Vision-Language Navigation with Continual Learning

0

Sign in to get full access
Overview
- This paper introduces a novel approach for vision-language navigation (VLN) with continual learning.
- The key ideas are:
- Enabling VLN agents to continuously learn and adapt to new environments and tasks.
- Addressing catastrophic forgetting, where models forget previously learned skills when trained on new tasks.
- Incorporating continual learning techniques to continuously expand the agent's capabilities.
Plain English Explanation
The paper describes a new way for AI systems to navigate through different environments while using language instructions. Typically, these AI "agents" are trained on a fixed set of tasks and environments, and they can struggle to adapt when faced with new situations. This paper proposes an approach that allows the agents to continually learn and expand their skills over time, rather than being limited to their initial training.
The key insight is to use continual learning techniques, which help the agents avoid "forgetting" what they've learned previously when they're trained on new tasks. This allows the agents to gradually build up a more comprehensive understanding of navigation, language, and how to combine these skills to follow instructions in different environments.
By enabling this continuous learning, the agents can become more flexible and capable of handling a wider range of navigation challenges, rather than being confined to their original training. This could be particularly useful for real-world applications, where AI systems need to function in diverse and changing conditions.
Technical Explanation
The paper introduces a vision-language navigation (VLN) agent that can continually learn new skills and adapt to new environments. This addresses a key limitation of traditional VLN models, which are typically trained on a fixed set of tasks and environments, and can struggle to generalize to new situations.
The researchers incorporate continual learning techniques to enable the agent to continuously expand its capabilities without forgetting previous skills. This helps the agent narrow the gap between vision and action in navigation tasks, and bridge the simulation-to-real gap to perform well in diverse real-world environments.
The agent's architecture includes several key components:
- A multimodal encoder that processes visual and language inputs
- A recurrent controller that maintains the agent's internal state and generates actions
- A continual learning module that enables the agent to adapt to new tasks without forgetting previous knowledge
The researchers evaluate the agent's performance on several VLN benchmarks, demonstrating its ability to continually learn and outperform models trained on fixed tasks. They also analyze the agent's learned representations and behaviors to gain insights into the continual learning process.
Critical Analysis
The paper presents a promising approach for enabling VLN agents to continually expand their skills and adapt to new environments. The incorporation of continual learning techniques is a key strength, as it helps address the common problem of catastrophic forgetting, where models lose previously acquired knowledge when trained on new tasks.
However, the paper does not provide a detailed analysis of the limitations or potential issues with the proposed approach. For example, it's unclear how the continual learning mechanisms scale to more complex or diverse navigation tasks, or how robust the agent's performance is to significant shifts in the environment or task structure.
Additionally, the paper does not discuss potential ethical considerations or societal implications of deploying such continually learning VLN agents in real-world applications. As these systems become more capable and adaptable, it will be important to carefully consider their impact on users, the environment, and society as a whole.
Conclusion
This paper presents a novel approach for vision-language navigation that enables AI agents to continually learn and expand their skills. By incorporating continual learning techniques, the agents can avoid catastrophic forgetting and gradually build a more comprehensive understanding of navigation, language, and their integration.
The ability to continuously learn and adapt is a key capability for real-world AI systems, as they need to function effectively in diverse and changing environments. While the paper demonstrates promising results, further research is needed to fully understand the limitations and potential implications of this approach.
Overall, this work represents an important step towards more flexible and capable AI agents that can navigate the physical world while understanding and following human instructions.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Vision-Language Navigation with Continual Learning
Zhiyuan Li, Yanfeng Lv, Ziqin Tu, Di Shang, Hong Qiao
Vision-language navigation (VLN) is a critical domain within embedded intelligence, requiring agents to navigate 3D environments based on natural language instructions. Traditional VLN research has focused on improving environmental understanding and decision accuracy. However, these approaches often exhibit a significant performance gap when agents are deployed in novel environments, mainly due to the limited diversity of training data. Expanding datasets to cover a broader range of environments is impractical and costly. We propose the Vision-Language Navigation with Continual Learning (VLNCL) paradigm to address this challenge. In this paradigm, agents incrementally learn new environments while retaining previously acquired knowledge. VLNCL enables agents to maintain an environmental memory and extract relevant knowledge, allowing rapid adaptation to new environments while preserving existing information. We introduce a novel dual-loop scenario replay method (Dual-SR) inspired by brain memory replay mechanisms integrated with VLN agents. This method facilitates consolidating past experiences and enhances generalization across new tasks. By utilizing a multi-scenario memory buffer, the agent efficiently organizes and replays task memories, thereby bolstering its ability to adapt quickly to new environments and mitigating catastrophic forgetting. Our work pioneers continual learning in VLN agents, introducing a novel experimental setup and evaluation metrics. We demonstrate the effectiveness of our approach through extensive evaluations and establish a benchmark for the VLNCL paradigm. Comparative experiments with existing continual learning and VLN methods show significant improvements, achieving state-of-the-art performance in continual learning ability and highlighting the potential of our approach in enabling rapid adaptation while preserving prior knowledge.
