Vision-Language Synthetic Data Enhances Echocardiography Downstream Tasks
2403.19880
0
0

Abstract
High-quality, large-scale data is essential for robust deep learning models in medical applications, particularly ultrasound image analysis. Diffusion models facilitate high-fidelity medical image generation, reducing the costs associated with acquiring and annotating new images. This paper utilizes recent vision-language models to produce diverse and realistic synthetic echocardiography image data, preserving key features of the original images guided by textual and semantic label maps. Specifically, we investigate three potential avenues: unconditional generation, generation guided by text, and a hybrid approach incorporating both textual and semantic supervision. We show that the rich contextual information present in the synthesized data potentially enhances the accuracy and interpretability of downstream tasks, such as echocardiography segmentation and classification with improved metrics and faster convergence. Our implementation with checkpoints, prompts, and the created synthetic dataset will be publicly available at href{https://github.com/Pooria90/DiffEcho}{GitHub}.
Create account to get full access
Introduction
The paper discusses the use of diffusion models for generating synthetic echocardiography (echo) images, which can aid in overcoming challenges associated with manual data collection, noise interpretation, and low sensitivity and specificity in clinical assessment of cardiovascular diseases.
Key points:
-
Diffusion models have gained popularity in medical imaging due to their ability to generate high-quality samples and avoid drawbacks of generative adversarial networks (GANs) like mode collapse and training instability.
-
The paper proposes a novel framework that leverages pre-trained text/label-map conditional diffusion models to capture the structured and spatially correlated nature of echo images.
-
The framework utilizes the joint representation of anatomical semantic label maps and text modalities to guide the echo generation process, incorporating rich contextual information.
-
The generated synthetic images aim to enhance the performance of downstream medical segmentation and classification tasks by providing reliable and diverse data.
-
Previous works in echo image synthesis using diffusion models did not exploit rich semantic and domain-specific guidance, which is addressed in this paper.
-
The paper explores the representational capacity of large vision-language models combined with fine-grained control to accurately capture the compositional complexity of ultrasound images.
The text does not provide details about specific sections of the paper, such as results or technical implementation.
Methods
The paper proposes a network for image generation that consists of several key components:
Encoder: An encoder compresses input images into a lower-dimensional latent representation.
Diffusion Model: A diffusion model is used to generate images in the latent space, modeling the process of going from noise to the data distribution.
Three Scenarios:
-
Unconditional Image Generation: A basic denoising diffusion model with no additional guidance signals.
-
Text-Guided Image Generation: Text prompts are used to guide the image generation process by conditioning on CLIP text encodings via cross-attention layers.
-
Text + Segmentation Guided Generation: In addition to text prompts, semantic segmentation maps are used as guidance signals via the ControlNet model, allowing control over both structure and subject content.
The ControlNet duplicates the diffusion branch, keeping one frozen to maintain generation capability while the other is trained to incorporate the condition signals like segmentation maps.
The models are trained with objectives penalizing the difference between predicted and true noise vectors, conditioned on the guidance signals in scenarios 2 and 3.
Results
The paper discusses the training and inference settings, dataset, evaluation metrics, prompt engineering strategies, and results for image synthesis and downstream tasks using the proposed technique.
Key points:
- PyTorch and Diffusers libraries were used, with training on 4 NVIDIA V100 GPUs, batch size of 1, Adam optimizer, and 120,000 iterations.
- The CAMUS echocardiography dataset with 2D apical views was used, with 1600/200 images for train/validation.
- FID and KID metrics were used to evaluate image synthesis quality.
- Two prompt engineering strategies were explored: textual prompts and abstract prompts for text-only models.
