Towards Comprehensive Multimodal Perception: Introducing the Touch-Language-Vision Dataset
2403.09813
0
0

Abstract
Tactility provides crucial support and enhancement for the perception and interaction capabilities of both humans and robots. Nevertheless, the multimodal research related to touch primarily focuses on visual and tactile modalities, with limited exploration in the domain of language. Beyond vocabulary, sentence-level descriptions contain richer semantics. Based on this, we construct a touch-language-vision dataset named TLV (Touch-Language-Vision) by human-machine cascade collaboration, featuring sentence-level descriptions for multimode alignment. The new dataset is used to fine-tune our proposed lightweight training framework, STLV-Align (Synergistic Touch-Language-Vision Alignment), achieving effective semantic alignment with minimal parameter adjustments (1%). Project Page: https://xiaoen0.github.io/touch.page/.
Create account to get full access
Overview
- This paper introduces the Touch-Language-Vision (TLV) dataset, a new multimodal dataset that combines touch, language, and vision modalities.
- The dataset aims to enable comprehensive multimodal perception research, going beyond existing datasets that focus on only a subset of these modalities.
- The authors also present baseline models for several multimodal tasks using the TLV dataset, demonstrating its utility for advancing the field of multimodal AI.
Plain English Explanation
The paper presents a new dataset called the Touch-Language-Vision (TLV) dataset, which combines information from three different sensory modalities: touch, language, and vision. Existing datasets for multimodal AI research often focus on only one or two of these modalities, but the TLV dataset aims to provide a more comprehensive set of data to enable further advancements in this area.
The Exploring the Necessity of the Visual Modality in Multimodal Machine Translation and Foundations of Multisensory Artificial Intelligence papers have explored the importance of incorporating multiple sensory modalities in AI systems. Similarly, the Multi-Modal Perception for Soft Robotic Interactions Using and Exploring the Frontier of Vision-Language Models: A Survey of Current papers have investigated the use of multimodal perception in robotics and language-vision models, respectively.
The TLV dataset provides a new resource for researchers to build on these foundations and develop even more comprehensive multimodal AI systems that can better understand and interact with the world around them, just as humans do by integrating information from various senses. The authors also present baseline models for several tasks using the TLV dataset, demonstrating its utility and potential for advancing the field of multimodal AI.
Technical Explanation
The paper introduces the Touch-Language-Vision (TLV) dataset, which combines three key sensory modalities: touch, language, and vision. Existing multimodal datasets often focus on only a subset of these modalities, but the TLV dataset aims to provide a more comprehensive resource for multimodal perception research.
The dataset includes a wide range of tactile, linguistic, and visual data, including touch sensor readings, object descriptions, and images. The authors leveraged crowdsourcing to collect this data, which covers a diverse set of everyday objects and interactions.
To demonstrate the utility of the TLV dataset, the paper presents baseline models for several multimodal tasks, such as touch-based object recognition, language-guided object retrieval, and cross-modal object matching. These models achieve strong performance, highlighting the dataset's potential to drive further advancements in multimodal AI.
The Multimodal Large Language Model is Human-Aligned paper has explored the benefits of incorporating multiple modalities into language models, which is relevant to the tasks explored in this work.
Critical Analysis
The authors provide a thorough evaluation of the TLV dataset and the baseline models, including discussions of the dataset's limitations and areas for future research. For example, they acknowledge that the current dataset is limited in scale and diversity compared to the real-world complexity of multimodal perception.
Additionally, the paper does not fully address the potential challenges of integrating and fusing the various modalities, which can be a significant hurdle in developing effective multimodal AI systems. Further research is needed to explore robust and efficient ways of combining touch, language, and vision data.
Despite these limitations, the TLV dataset represents an important step forward in enabling more comprehensive multimodal perception research. The baseline models demonstrate the dataset's utility, and the authors' call for further exploration of multimodal AI is well-justified and timely.
Conclusion
This paper presents the Touch-Language-Vision (TLV) dataset, a new multimodal resource that combines data from touch, language, and vision modalities. The dataset aims to enable more comprehensive multimodal perception research, going beyond the limitations of existing datasets that focus on only a subset of these modalities.
