Towards Sim-to-Real Industrial Parts Classification with Synthetic Dataset
2404.08778
0
0

Abstract
This paper is about effectively utilizing synthetic data for training deep neural networks for industrial parts classification, in particular, by taking into account the domain gap against real-world images. To this end, we introduce a synthetic dataset that may serve as a preliminary testbed for the Sim-to-Real challenge; it contains 17 objects of six industrial use cases, including isolated and assembled parts. A few subsets of objects exhibit large similarities in shape and albedo for reflecting challenging cases of industrial parts. All the sample images come with and without random backgrounds and post-processing for evaluating the importance of domain randomization. We call it Synthetic Industrial Parts dataset (SIP-17). We study the usefulness of SIP-17 through benchmarking the performance of five state-of-the-art deep network models, supervised and self-supervised, trained only on the synthetic data while testing them on real data. By analyzing the results, we deduce some insights on the feasibility and challenges of using synthetic data for industrial parts classification and for further developing larger-scale synthetic datasets. Our dataset and code are publicly available.
Create account to get full access
Overview
- This paper explores the use of synthetic datasets for improving the performance of industrial parts classification models in real-world settings.
- The researchers developed a novel pipeline for generating high-quality synthetic data that closely resembles real-world industrial parts.
- They then evaluated the effectiveness of using this synthetic data for training classification models and transferring the learned knowledge to real-world datasets.
Plain English Explanation
In the world of industrial manufacturing, accurately identifying and classifying different parts is a crucial task. However, building robust machine learning models for this purpose can be challenging, as real-world industrial datasets are often limited in size and diversity. To address this, the researchers in this paper investigated the use of synthetic data as a way to supplement and enhance the training of industrial parts classification models.
The key idea is to generate high-fidelity synthetic images of industrial parts using advanced computer graphics techniques. <a href="https://aimodels.fyi/papers/arxiv/exploring-generative-ai-sim2real-driving-data-synthesis" class="ltx_ref">These synthetic images can then be used alongside real-world data to train machine learning models</a>, helping them learn more robust and generalizable features.
The researchers developed a comprehensive pipeline for creating these synthetic datasets, carefully considering factors like part geometry, material properties, and lighting conditions to ensure the generated images closely match the appearance of real-world industrial parts. <a href="https://aimodels.fyi/papers/arxiv/is-synthetic-image-useful-transfer-learning-investigation" class="ltx_ref">They then evaluated the performance of classification models trained on this synthetic data, both in the simulated environment and when transferred to real-world industrial datasets.</a>
The results of their experiments showed that by leveraging synthetic data, the researchers were able to achieve significant improvements in the accuracy and robustness of their industrial parts classification models, compared to models trained solely on limited real-world data. This suggests that the strategic use of synthetic data can be a powerful tool for enhancing the performance of computer vision systems in industrial settings.
Technical Explanation
The researchers began by constructing a comprehensive pipeline for generating high-quality synthetic datasets of industrial parts. <a href="https://aimodels.fyi/papers/arxiv/scalability-building-component-data-annotation-enhancing-facade" class="ltx_ref">This involved using 3D modeling software to create realistic 3D models of various industrial parts, and then rendering these models under different lighting conditions, camera viewpoints, and background environments to produce a diverse set of synthetic images.</a>
To evaluate the effectiveness of this synthetic data, the researchers trained a series of convolutional neural network (CNN) models for industrial parts classification. They compared the performance of models trained solely on real-world data, models trained solely on synthetic data, and models trained on a combination of real and synthetic data.
The experimental results showed that models trained on the synthetic dataset alone were able to achieve competitive performance on the simulated test data, demonstrating the high fidelity of the generated images. <a href="https://aimodels.fyi/papers/arxiv/improving-deep-learning-predictions-simulated-images-vice" class="ltx_ref">Furthermore, when the models trained on synthetic data were fine-tuned on smaller real-world datasets, they were able to outperform models trained solely on the real-world data, highlighting the value of using synthetic data for transfer learning.</a>
The researchers attribute this improved performance to the increased diversity and depth of the synthetic dataset, which allows the models to learn more robust and generalizable features compared to training on limited real-world data alone. <a href="https://aimodels.fyi/papers/arxiv/best-practices-lessons-learned-synthetic-data-language" class="ltx_ref">They also discuss the importance of carefully designing the synthetic data generation process to ensure the generated images closely match the characteristics of real-world industrial parts.</a>
Critical Analysis
One potential limitation of the study is the reliance on a single real-world industrial parts dataset for evaluation. While the researchers demonstrate the effectiveness of their synthetic data approach on this dataset, it would be valuable to evaluate the models on a broader range of real-world industrial datasets to further validate the generalizability of their findings.