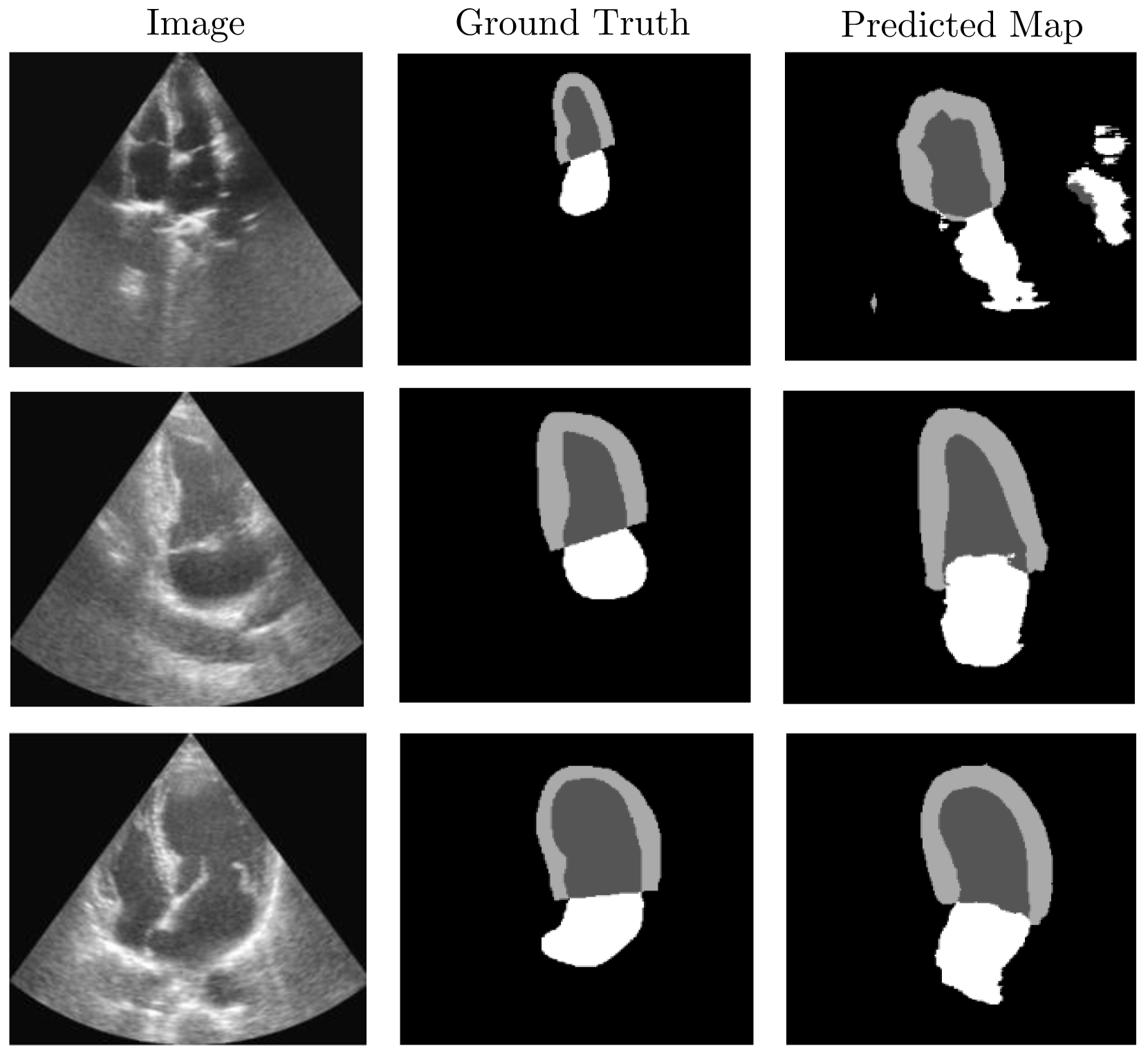
- The text+segmentation model achieved the best FID and KID scores, outperforming the baseline and showing anatomical realism.
- Qualitative results showed the text+segmentation model's ability to accurately generate right chambers, valves, and cardiac cycle phases.
- Downstream tasks of segmentation and classification were evaluated, with the text+segmentation model performing well, especially with comprehensive input guidance.
The paper does not provide any subjective opinions or make any forward-looking statements. It objectively presents the methodological details, experimental settings, and results obtained using the proposed approach.
Conclusion
The paper addresses the challenges of generating echocardiograms, which are ultrasound images of the heart, using computer vision techniques. Echocardiograms are inherently noisy, making them difficult to generate compared to standard computer vision tasks.
The authors propose the first attempt to synthesize echocardiograms using a diffusion-based model with both semantic segmentation map and text supervision. This approach aims to guide the model in generating high-fidelity and diverse echocardiogram images.
The effectiveness of the proposed method is demonstrated through extensive experiments with different prompting scenarios and two downstream tasks. The authors claim that their approach, utilizing both semantic segmentation maps and text supervision, is an optimal way to guide models in generating high-quality and diverse echocardiogram images.