Read more9/5/2024
🏅
0
Safe-VLN: Collision Avoidance for Vision-and-Language Navigation of Autonomous Robots Operating in Continuous Environments
Lu Yue, Dongliang Zhou, Liang Xie, Feitian Zhang, Ye Yan, Erwei Yin
The task of vision-and-language navigation in continuous environments (VLN-CE) aims at training an autonomous agent to perform low-level actions to navigate through 3D continuous surroundings using visual observations and language instructions. The significant potential of VLN-CE for mobile robots has been demonstrated across a large number of studies. However, most existing works in VLN-CE focus primarily on transferring the standard discrete vision-and-language navigation (VLN) methods to continuous environments, overlooking the problem of collisions. Such oversight often results in the agent deviating from the planned path or, in severe instances, the agent being trapped in obstacle areas and failing the navigational task. To address the above-mentioned issues, this paper investigates various collision scenarios within VLN-CE and proposes a classification method to predicate the underlying causes of collisions. Furthermore, a new VLN-CE algorithm, named Safe-VLN, is proposed to bolster collision avoidance capabilities including two key components, i.e., a waypoint predictor and a navigator. In particular, the waypoint predictor leverages a simulated 2D LiDAR occupancy mask to prevent the predicted waypoints from being situated in obstacle-ridden areas. The navigator, on the other hand, employs the strategy of `re-selection after collision' to prevent the robot agent from becoming ensnared in a cycle of perpetual collisions. The proposed Safe-VLN is evaluated on the R2R-CE, the results of which demonstrate an enhanced navigational performance and a statistically significant reduction in collision incidences.
Read more4/15/2024

0
NaVid: Video-based VLM Plans the Next Step for Vision-and-Language Navigation
Jiazhao Zhang, Kunyu Wang, Rongtao Xu, Gengze Zhou, Yicong Hong, Xiaomeng Fang, Qi Wu, Zhizheng Zhang, He Wang
Vision-and-language navigation (VLN) stands as a key research problem of Embodied AI, aiming at enabling agents to navigate in unseen environments following linguistic instructions. In this field, generalization is a long-standing challenge, either to out-of-distribution scenes or from Sim to Real. In this paper, we propose NaVid, a video-based large vision language model (VLM), to mitigate such a generalization gap. NaVid makes the first endeavor to showcase the capability of VLMs to achieve state-of-the-art level navigation performance without any maps, odometers, or depth inputs. Following human instruction, NaVid only requires an on-the-fly video stream from a monocular RGB camera equipped on the robot to output the next-step action. Our formulation mimics how humans navigate and naturally gets rid of the problems introduced by odometer noises, and the Sim2Real gaps from map or depth inputs. Moreover, our video-based approach can effectively encode the historical observations of robots as spatio-temporal contexts for decision making and instruction following. We train NaVid with 510k navigation samples collected from continuous environments, including action-planning and instruction-reasoning samples, along with 763k large-scale web data. Extensive experiments show that NaVid achieves state-of-the-art performance in simulation environments and the real world, demonstrating superior cross-dataset and Sim2Real transfer. We thus believe our proposed VLM approach plans the next step for not only the navigation agents but also this research field.
