Video-Language Understanding: A Survey from Model Architecture, Model Training, and Data Perspectives
2406.05615
0
0
Abstract
Humans use multiple senses to comprehend the environment. Vision and language are two of the most vital senses since they allow us to easily communicate our thoughts and perceive the world around us. There has been a lot of interest in creating video-language understanding systems with human-like senses since a video-language pair can mimic both our linguistic medium and visual environment with temporal dynamics. In this survey, we review the key tasks of these systems and highlight the associated challenges. Based on the challenges, we summarize their methods from model architecture, model training, and data perspectives. We also conduct performance comparison among the methods, and discuss promising directions for future research.
Create account to get full access
Overview
- The paper provides a comprehensive survey of video-language understanding, covering key aspects such as model architecture, training, and available datasets.
- It explores the latest advancements and challenges in this rapidly evolving field, which aims to enable machines to understand and reason about the relationship between visual and textual information.
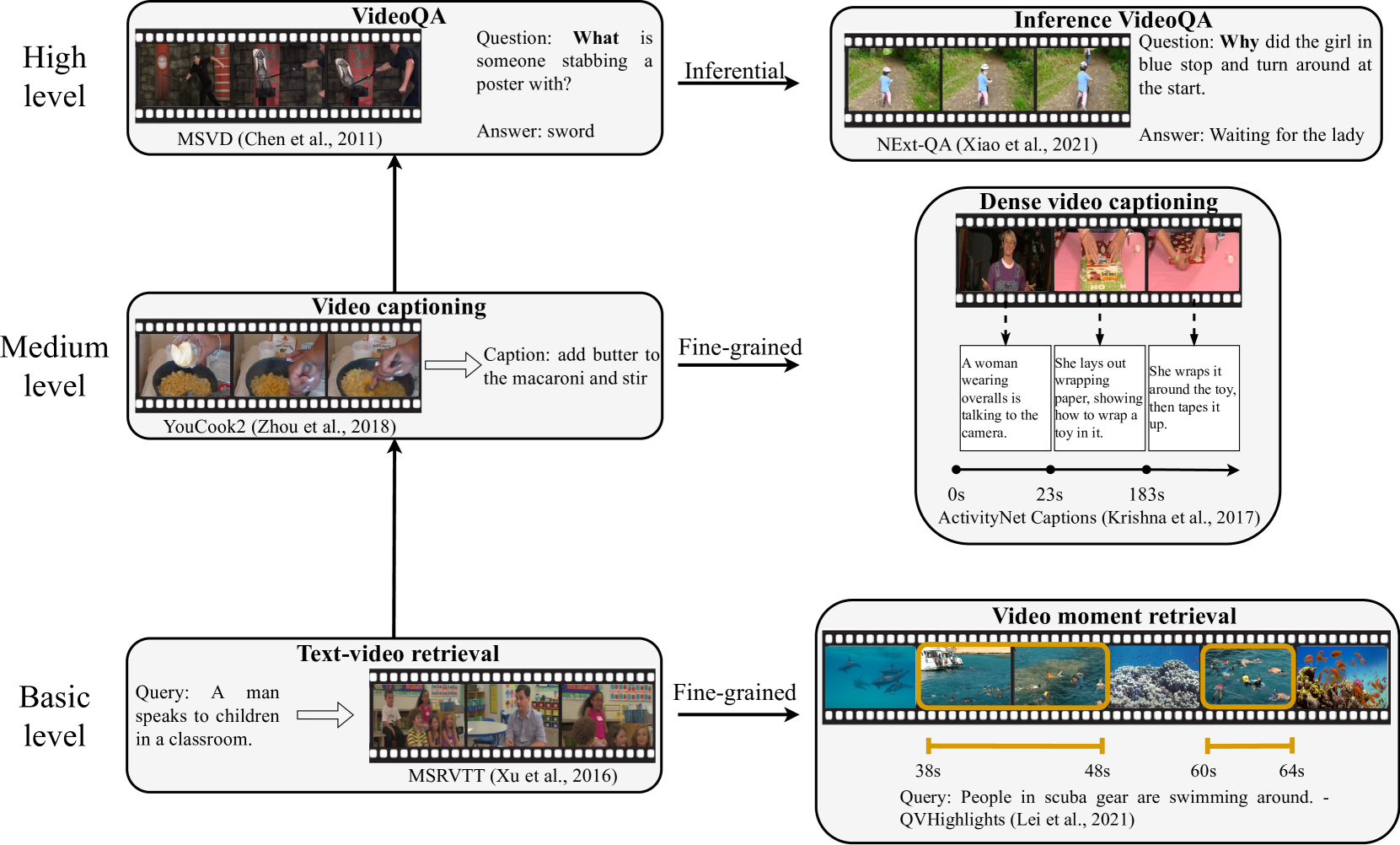
- The survey covers a wide range of video-language tasks, including video captioning, video question answering, and video-text retrieval, among others.