Acknowledgment
The provided text acknowledges funding from the Natural Sciences and Engineering Research Council of Canada (NSERC) for the research work, citing the grant reference number RGPIN-2023-03575. The acknowledgment is presented in both English and French.
Appendix
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

EchoNet-Synthetic: Privacy-preserving Video Generation for Safe Medical Data Sharing
Hadrien Reynaud, Qingjie Meng, Mischa Dombrowski, Arijit Ghosh, Thomas Day, Alberto Gomez, Paul Leeson, Bernhard Kainz
0
0
To make medical datasets accessible without sharing sensitive patient information, we introduce a novel end-to-end approach for generative de-identification of dynamic medical imaging data. Until now, generative methods have faced constraints in terms of fidelity, spatio-temporal coherence, and the length of generation, failing to capture the complete details of dataset distributions. We present a model designed to produce high-fidelity, long and complete data samples with near-real-time efficiency and explore our approach on a challenging task: generating echocardiogram videos. We develop our generation method based on diffusion models and introduce a protocol for medical video dataset anonymization. As an exemplar, we present EchoNet-Synthetic, a fully synthetic, privacy-compliant echocardiogram dataset with paired ejection fraction labels. As part of our de-identification protocol, we evaluate the quality of the generated dataset and propose to use clinical downstream tasks as a measurement on top of widely used but potentially biased image quality metrics. Experimental outcomes demonstrate that EchoNet-Synthetic achieves comparable dataset fidelity to the actual dataset, effectively supporting the ejection fraction regression task. Code, weights and dataset are available at https://github.com/HReynaud/EchoNet-Synthetic.
6/4/2024
Harnessing the Power of Large Vision Language Models for Synthetic Image Detection
Mamadou Keita, Wassim Hamidouche, Hassen Bougueffa, Abdenour Hadid, Abdelmalik Taleb-Ahmed
0
0
In recent years, the emergence of models capable of generating images from text has attracted considerable interest, offering the possibility of creating realistic images from text descriptions. Yet these advances have also raised concerns about the potential misuse of these images, including the creation of misleading content such as fake news and propaganda. This study investigates the effectiveness of using advanced vision-language models (VLMs) for synthetic image identification. Specifically, the focus is on tuning state-of-the-art image captioning models for synthetic image detection. By harnessing the robust understanding capabilities of large VLMs, the aim is to distinguish authentic images from synthetic images produced by diffusion-based models. This study contributes to the advancement of synthetic image detection by exploiting the capabilities of