videos from diverse domains.
-
Interpretability and Explainability: As with many deep learning-based methods, it can be challenging to understand the reasoning behind VISA's segmentation decisions. Developing techniques to make the LLM's decision-making process more transparent could increase trust in the system's outputs.
-
Multimodal Integration: The VISA framework currently focuses on leveraging vision and language modalities. Incorporating additional modalities, such as audio or sensor data, could further enhance its understanding of the video content.
Overall, the VISA paper presents an exciting step forward in video object segmentation by bridging the capabilities of large language models and computer vision. Further research in the areas mentioned above could help unlock VISA's full potential.
Conclusion
The VISA framework introduces a novel approach to video object segmentation that combines the strengths of large language models and computer vision. By leveraging LLMs to reason about video content, VISA can outperform existing methods, particularly in complex scenes with multiple, interacting objects.
This research represents an important advancement in the field of video understanding, with potential applications in areas like self-driving cars, video editing, and video surveillance. While there are still some open challenges to address, VISA demonstrates the value of cross-pollinating techniques from different AI domains to tackle complex real-world problems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
VISA: Reasoning Video Object Segmentation via Large Language Models
Cilin Yan, Haochen Wang, Shilin Yan, Xiaolong Jiang, Yao Hu, Guoliang Kang, Weidi Xie, Efstratios Gavves
Existing Video Object Segmentation (VOS) relies on explicit user instructions, such as categories, masks, or short phrases, restricting their ability to perform complex video segmentation requiring reasoning with world knowledge. In this paper, we introduce a new task, Reasoning Video Object Segmentation (ReasonVOS). This task aims to generate a sequence of segmentation masks in response to implicit text queries that require complex reasoning abilities based on world knowledge and video contexts, which is crucial for structured environment understanding and object-centric interactions, pivotal in the development of embodied AI. To tackle ReasonVOS, we introduce VISA (Video-based large language Instructed Segmentation Assistant), to leverage the world knowledge reasoning capabilities of multi-modal LLMs while possessing the ability to segment and track objects in videos with a mask decoder. Moreover, we establish a comprehensive benchmark consisting of 35,074 instruction-mask sequence pairs from 1,042 diverse videos, which incorporates complex world knowledge reasoning into segmentation tasks for instruction-tuning and evaluation purposes of ReasonVOS models. Experiments conducted on 8 datasets demonstrate the effectiveness of VISA in tackling complex reasoning segmentation and vanilla referring segmentation in both video and image domains. The code and dataset are available at https://github.com/cilinyan/VISA.
Read more7/17/2024

0
ViLLa: Video Reasoning Segmentation with Large Language Model
Rongkun Zheng, Lu Qi, Xi Chen, Yi Wang, Kun Wang, Yu Qiao, Hengshuang Zhao
Although video perception models have made remarkable advancements in recent years, they still heavily rely on explicit text descriptions or pre-defined categories to identify target instances before executing video perception tasks. These models, however, fail to proactively comprehend and reason the user's intentions via textual input. Even though previous works attempt to investigate solutions to incorporate reasoning with image segmentation, they fail to reason with videos due to the video's complexity in object motion. To bridge the gap between image and video, in this work, we propose a new video segmentation task - video reasoning segmentation. The task is designed to output tracklets of segmentation masks given a complex input text query. What's more, to promote research in this unexplored area, we construct a reasoning video segmentation benchmark. Finally, we present ViLLa: Video reasoning segmentation with a Large Language Model, which incorporates the language generation capabilities of multimodal Large Language Models (LLMs) while retaining the capabilities of detecting, segmenting, and tracking multiple instances. We use a temporal-aware context aggregation module to incorporate contextual visual cues to text embeddings and propose a video-frame decoder to build temporal correlations across segmentation tokens. Remarkably, our ViLLa demonstrates capability in handling complex reasoning and referring video segmentation. Also, our model shows impressive ability in different temporal understanding benchmarks. Both quantitative and qualitative experiments show our method effectively unlocks new video reasoning segmentation capabilities for multimodal LLMs. The code and dataset will be available at https://github.com/rkzheng99/ViLLa.
Read more7/30/2024
💬
0
LISA: Reasoning Segmentation via Large Language Model
Xin Lai, Zhuotao Tian, Yukang Chen, Yanwei Li, Yuhui Yuan, Shu Liu, Jiaya Jia
Although perception systems have made remarkable advancements in recent years, they still rely on explicit human instruction or pre-defined categories to identify the target objects before executing visual recognition tasks. Such systems cannot actively reason and comprehend implicit user intention. In this work, we propose a new segmentation task -- reasoning segmentation. The task is designed to output a segmentation mask given a complex and implicit query text. Furthermore, we establish a benchmark comprising over one thousand image-instruction-mask data samples, incorporating intricate reasoning and world knowledge for evaluation purposes. Finally, we present LISA: large Language Instructed Segmentation Assistant, which inherits the language generation capabilities of multimodal Large Language Models (LLMs) while also possessing the ability to produce segmentation masks. We expand the original vocabulary with a token and propose the embedding-as-mask paradigm to unlock the segmentation capability. Remarkably, LISA can handle cases involving complex reasoning and world knowledge. Also, it demonstrates robust zero-shot capability when trained exclusively on reasoning-free datasets. In addition, fine-tuning the model with merely 239 reasoning segmentation data samples results in further performance enhancement. Both quantitative and qualitative experiments show our method effectively unlocks new reasoning segmentation capabilities for multimodal LLMs. Code, models, and data are available at https://github.com/dvlab-research/LISA.