Plain English Explanation
The paper examines the field of video-language understanding, which involves teaching machines to comprehend the connection between visual and textual information. This is an important area of research, as it could enable machines to better understand and interact with the world around them.
The survey looks at different approaches to video-language understanding, including the architectural designs of the models, how they are trained, and the datasets used to teach them. It covers a variety of tasks, such as generating captions for videos, answering questions about video content, and retrieving relevant videos based on text queries.
The paper aims to provide a comprehensive overview of the current state of the field, highlighting the latest advancements and the challenges that researchers are still working to overcome.
Technical Explanation
The survey examines three key aspects of video-language understanding:
-
Model Architecture: The paper reviews the various architectural designs that have been proposed for video-language models, including transformer-based approaches, recurrent neural networks, and multimodal fusion techniques. It discusses the strengths and limitations of each approach and how they have evolved over time.
-
Model Training: The survey explores the different training strategies used to teach video-language models, such as supervised learning, self-supervised learning, and reinforcement learning. It also examines the role of large-scale pretraining on multimodal datasets and how this has impacted model performance.
-
Datasets: The paper provides an overview of the key datasets that have been developed for video-language tasks, including their characteristics, task formulations, and challenges. It discusses how the availability and diversity of these datasets have shaped the development of video-language models.
Throughout the survey, the authors highlight the latest advancements in the field and the ongoing research challenges, such as improving cross-modal reasoning, handling long-range dependencies, and achieving better generalization across different tasks and domains.
Critical Analysis
The survey provides a thorough and well-structured overview of the video-language understanding field, covering a wide range of topics and perspectives. However, it is important to note that the field is rapidly evolving, and the paper may not reflect the most recent developments.
One potential limitation of the survey is that it may not delve deeply into the specific technical details and trade-offs of the different model architectures and training approaches. Readers interested in a more in-depth technical analysis may need to refer to the individual research papers cited in the survey.
Additionally, the survey does not extensively discuss the potential ethical and societal implications of video-language understanding technology, such as concerns around bias, privacy, and the responsible use of these systems. As the field continues to advance, it will be crucial for researchers to consider these important issues.
Conclusion
The paper provides a comprehensive and informative survey of the video-language understanding field, covering the key aspects of model architecture, training, and available datasets. It highlights the significant progress that has been made in this area and the ongoing challenges that researchers are working to address.
The survey is a valuable resource for researchers and practitioners interested in understanding the current state of the field and the latest advancements. By synthesizing a vast body of research, the paper offers a holistic perspective on the opportunities and limitations of video-language understanding, paving the way for further innovation and development in this exciting domain.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Analyzing the Roles of Language and Vision in Learning from Limited Data
Allison Chen, Ilia Sucholutsky, Olga Russakovsky, Thomas L. Griffiths
0
0
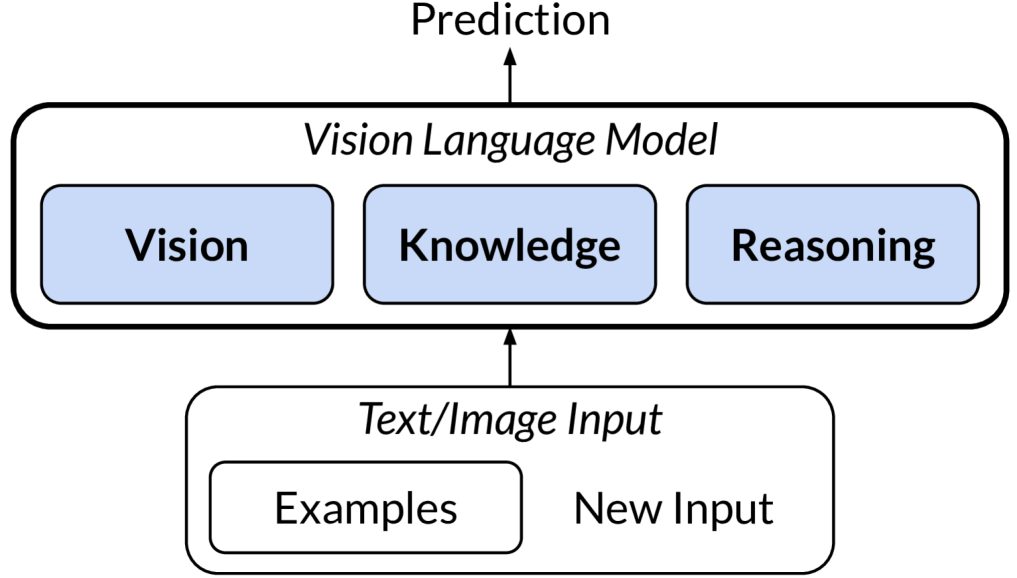
Does language help make sense of the visual world? How important is it to actually see the world rather than having it described with words? These basic questions about the nature of intelligence have been difficult to answer because we only had one example of an intelligent system -- humans -- and limited access to cases that isolated language or vision. However, the development of sophisticated Vision-Language Models (VLMs) by artificial intelligence researchers offers us new opportunities to explore the contributions that language and vision make to learning about the world. We ablate components from the cognitive architecture of these models to identify their contributions to learning new tasks from limited data. We find that a language model leveraging all components recovers a majority of a VLM's performance, despite its lack of visual input, and that language seems to allow this by providing access to prior knowledge and reasoning.
