LLM-assisted Concept Discovery: Automatically Identifying and Explaining Neuron Functions
2406.08572
0
0
Abstract
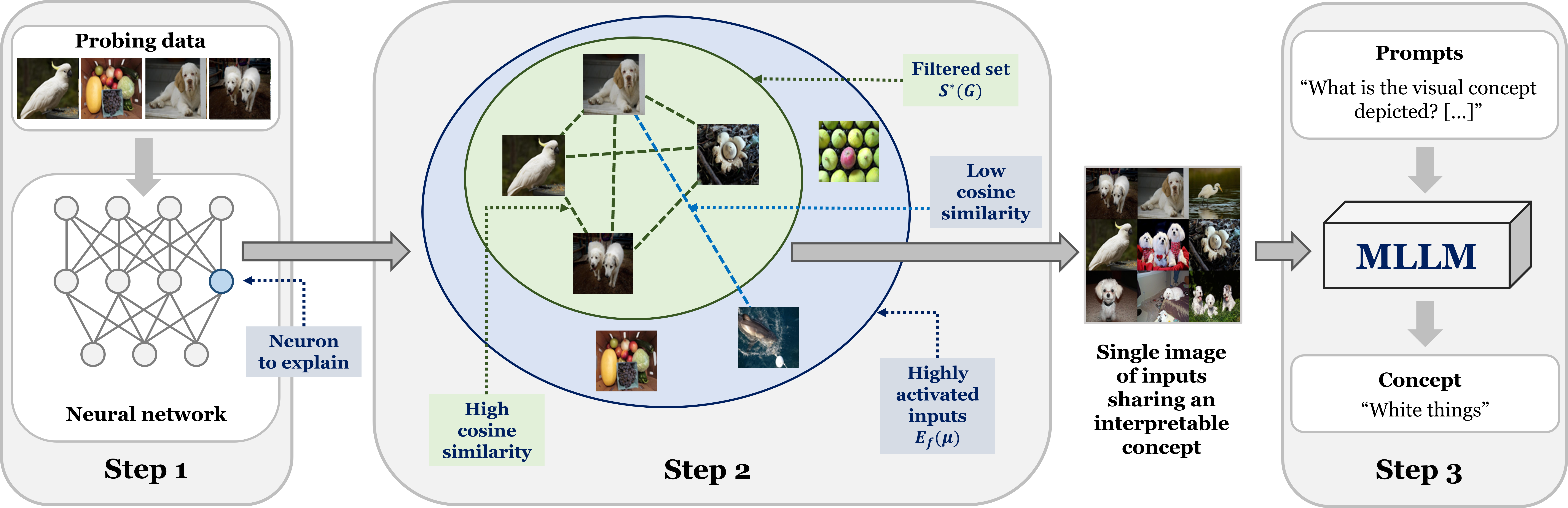
Providing textual concept-based explanations for neurons in deep neural networks (DNNs) is of importance in understanding how a DNN model works. Prior works have associated concepts with neurons based on examples of concepts or a pre-defined set of concepts, thus limiting possible explanations to what the user expects, especially in discovering new concepts. Furthermore, defining the set of concepts requires manual work from the user, either by directly specifying them or collecting examples. To overcome these, we propose to leverage multimodal large language models for automatic and open-ended concept discovery. We show that, without a restricted set of pre-defined concepts, our method gives rise to novel interpretable concepts that are more faithful to the model's behavior. To quantify this, we validate each concept by generating examples and counterexamples and evaluating the neuron's response on this new set of images. Collectively, our method can discover concepts and simultaneously validate them, providing a credible automated tool to explain deep neural networks.
Create account to get full access
Overview
- This paper presents a novel approach for automatically identifying and explaining the functions of individual neurons in large language models (LLMs) using natural language processing techniques.
- The proposed method, called LLM-assisted Concept Discovery, aims to bridge the gap between the abstract representations learned by LLMs and the human-interpretable concepts that underlie them.
- The authors demonstrate the effectiveness of their approach through experiments on various LLM architectures, showing how it can uncover meaningful neuron functions and provide intuitive explanations for them.