The authors also provide baseline models for several multimodal tasks, showcasing the potential of the TLV dataset to drive advancements in the field of multimodal AI. While the dataset and models have certain limitations, this work represents an important contribution to the ongoing efforts to develop AI systems that can perceive and interact with the world in more human-like ways.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Touch100k: A Large-Scale Touch-Language-Vision Dataset for Touch-Centric Multimodal Representation
Ning Cheng, Changhao Guan, Jing Gao, Weihao Wang, You Li, Fandong Meng, Jie Zhou, Bin Fang, Jinan Xu, Wenjuan Han
0
0
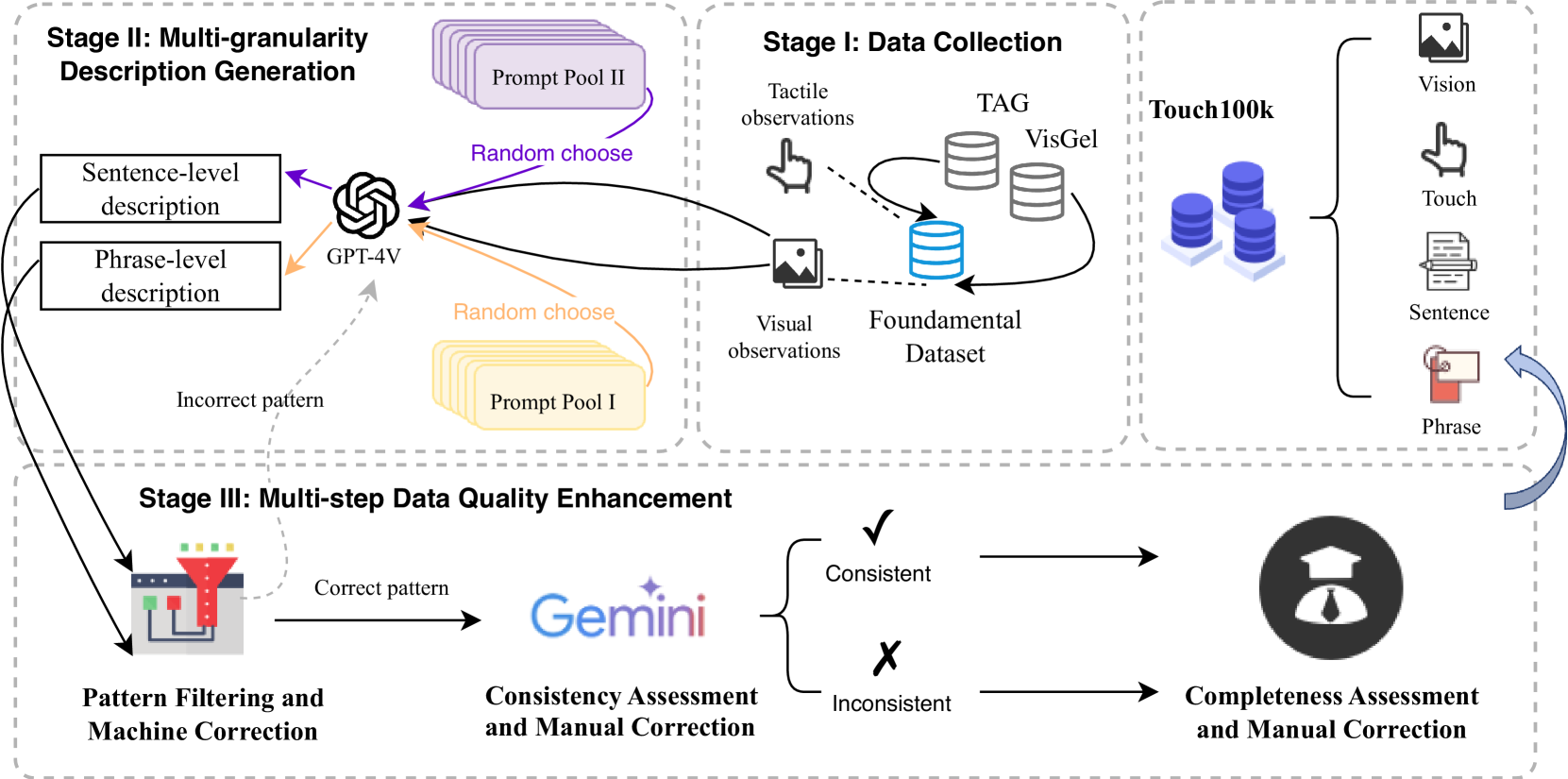
Touch holds a pivotal position in enhancing the perceptual and interactive capabilities of both humans and robots. Despite its significance, current tactile research mainly focuses on visual and tactile modalities, overlooking the language domain. Inspired by this, we construct Touch100k, a paired touch-language-vision dataset at the scale of 100k, featuring tactile sensation descriptions in multiple granularities (i.e., sentence-level natural expressions with rich semantics, including contextual and dynamic relationships, and phrase-level descriptions capturing the key features of tactile sensations). Based on the dataset, we propose a pre-training method, Touch-Language-Vision Representation Learning through Curriculum Linking (TLV-Link, for short), inspired by the concept of curriculum learning. TLV-Link aims to learn a tactile representation for the GelSight sensor and capture the relationship between tactile, language, and visual modalities. We evaluate our representation's performance across two task categories (namely, material property identification and robot grasping prediction), focusing on tactile representation and zero-shot touch understanding. The experimental evaluation showcases the effectiveness of our representation. By enabling TLV-Link to achieve substantial improvements and establish a new state-of-the-art in touch-centric multimodal representation learning, Touch100k demonstrates its value as a valuable resource for research. Project page: https://cocacola-lab.github.io/Touch100k/.