visual language models such as BLIP-2 and ViTGPT2. By tailoring image captioning models, we address the challenges associated with the potential misuse of synthetic images in real-world applications. Results described in this paper highlight the promising role of VLMs in the field of synthetic image detection, outperforming conventional image-based detection techniques. Code and models can be found at https://github.com/Mamadou-Keita/VLM-DETECT.
4/4/2024
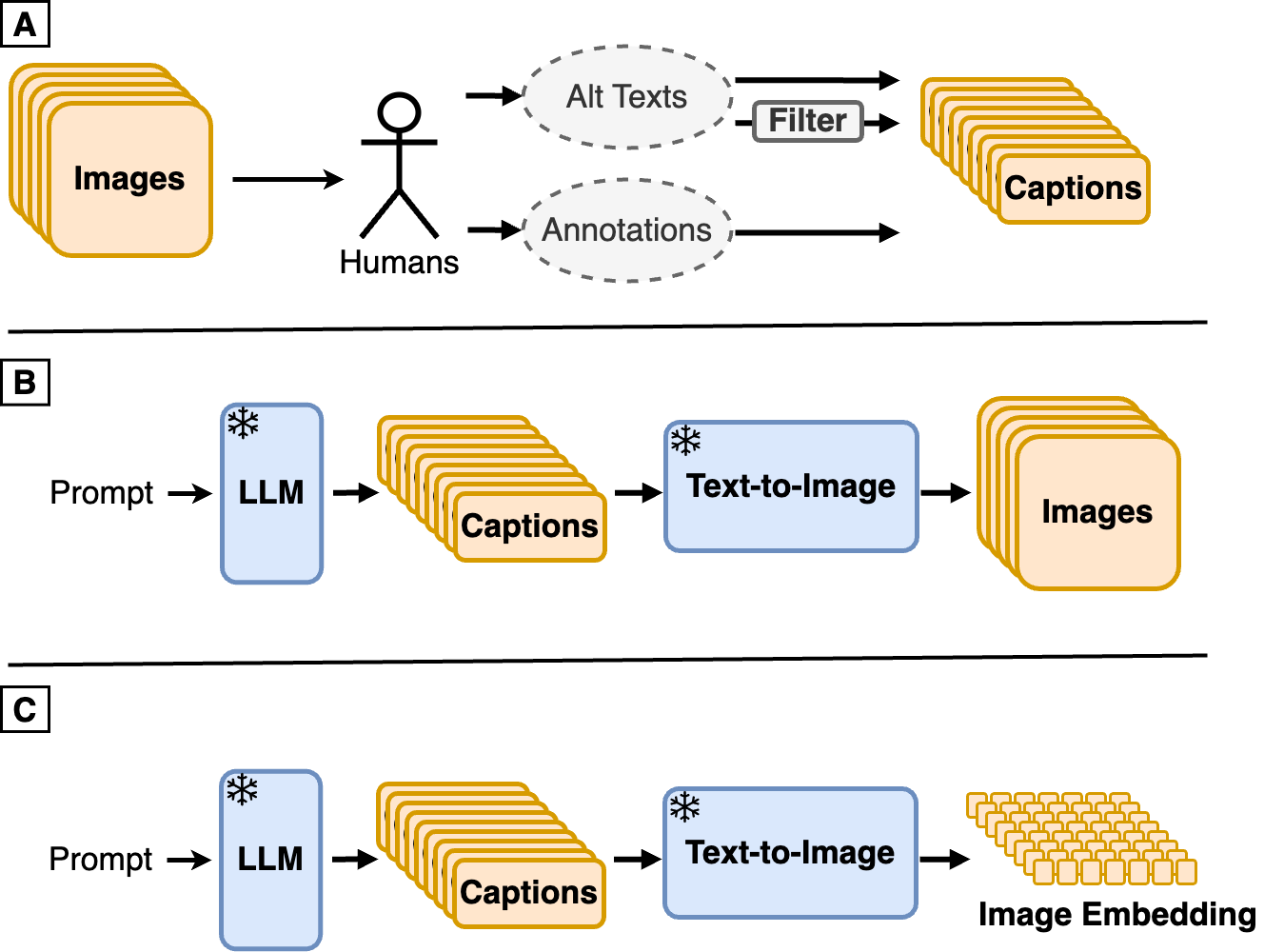
Synth$^2$: Boosting Visual-Language Models with Synthetic Captions and Image Embeddings
Sahand Sharifzadeh, Christos Kaplanis, Shreya Pathak, Dharshan Kumaran, Anastasija Ilic, Jovana Mitrovic, Charles Blundell, Andrea Banino
0
0
The creation of high-quality human-labeled image-caption datasets presents a significant bottleneck in the development of Visual-Language Models (VLMs). In this work, we investigate an approach that leverages the strengths of Large Language Models (LLMs) and image generation models to create synthetic image-text pairs for efficient and effective VLM training. Our method employs a pretrained text-to-image model to synthesize image embeddings from captions generated by an LLM. Despite the text-to-image model and VLM initially being trained on the same data, our approach leverages the image generator's ability to create novel compositions, resulting in synthetic image embeddings that expand beyond the limitations of the original dataset. Extensive experiments demonstrate that our VLM, finetuned on synthetic data achieves comparable performance to models trained solely on human-annotated data, while requiring significantly less data. Furthermore, we perform a set of analyses on captions which reveals that semantic diversity and balance are key aspects for better downstream performance. Finally, we show that synthesizing images in the image embedding space is 25% faster than in the pixel space. We believe our work not only addresses a significant challenge in VLM training but also opens up promising avenues for the development of self-improving multi-modal models.
6/10/2024
Semantic Augmentation in Images using Language
Sahiti Yerramilli, Jayant Sravan Tamarapalli, Tanmay Girish Kulkarni, Jonathan Francis, Eric Nyberg
0
0
Deep Learning models are incredibly data-hungry and require very large labeled datasets for supervised learning. As a consequence, these models often suffer from overfitting, limiting their ability to generalize to real-world examples. Recent advancements in diffusion models have enabled the generation of photorealistic images based on textual inputs. Leveraging the substantial datasets used to train these diffusion models, we propose a technique to utilize generated images to augment existing datasets. This paper explores various strategies for effective data augmentation to improve the out-of-domain generalization capabilities of deep learning models.
4/4/2024