Plain English Explanation
The paper describes a new technique for understanding how large language models (LLMs) like GPT-3 work under the hood. LLMs are powerful AI systems that can generate human-like text, but their inner workings are often opaque and difficult for humans to comprehend.
The researchers developed a method called LLM-assisted Concept Discovery that can automatically identify the specific "concepts" or ideas that individual neurons in an LLM are representing. For example, one neuron might specialize in recognizing names of cities, while another might be tuned to detect emotions in text. Previous research has shown that LLMs do learn these kinds of meaningful concepts, but it's been challenging to figure out exactly what each neuron is doing.
The new technique uses natural language processing to analyze the activations of individual neurons and generate plain-English explanations of their functions. This helps make the inner workings of LLMs more transparent and interpretable to researchers and developers. Other work has also explored ways to make neural networks more interpretable, but this paper presents a novel approach tailored specifically for LLMs.
The authors demonstrate the effectiveness of their method through experiments on various LLM architectures, showing that it can uncover insightful and meaningful neuron functions. This could have important implications for understanding and improving the capabilities of these powerful language models.
Technical Explanation
The core of the LLM-assisted Concept Discovery approach is to leverage the natural language processing capabilities of LLMs themselves to automatically identify and explain the functions of individual neurons. The method works as follows:
- The researchers first select a set of "probe" inputs - carefully crafted text prompts designed to activate specific neuron subsets.
- They then analyze the activations of individual neurons in response to these probe inputs, looking for patterns that suggest the neurons are encoding particular concepts or ideas.
- Finally, they generate natural language explanations for the identified neuron functions by prompting the LLM to describe what each neuron seems to be representing.
The authors evaluate their approach on several state-of-the-art LLM architectures, including GPT-3 and T5. They show that the technique can uncover a diverse range of meaningful neuron functions, from detecting named entities and sentiment to tracking discourse structure and reasoning about abstract concepts.
Importantly, the explanations provided by the LLM-assisted method are not just lists of keywords or features, but rather natural language descriptions that can be readily understood by human researchers and developers. This represents a significant advance over previous interpretability techniques that rely more on statistical analysis or feature visualization.
Critical Analysis
The LLM-assisted Concept Discovery approach presents a promising step forward in making large language models more transparent and interpretable. By harnessing the language understanding capabilities of the LLMs themselves, the method can provide intuitive explanations of neuron functions that align well with human intuitions.
However, the paper also acknowledges some important limitations and caveats. First, the technique is constrained by the coverage and accuracy of the LLM used to generate the explanations - if the LLM has biases or gaps in its knowledge, these may be reflected in the explanations. There is also the potential for circularity, where the LLM's own internal representations influence the way it describes its own neurons.
Additionally, the paper only explores the identification and explanation of individual neuron functions. While this provides valuable insights, the overall behavior of an LLM ultimately emerges from the complex interactions between many neurons. Techniques for understanding these higher-level, system-wide dynamics remain an important area for future research.
It will also be crucial to further validate the explanations provided by the LLM-assisted method, ensuring they align with human intuitions and can be used to meaningfully improve LLM performance and robustness. User studies and comparisons to other interpretability approaches will be important next steps.
Conclusion
The LLM-assisted Concept Discovery method represents an exciting advancement in the quest to make large language models more transparent and interpretable. By leveraging the natural language processing capabilities of LLMs themselves, the technique can uncover the functions of individual neurons and provide human-understandable explanations of their inner workings.
While the approach has some limitations and areas for further research, it demonstrates the potential for AI systems to help explain their own behaviors and decisions. As LLMs become increasingly influential in our daily lives, techniques like this will be crucial for building trust, accountability, and a deeper understanding of these powerful technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
From Neural Activations to Concepts: A Survey on Explaining Concepts in Neural Networks
Jae Hee Lee, Sergio Lanza, Stefan Wermter
0
0
In this paper, we review recent approaches for explaining concepts in neural networks. Concepts can act as a natural link between learning and reasoning: once the concepts are identified that a neural learning system uses, one can integrate those concepts with a reasoning system for inference or use a reasoning system to act upon them to improve or enhance the learning system. On the other hand, knowledge can not only be extracted from neural networks but concept knowledge can also be inserted into neural network architectures. Since integrating learning and reasoning is at the core of neuro-symbolic AI, the insights gained from this survey can serve as an important step towards realizing neuro-symbolic AI based on explainable concepts.