6/7/2024
📊
Vision+X: A Survey on Multimodal Learning in the Light of Data
Ye Zhu, Yu Wu, Nicu Sebe, Yan Yan
0
0
We are perceiving and communicating with the world in a multisensory manner, where different information sources are sophisticatedly processed and interpreted by separate parts of the human brain to constitute a complex, yet harmonious and unified sensing system. To endow the machines with true intelligence, multimodal machine learning that incorporates data from various sources has become an increasingly popular research area with emerging technical advances in recent years. In this paper, we present a survey on multimodal machine learning from a novel perspective considering not only the purely technical aspects but also the intrinsic nature of different data modalities. We analyze the commonness and uniqueness of each data format mainly ranging from vision, audio, text, and motions, and then present the methodological advancements categorized by the combination of data modalities, such as Vision+Text, with slightly inclined emphasis on the visual data. We investigate the existing literature on multimodal learning from both the representation learning and downstream application levels, and provide an additional comparison in the light of their technical connections with the data nature, e.g., the semantic consistency between image objects and textual descriptions, and the rhythm correspondence between video dance moves and musical beats. We hope that the exploitation of the alignment as well as the existing gap between the intrinsic nature of data modality and the technical designs, will benefit future research studies to better address a specific challenge related to the concrete multimodal task, prompting a unified multimodal machine learning framework closer to a real human intelligence system.
6/12/2024
👀
Constructing Multilingual Visual-Text Datasets Revealing Visual Multilingual Ability of Vision Language Models
Jesse Atuhurra, Iqra Ali, Tatsuya Hiraoka, Hidetaka Kamigaito, Tomoya Iwakura, Taro Watanabe
0
0
Large language models (LLMs) have increased interest in vision language models (VLMs), which process image-text pairs as input. Studies investigating the visual understanding ability of VLMs have been proposed, but such studies are still preliminary because existing datasets do not permit a comprehensive evaluation of the fine-grained visual linguistic abilities of VLMs across multiple languages. To further explore the strengths of VLMs, such as GPT-4V cite{openai2023GPT4}, we developed new datasets for the systematic and qualitative analysis of VLMs. Our contribution is four-fold: 1) we introduced nine vision-and-language (VL) tasks (including object recognition, image-text matching, and more) and constructed multilingual visual-text datasets in four languages: English, Japanese, Swahili, and Urdu through utilizing templates containing textit{questions} and prompting GPT4-V to generate the textit{answers} and the textit{rationales}, 2) introduced a new VL task named textit{unrelatedness}, 3) introduced rationales to enable human understanding of the VLM reasoning process, and 4) employed human evaluation to measure the suitability of proposed datasets for VL tasks. We show that VLMs can be fine-tuned on our datasets. Our work is the first to conduct such analyses in Swahili and Urdu. Also, it introduces textit{rationales} in VL analysis, which played a vital role in the evaluation.