Read more5/28/2024
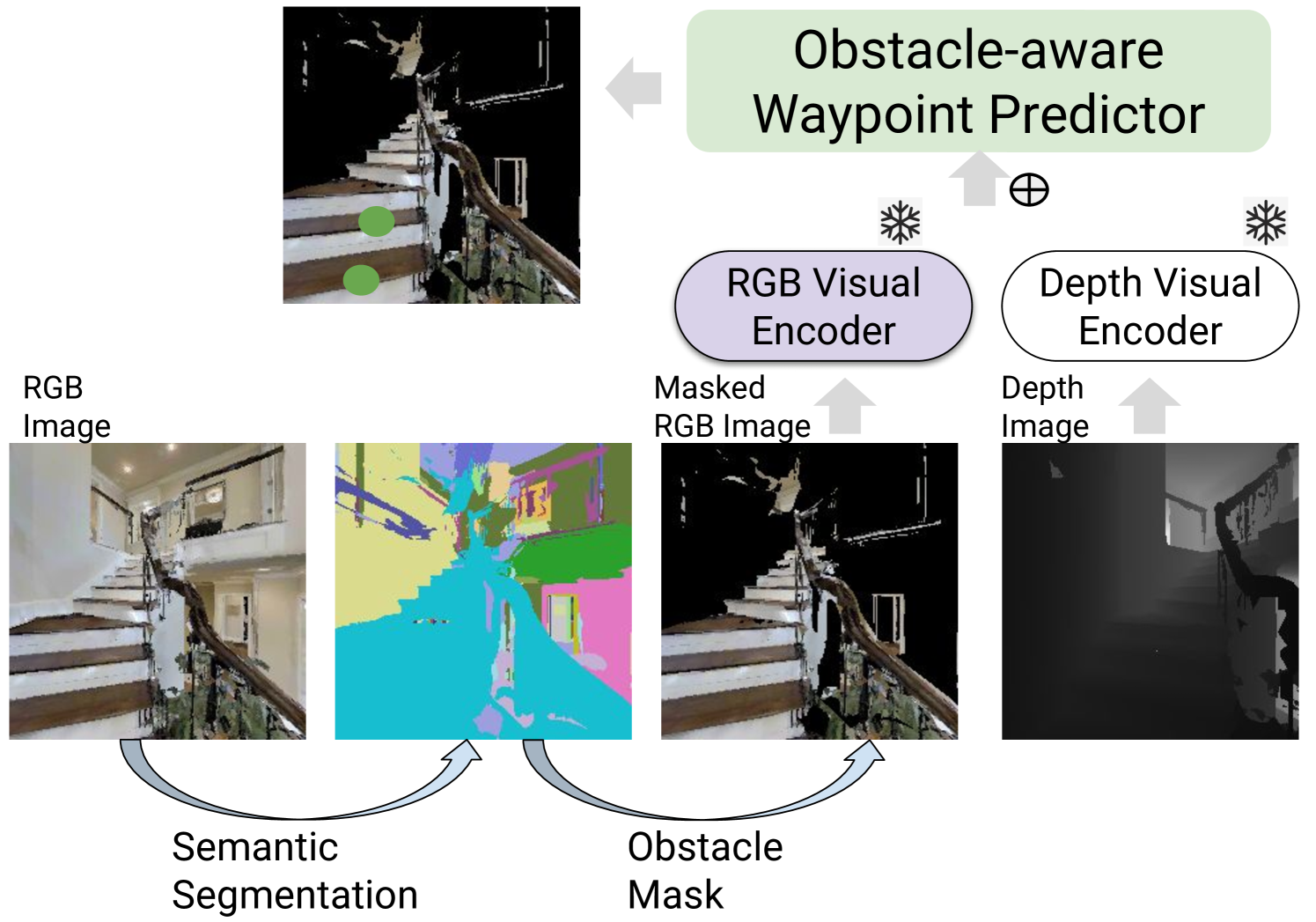
0
Narrowing the Gap between Vision and Action in Navigation
Yue Zhang, Parisa Kordjamshidi
The existing methods for Vision and Language Navigation in the Continuous Environment (VLN-CE) commonly incorporate a waypoint predictor to discretize the environment. This simplifies the navigation actions into a view selection task and improves navigation performance significantly compared to direct training using low-level actions. However, the VLN-CE agents are still far from the real robots since there are gaps between their visual perception and executed actions. First, VLN-CE agents that discretize the visual environment are primarily trained with high-level view selection, which causes them to ignore crucial spatial reasoning within the low-level action movements. Second, in these models, the existing waypoint predictors neglect object semantics and their attributes related to passibility, which can be informative in indicating the feasibility of actions. To address these two issues, we introduce a low-level action decoder jointly trained with high-level action prediction, enabling the current VLN agent to learn and ground the selected visual view to the low-level controls. Moreover, we enhance the current waypoint predictor by utilizing visual representations containing rich semantic information and explicitly masking obstacles based on humans' prior knowledge about the feasibility of actions. Empirically, our agent can improve navigation performance metrics compared to the strong baselines on both high-level and low-level actions.
Read more8/21/2024