Visual Concept Connectome (VCC): Open World Concept Discovery and their Interlayer Connections in Deep Models

0
🤿
Sign in to get full access
Overview
- Researchers present a new methodology called the Visual Concept Connectome (VCC) to understand the inner workings of deep learning models used in computer vision tasks.
- VCC discovers human-interpretable concepts within the layers of a deep network and analyzes how these concepts are connected across the network.
- This approach allows for a more comprehensive understanding of deep vision models compared to previous methods that could only examine concepts within single layers.
Plain English Explanation
Deep learning models used for image classification and other computer vision tasks are often complex "black boxes" - it can be difficult to understand exactly what the models are learning and how they make their decisions. The Visual Concept Connectome (VCC) aims to shed light on this by automatically discovering the key visual concepts that a deep network has learned, and how those concepts are related and organized across the network's layers.
Imagine a deep network as a multilevel hierarchy, with low-level features like edges and textures in the early layers, building up to higher-level concepts like objects and scenes in the later layers. VCC can map out this hierarchy, identifying the specific concepts captured at each level and how they are combined to solve the overall task. This provides much more transparency into the model's inner workings compared to just looking at the final classification outputs.
VCC's unsupervised approach means it can discover these concepts without any prior information about what the network should be learning. It simply analyzes the patterns in the network's activations to deduce the underlying visual concepts. This allows VCC to uncover insights that may not have been anticipated by the model's designers.
The researchers show how VCC can be used not only to understand successful models, but also to debug and diagnose issues when models fail at their tasks. By tracing where and how the concept representations break down, VCC can pinpoint the root causes of a model's mistakes.
Technical Explanation
The key innovation of the Visual Concept Connectome (VCC) approach is that it can discover and analyze visual concepts across multiple layers of a deep network, rather than just within individual layers. Previous methods could only examine the concepts learned in isolated layers, but VCC reveals how these concepts are connected and organized hierarchically throughout the network.
VCC works by first identifying the dominant visual concepts represented in each layer of the network. It does this in an unsupervised way by clustering the network's activations and assigning semantic labels to the resulting clusters. This yields a set of interpretable concepts at each layer.
Next, VCC examines the relationships between these concepts across layers. It computes the connection strengths between concepts in adjacent layers, forming a "connectome" that shows how higher-level concepts are built up from lower-level ones. This reveals the hierarchical structure of the network's visual representations.
The researchers demonstrate VCC on deep image classification models, showing how it can uncover interesting insights. For example, VCC can identify branching points in the network where concepts diverge, or pinpoint where the model's concept representations break down in failure cases. This provides valuable diagnostic information beyond just looking at the model's final outputs.
Critical Analysis
A key strength of the VCC approach is its ability to analyze deep networks in a fully unsupervised manner, without requiring any prior knowledge about the specific task or model. This allows it to potentially uncover novel or unexpected insights that may be missed by more constrained analyses.
However, a limitation is that the semantic interpretations of the discovered concepts still rely on human judgment to some extent. While VCC can automatically cluster the network activations, assigning meaningful labels to those clusters requires human intervention and can be somewhat subjective.
Additionally, the computational complexity of VCC may be a practical concern, especially for very large and deep networks. The authors mention that runtime scales quadratically with the number of layers, which could make VCC infeasible for the largest modern vision models.
Further research could explore ways to make the concept discovery and labeling more automated and scalable. Integrating VCC with other network interpretation techniques, such as attribution methods, may also yield complementary insights. Overall, the VCC framework represents a promising step toward greater transparency and understanding of deep vision models.
Conclusion
The Visual Concept Connectome (VCC) provides a powerful new tool for opening up the "black box" of deep learning models used in computer vision. By automatically discovering the key visual concepts represented across a network's layers, and analyzing how those concepts are organized and connected, VCC offers unprecedented visibility into the inner workings of these complex models.
This capability has important applications, from helping researchers understand what deep networks are truly learning, to enabling model debugging and failure analysis. As deep learning continues to advance and become more widely deployed, tools like VCC will be crucial for building trust, confidence and accountability in these influential AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤿
0
Visual Concept Connectome (VCC): Open World Concept Discovery and their Interlayer Connections in Deep Models
Matthew Kowal, Richard P. Wildes, Konstantinos G. Derpanis
Understanding what deep network models capture in their learned representations is a fundamental challenge in computer vision. We present a new methodology to understanding such vision models, the Visual Concept Connectome (VCC), which discovers human interpretable concepts and their interlayer connections in a fully unsupervised manner. Our approach simultaneously reveals fine-grained concepts at a layer, connection weightings across all layers and is amendable to global analysis of network structure (e.g., branching pattern of hierarchical concept assemblies). Previous work yielded ways to extract interpretable concepts from single layers and examine their impact on classification, but did not afford multilayer concept analysis across an entire network architecture. Quantitative and qualitative empirical results show the effectiveness of VCCs in the domain of image classification. Also, we leverage VCCs for the application of failure mode debugging to reveal where mistakes arise in deep networks.
Read more4/11/2024