Additionally, the paper does not provide extensive details on the specific network architectures and hyperparameters used for the classification models. Further insights into the model design choices and their impact on performance would help readers better understand the key factors contributing to the observed improvements.
It would also be interesting to see the researchers explore more advanced techniques for bridging the gap between simulated and real-world data, such as the use of <a href="https://aimodels.fyi/papers/arxiv/improving-deep-learning-predictions-simulated-images-vice" class="ltx_ref">domain adaptation or style transfer methods</a>. These approaches could potentially further enhance the model's ability to generalize from synthetic to real-world data.
Conclusion
This paper presents a promising approach for leveraging synthetic data to enhance the performance of industrial parts classification models. By carefully designing a pipeline for generating high-quality synthetic datasets, the researchers were able to demonstrate significant improvements in model accuracy and robustness when transferring these models to real-world industrial datasets.
The findings of this study suggest that the strategic use of synthetic data can be a powerful tool for overcoming the data scarcity challenges often encountered in industrial computer vision applications. As the field of computer graphics and simulation continues to advance, we can expect to see further innovations in the generation of synthetic data and its integration with machine learning for a wide range of industrial and engineering applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📊
Synthetic Data Generation for Bridging Sim2Real Gap in a Production Environment
Parth Rawal, Mrunal Sompura, Wolfgang Hintze
0
0
Synthetic data is being used lately for training deep neural networks in computer vision applications such as object detection, object segmentation and 6D object pose estimation. Domain randomization hereby plays an important role in reducing the simulation to reality gap. However, this generalization might not be effective in specialized domains like a production environment involving complex assemblies. Either the individual parts, trained with synthetic images, are integrated in much larger assemblies making them indistinguishable from their counterparts and result in false positives or are partially occluded just enough to give rise to false negatives. Domain knowledge is vital in these cases and if conceived effectively while generating synthetic data, can show a considerable improvement in bridging the simulation to reality gap. This paper focuses on synthetic data generation procedures for parts and assemblies used in a production environment. The basic procedures for synthetic data generation and their various combinations are evaluated and compared on images captured in a production environment, where results show up to 15% improvement using combinations of basic procedures. Reducing the simulation to reality gap in this way can aid to utilize the true potential of robot assisted production using artificial intelligence.