6/26/2024
Video-Language Understanding: A Survey from Model Architecture, Model Training, and Data Perspectives
Thong Nguyen, Yi Bin, Junbin Xiao, Leigang Qu, Yicong Li, Jay Zhangjie Wu, Cong-Duy Nguyen, See-Kiong Ng, Luu Anh Tuan
0
0
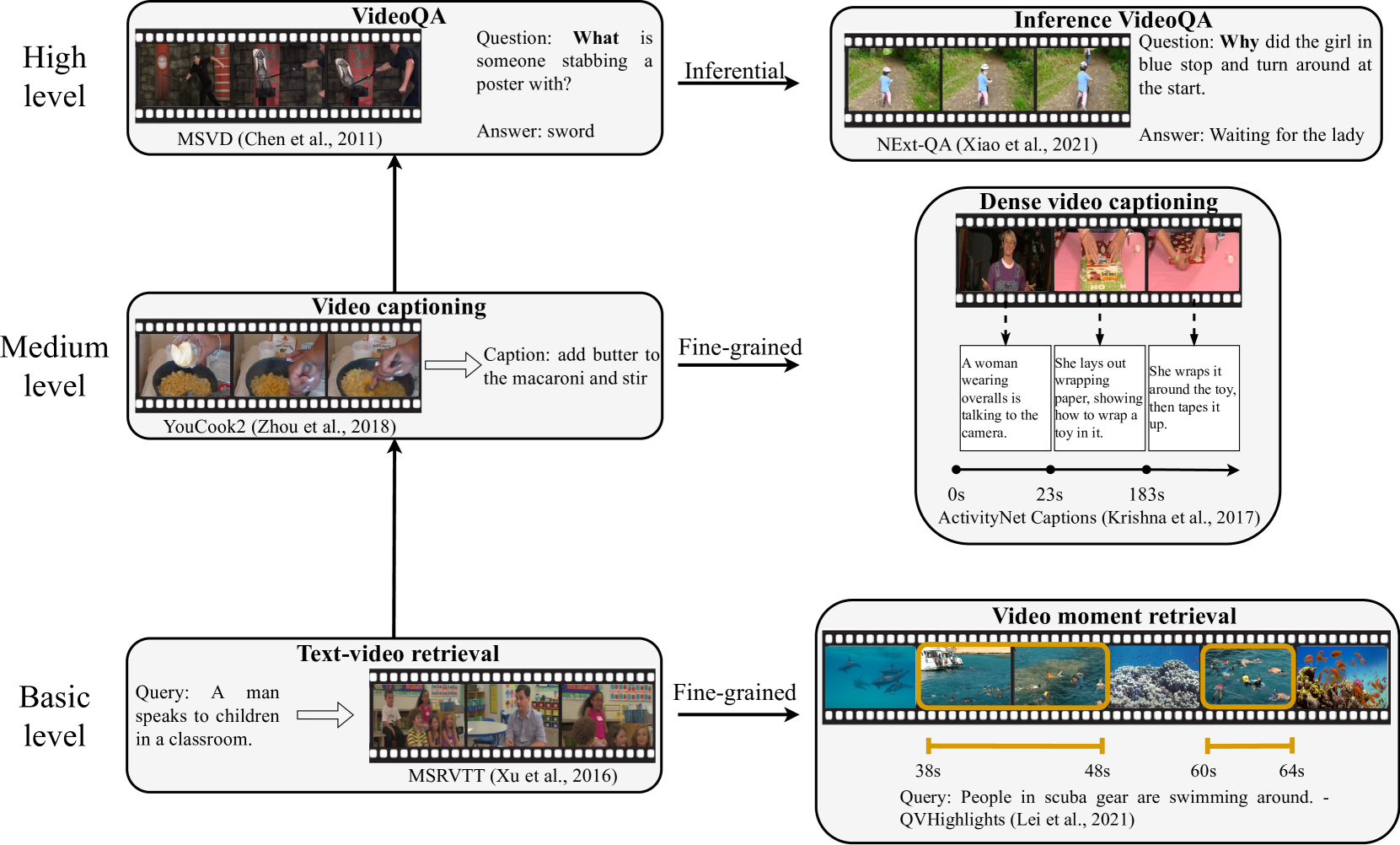
Humans use multiple senses to comprehend the environment. Vision and language are two of the most vital senses since they allow us to easily communicate our thoughts and perceive the world around us. There has been a lot of interest in creating video-language understanding systems with human-like senses since a video-language pair can mimic both our linguistic medium and visual environment with temporal dynamics. In this survey, we review the key tasks of these systems and highlight the associated challenges. Based on the challenges, we summarize their methods from model architecture, model training, and data perspectives. We also conduct performance comparison among the methods, and discuss promising directions for future research.
6/11/2024