0
Automatic Discovery of Visual Circuits
Achyuta Rajaram, Neil Chowdhury, Antonio Torralba, Jacob Andreas, Sarah Schwettmann
To date, most discoveries of network subcomponents that implement human-interpretable computations in deep vision models have involved close study of single units and large amounts of human labor. We explore scalable methods for extracting the subgraph of a vision model's computational graph that underlies recognition of a specific visual concept. We introduce a new method for identifying these subgraphs: specifying a visual concept using a few examples, and then tracing the interdependence of neuron activations across layers, or their functional connectivity. We find that our approach extracts circuits that causally affect model output, and that editing these circuits can defend large pretrained models from adversarial attacks.
Read more4/23/2024

0
Connectivity-Inspired Network for Context-Aware Recognition
Gianluca Carloni, Sara Colantonio
The aim of this paper is threefold. We inform the AI practitioner about the human visual system with an extensive literature review; we propose a novel biologically motivated neural network for image classification; and, finally, we present a new plug-and-play module to model context awareness. We focus on the effect of incorporating circuit motifs found in biological brains to address visual recognition. Our convolutional architecture is inspired by the connectivity of human cortical and subcortical streams, and we implement bottom-up and top-down modulations that mimic the extensive afferent and efferent connections between visual and cognitive areas. Our Contextual Attention Block is simple and effective and can be integrated with any feed-forward neural network. It infers weights that multiply the feature maps according to their causal influence on the scene, modeling the co-occurrence of different objects in the image. We place our module at different bottlenecks to infuse a hierarchical context awareness into the model. We validated our proposals through image classification experiments on benchmark data and found a consistent improvement in performance and the robustness of the produced explanations via class activation. Our code is available at https://github.com/gianlucarloni/CoCoReco.
Read more9/9/2024
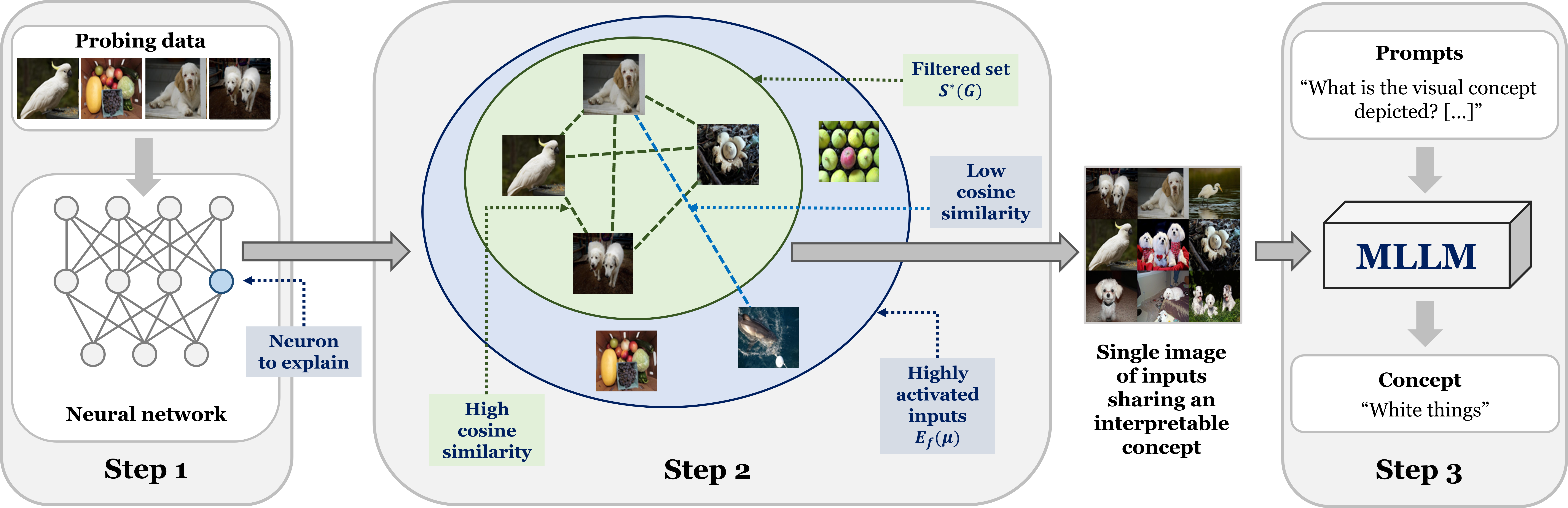
0
LLM-assisted Concept Discovery: Automatically Identifying and Explaining Neuron Functions
Nhat Hoang-Xuan, Minh Vu, My T. Thai
Providing textual concept-based explanations for neurons in deep neural networks (DNNs) is of importance in understanding how a DNN model works. Prior works have associated concepts with neurons based on examples of concepts or a pre-defined set of concepts, thus limiting possible explanations to what the user expects, especially in discovering new concepts. Furthermore, defining the set of concepts requires manual work from the user, either by directly specifying them or collecting examples. To overcome these, we propose to leverage multimodal large language models for automatic and open-ended concept discovery. We show that, without a restricted set of pre-defined concepts, our method gives rise to novel interpretable concepts that are more faithful to the model's behavior. To quantify this, we validate each concept by generating examples and counterexamples and evaluating the neuron's response on this new set of images. Collectively, our method can discover concepts and simultaneously validate them, providing a credible automated tool to explain deep neural networks.
Read more6/14/2024