5/6/2024

A Self-explaining Neural Architecture for Generalizable Concept Learning
Sanchit Sinha, Guangzhi Xiong, Aidong Zhang
0
0
With the wide proliferation of Deep Neural Networks in high-stake applications, there is a growing demand for explainability behind their decision-making process. Concept learning models attempt to learn high-level 'concepts' - abstract entities that align with human understanding, and thus provide interpretability to DNN architectures. However, in this paper, we demonstrate that present SOTA concept learning approaches suffer from two major problems - lack of concept fidelity wherein the models fail to learn consistent concepts among similar classes and limited concept interoperability wherein the models fail to generalize learned concepts to new domains for the same task. Keeping these in mind, we propose a novel self-explaining architecture for concept learning across domains which - i) incorporates a new concept saliency network for representative concept selection, ii) utilizes contrastive learning to capture representative domain invariant concepts, and iii) uses a novel prototype-based concept grounding regularization to improve concept alignment across domains. We demonstrate the efficacy of our proposed approach over current SOTA concept learning approaches on four widely used real-world datasets. Empirical results show that our method improves both concept fidelity measured through concept overlap and concept interoperability measured through domain adaptation performance.
5/7/2024

CoSy: Evaluating Textual Explanations of Neurons
Laura Kopf, Philine Lou Bommer, Anna Hedstrom, Sebastian Lapuschkin, Marina M. -C. Hohne, Kirill Bykov
0
0
A crucial aspect of understanding the complex nature of Deep Neural Networks (DNNs) is the ability to explain learned concepts within their latent representations. While various methods exist to connect neurons to textual descriptions of human-understandable concepts, evaluating the quality of these explanation methods presents a major challenge in the field due to a lack of unified, general-purpose quantitative evaluation. In this work, we introduce CoSy (Concept Synthesis) -- a novel, architecture-agnostic framework to evaluate the quality of textual explanations for latent neurons. Given textual explanations, our proposed framework leverages a generative model conditioned on textual input to create data points representing the textual explanation. Then, the neuron's response to these explanation data points is compared with the response to control data points, providing a quality estimate of the given explanation. We ensure the reliability of our proposed framework in a series of meta-evaluation experiments and demonstrate practical value through insights from benchmarking various concept-based textual explanation methods for Computer Vision tasks, showing that tested explanation methods significantly differ in quality.
5/31/2024

Concept Induction using LLMs: a user experiment for assessment
Adrita Barua, Cara Widmer, Pascal Hitzler
0
0
Explainable Artificial Intelligence (XAI) poses a significant challenge in providing transparent and understandable insights into complex AI models. Traditional post-hoc algorithms, while useful, often struggle to deliver interpretable explanations. Concept-based models offer a promising avenue by incorporating explicit representations of concepts to enhance interpretability. However, existing research on automatic concept discovery methods is often limited by lower-level concepts, costly human annotation requirements, and a restricted domain of background knowledge. In this study, we explore the potential of a Large Language Model (LLM), specifically GPT-4, by leveraging its domain knowledge and common-sense capability to generate high-level concepts that are meaningful as explanations for humans, for a specific setting of image classification. We use minimal textual object information available in the data via prompting to facilitate this process. To evaluate the output, we compare the concepts generated by the LLM with two other methods: concepts generated by humans and the ECII heuristic concept induction system. Since there is no established metric to determine the human understandability of concepts, we conducted a human study to assess the effectiveness of the LLM-generated concepts. Our findings indicate that while human-generated explanations remain superior, concepts derived from GPT-4 are more comprehensible to humans compared to those generated by ECII.
4/19/2024