5/13/2024
📊
Vision+X: A Survey on Multimodal Learning in the Light of Data
Ye Zhu, Yu Wu, Nicu Sebe, Yan Yan
0
0
We are perceiving and communicating with the world in a multisensory manner, where different information sources are sophisticatedly processed and interpreted by separate parts of the human brain to constitute a complex, yet harmonious and unified sensing system. To endow the machines with true intelligence, multimodal machine learning that incorporates data from various sources has become an increasingly popular research area with emerging technical advances in recent years. In this paper, we present a survey on multimodal machine learning from a novel perspective considering not only the purely technical aspects but also the intrinsic nature of different data modalities. We analyze the commonness and uniqueness of each data format mainly ranging from vision, audio, text, and motions, and then present the methodological advancements categorized by the combination of data modalities, such as Vision+Text, with slightly inclined emphasis on the visual data. We investigate the existing literature on multimodal learning from both the representation learning and downstream application levels, and provide an additional comparison in the light of their technical connections with the data nature, e.g., the semantic consistency between image objects and textual descriptions, and the rhythm correspondence between video dance moves and musical beats. We hope that the exploitation of the alignment as well as the existing gap between the intrinsic nature of data modality and the technical designs, will benefit future research studies to better address a specific challenge related to the concrete multimodal task, prompting a unified multimodal machine learning framework closer to a real human intelligence system.
6/12/2024

Exploring the Frontier of Vision-Language Models: A Survey of Current Methodologies and Future Directions
Akash Ghosh, Arkadeep Acharya, Sriparna Saha, Vinija Jain, Aman Chadha
0
0
The advent of Large Language Models (LLMs) has significantly reshaped the trajectory of the AI revolution. Nevertheless, these LLMs exhibit a notable limitation, as they are primarily adept at processing textual information. To address this constraint, researchers have endeavored to integrate visual capabilities with LLMs, resulting in the emergence of Vision-Language Models (VLMs). These advanced models are instrumental in tackling more intricate tasks such as image captioning and visual question answering. In our comprehensive survey paper, we delve into the key advancements within the realm of VLMs. Our classification organizes VLMs into three distinct categories: models dedicated to vision-language understanding, models that process multimodal inputs to generate unimodal (textual) outputs and models that both accept and produce multimodal inputs and outputs.This classification is based on their respective capabilities and functionalities in processing and generating various modalities of data.We meticulously dissect each model, offering an extensive analysis of its foundational architecture, training data sources, as well as its strengths and limitations wherever possible, providing readers with a comprehensive understanding of its essential components. We also analyzed the performance of VLMs in various benchmark datasets. By doing so, we aim to offer a nuanced understanding of the diverse landscape of VLMs. Additionally, we underscore potential avenues for future research in this dynamic domain, anticipating further breakthroughs and advancements.
4/16/2024

A Survey of Multimodal Large Language Model from A Data-centric Perspective
Tianyi Bai, Hao Liang, Binwang Wan, Ling Yang, Bozhou Li, Yifan Wang, Bin Cui, Conghui He, Binhang Yuan, Wentao Zhang
0
0
Human beings perceive the world through diverse senses such as sight, smell, hearing, and touch. Similarly, multimodal large language models (MLLMs) enhance the capabilities of traditional large language models by integrating and processing data from multiple modalities including text, vision, audio, video, and 3D environments. Data plays a pivotal role in the development and refinement of these models. In this survey, we comprehensively review the literature on MLLMs from a data-centric perspective. Specifically, we explore methods for preparing multimodal data during the pretraining and adaptation phases of MLLMs. Additionally, we analyze the evaluation methods for datasets and review benchmarks for evaluating MLLMs. Our survey also outlines potential future research directions. This work aims to provide researchers with a detailed understanding of the data-driven aspects of MLLMs, fostering further exploration and innovation in this field.
5/28/2024