5/13/2024
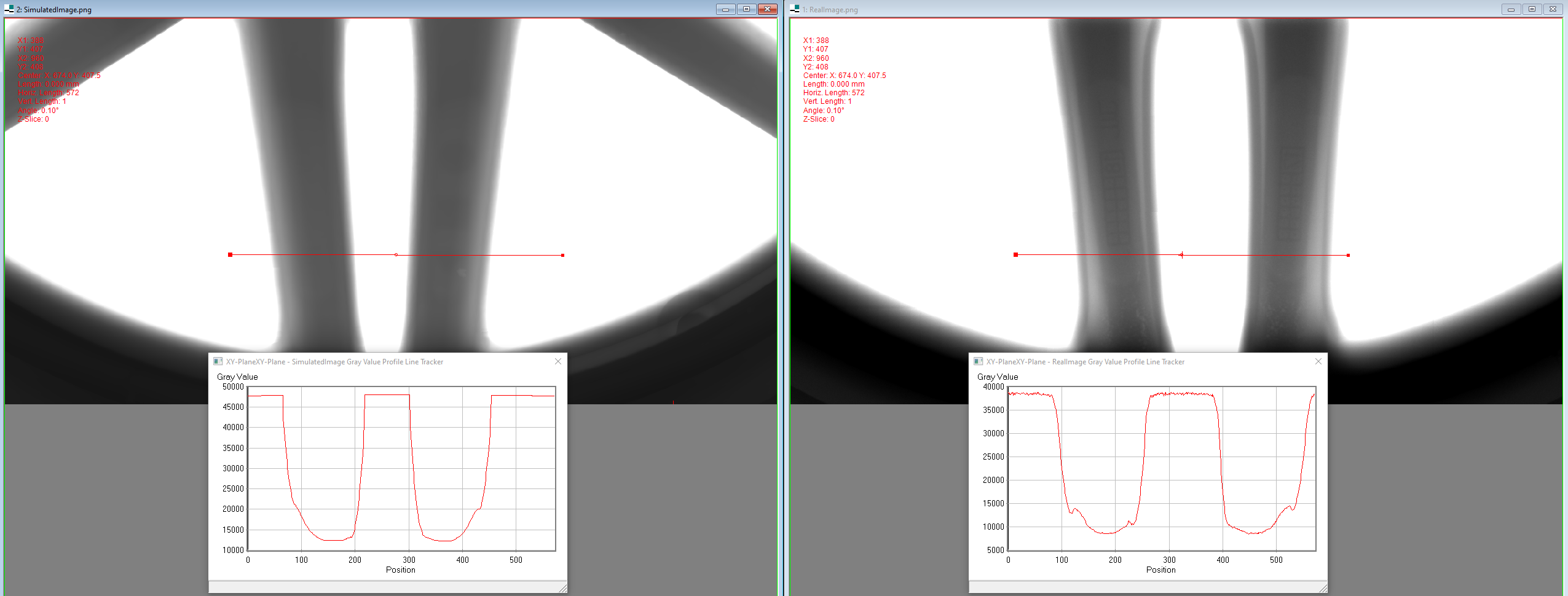
New!Towards Reducing Data Acquisition and Labeling for Defect Detection using Simulated Data
Lukas Malte Kemeter, Rasmus Hvingelby, Paulina Sierak, Tobias Schon, Bishwajit Gosswam
0
0
In many manufacturing settings, annotating data for machine learning and computer vision is costly, but synthetic data can be generated at significantly lower cost. Substituting the real-world data with synthetic data is therefore appealing for many machine learning applications that require large amounts of training data. However, relying solely on synthetic data is frequently inadequate for effectively training models that perform well on real-world data, primarily due to domain shifts between the synthetic and real-world data. We discuss approaches for dealing with such a domain shift when detecting defects in X-ray scans of aluminium wheels. Using both simulated and real-world X-ray images, we train an object detection model with different strategies to identify the training approach that generates the best detection results while minimising the demand for annotated real-world training samples. Our preliminary findings suggest that the sim-2-real domain adaptation approach is more cost-efficient than a fully supervised oracle - if the total number of available annotated samples is fixed. Given a certain number of labeled real-world samples, training on a mix of synthetic and unlabeled real-world data achieved comparable or even better detection results at significantly lower cost. We argue that future research into the cost-efficiency of different training strategies is important for a better understanding of how to allocate budget in applied machine learning projects.
6/28/2024

Visual Car Brand Classification by Implementing a Synthetic Image Dataset Creation Pipeline
Jan Lippemeier, Stefanie Hittmeyer, Oliver Niehorster, Markus Lange-Hegermann
0
0
Recent advancements in machine learning, particularly in deep learning and object detection, have significantly improved performance in various tasks, including image classification and synthesis. However, challenges persist, particularly in acquiring labeled data that accurately represents specific use cases. In this work, we propose an automatic pipeline for generating synthetic image datasets using Stable Diffusion, an image synthesis model capable of producing highly realistic images. We leverage YOLOv8 for automatic bounding box detection and quality assessment of synthesized images. Our contributions include demonstrating the feasibility of training image classifiers solely on synthetic data, automating the image generation pipeline, and describing the computational requirements for our approach. We evaluate the usability of different modes of Stable Diffusion and achieve a classification accuracy of 75%.