Read more5/2/2024
0
Driving Referring Video Object Segmentation with Vision-Language Pre-trained Models
Zikun Zhou, Wentao Xiong, Li Zhou, Xin Li, Zhenyu He, Yaowei Wang
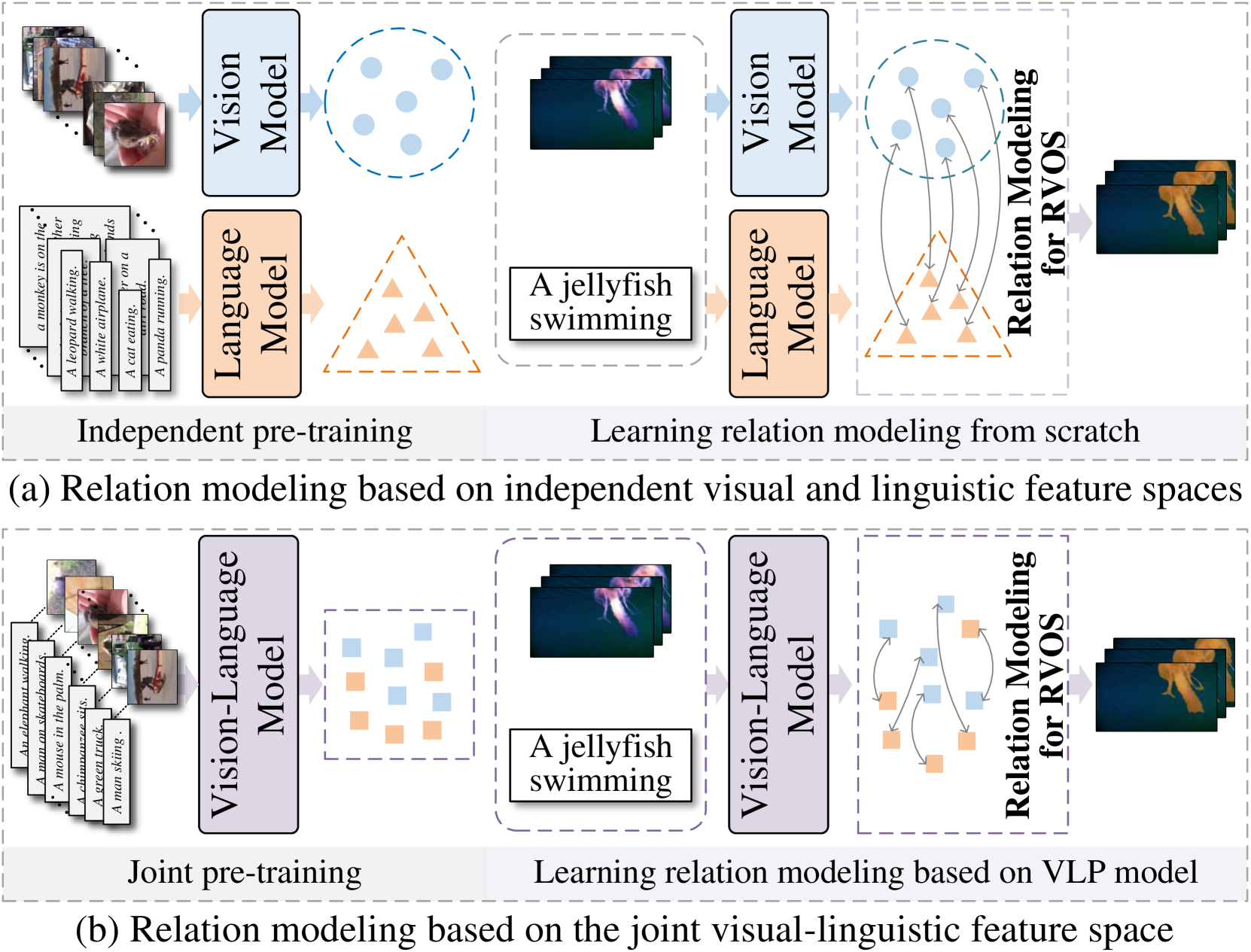
The crux of Referring Video Object Segmentation (RVOS) lies in modeling dense text-video relations to associate abstract linguistic concepts with dynamic visual contents at pixel-level. Current RVOS methods typically use vision and language models pre-trained independently as backbones. As images and texts are mapped to uncoupled feature spaces, they face the arduous task of learning Vision-Language~(VL) relation modeling from scratch. Witnessing the success of Vision-Language Pre-trained (VLP) models, we propose to learn relation modeling for RVOS based on their aligned VL feature space. Nevertheless, transferring VLP models to RVOS is a deceptively challenging task due to the substantial gap between the pre-training task (image/region-level prediction) and the RVOS task (pixel-level prediction in videos). In this work, we introduce a framework named VLP-RVOS to address this transfer challenge. We first propose a temporal-aware prompt-tuning method, which not only adapts pre-trained representations for pixel-level prediction but also empowers the vision encoder to model temporal clues. We further propose to perform multi-stage VL relation modeling while and after feature extraction for comprehensive VL understanding. Besides, we customize a cube-frame attention mechanism for spatial-temporal reasoning. Extensive experiments demonstrate that our method outperforms state-of-the-art algorithms and exhibits strong generalization abilities.
Read more5/20/2024