6/4/2024
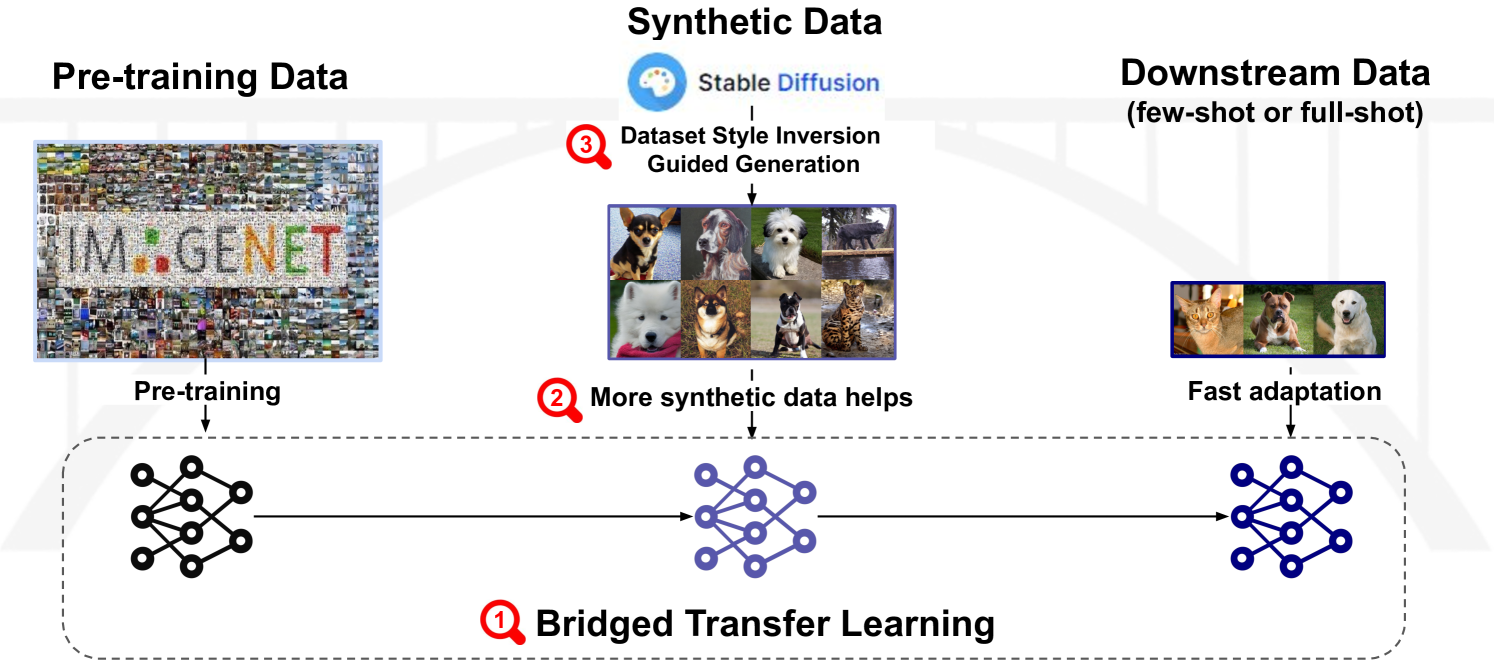
Is Synthetic Image Useful for Transfer Learning? An Investigation into Data Generation, Volume, and Utilization
Yuhang Li, Xin Dong, Chen Chen, Jingtao Li, Yuxin Wen, Michael Spranger, Lingjuan Lyu
0
0
Synthetic image data generation represents a promising avenue for training deep learning models, particularly in the realm of transfer learning, where obtaining real images within a specific domain can be prohibitively expensive due to privacy and intellectual property considerations. This work delves into the generation and utilization of synthetic images derived from text-to-image generative models in facilitating transfer learning paradigms. Despite the high visual fidelity of the generated images, we observe that their naive incorporation into existing real-image datasets does not consistently enhance model performance due to the inherent distribution gap between synthetic and real images. To address this issue, we introduce a novel two-stage framework called bridged transfer, which initially employs synthetic images for fine-tuning a pre-trained model to improve its transferability and subsequently uses real data for rapid adaptation. Alongside, We propose dataset style inversion strategy to improve the stylistic alignment between synthetic and real images. Our proposed methods are evaluated across 10 different datasets and 5 distinct models, demonstrating consistent improvements, with up to 30% accuracy increase on classification tasks. Intriguingly, we note that the enhancements were not yet saturated, indicating that the benefits may further increase with an expanded volume of synthetic data.
4/4/2024