Visual Concept-driven Image Generation with Text-to-Image Diffusion Model

0
🖼️
Sign in to get full access
Overview
- Existing text-to-image (TTI) diffusion models can generate high-resolution images of complex scenes, and have been extended with personalization techniques to integrate user-illustrated concepts.
- However, generating images with multiple interacting concepts, such as human subjects, remains a challenge.
- This paper proposes a concept-driven TTI personalization framework to address this issue.
Plain English Explanation
The paper discusses a new approach to generating images using text-to-image (TTI) diffusion models. These models are impressive at creating high-quality, detailed images based on textual descriptions. Recent advances have even allowed users to personalize the images by providing their own illustrated concepts, like adding themselves to the image.
However, the ability to combine multiple complex concepts within a single image has been limited. This paper proposes a solution to this problem, using a framework that can learn and integrate different concepts from user-provided illustrations. The key idea is to not only learn custom tokens (or representations) for the concepts, but also to jointly learn latent segmentation masks that can disentangle the different concepts within the user's images.
This joint learning process, using an Expectation Maximization (EM)-like optimization, allows the model to better understand the individual concepts and how they interact. As a result, the model can then generate images that seamlessly combine multiple complex concepts, like a person, a specific object, and a particular background scene.
The paper demonstrates the benefits of this approach through qualitative and quantitative examples, showing how it can handle the fusion of three or more entangled concepts - something that has been a challenge for previous personalized TTI models.
Technical Explanation
The proposed framework builds on existing work that learns custom tokens for user-illustrated concepts, allowing those to interact with the existing text tokens in the TTI model. However, the key innovation is the joint learning of (latent) segmentation masks that disentangle the concepts present in the user-provided image illustrations.
This is achieved through an Expectation Maximization (EM)-like optimization procedure, where the model alternates between learning the custom tokens and estimating the (latent) masks encompassing the corresponding concepts in the user-supplied images. The masks are obtained based on cross-attention, from within the U-Net parameterized latent diffusion model, and subsequent DenseCRF optimization.
The authors show that this joint alternating refinement leads to the learning of better tokens for concepts and, as a by-product, latent masks that can disentangle multiple entangled concepts. They demonstrate the benefits of the proposed approach through qualitative and quantitative examples, highlighting its ability to combine three or more interacting concepts, something that has been a challenge for previous personalized TTI models.
Critical Analysis
The paper presents a thoughtful and well-designed approach to addressing the challenge of generating images with multiple interacting concepts using personalized text-to-image diffusion models. The joint learning of custom tokens and latent segmentation masks is a clever solution that allows the model to better understand and integrate complex concepts.
One potential limitation is the reliance on user-provided image illustrations, which may not always be available or easy for users to create. It would be interesting to see if the framework could be extended to work with other forms of user input, such as textual descriptions of concepts or even rough sketches.
Additionally, the paper does not delve into the potential biases or limitations of the model when it comes to generating images with diverse human representations. As with any AI system, there is a risk of perpetuating societal biases, and the authors could have discussed strategies to mitigate this concern.
Overall, the research presented in this paper represents an important step forward in the field of personalized text-to-image generation, and the proposed concept-driven TTI personalization framework has the potential to enable more expressive and customizable image generation capabilities.
Conclusion
This paper introduces a novel concept-driven text-to-image (TTI) personalization framework that addresses the challenge of generating images with multiple interacting concepts. By jointly learning custom tokens and latent segmentation masks, the model can better understand and integrate complex user-illustrated concepts, enabling the creation of images that seamlessly combine three or more entangled elements.
The proposed approach represents an important advancement in the field of personalized image generation, paving the way for more expressive and customizable AI-powered image creation tools. While the reliance on user-provided illustrations may be a limitation, the framework's ability to disentangle and fuse multiple concepts is a significant step forward and could have wide-ranging applications in areas like digital art, design, and visual storytelling.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🖼️
0
Visual Concept-driven Image Generation with Text-to-Image Diffusion Model
Tanzila Rahman, Shweta Mahajan, Hsin-Ying Lee, Jian Ren, Sergey Tulyakov, Leonid Sigal
Text-to-image (TTI) diffusion models have demonstrated impressive results in generating high-resolution images of complex and imaginative scenes. Recent approaches have further extended these methods with personalization techniques that allow them to integrate user-illustrated concepts (e.g., the user him/herself) using a few sample image illustrations. However, the ability to generate images with multiple interacting concepts, such as human subjects, as well as concepts that may be entangled in one, or across multiple, image illustrations remains illusive. In this work, we propose a concept-driven TTI personalization framework that addresses these core challenges. We build on existing works that learn custom tokens for user-illustrated concepts, allowing those to interact with existing text tokens in the TTI model. However, importantly, to disentangle and better learn the concepts in question, we jointly learn (latent) segmentation masks that disentangle these concepts in user-provided image illustrations. We do so by introducing an Expectation Maximization (EM)-like optimization procedure where we alternate between learning the custom tokens and estimating (latent) masks encompassing corresponding concepts in user-supplied images. We obtain these masks based on cross-attention, from within the U-Net parameterized latent diffusion model and subsequent DenseCRF optimization. We illustrate that such joint alternating refinement leads to the learning of better tokens for concepts and, as a by-product, latent masks. We illustrate the benefits of the proposed approach qualitatively and quantitatively with several examples and use cases that can combine three or more entangled concepts.
Read more7/18/2024
0
Non-confusing Generation of Customized Concepts in Diffusion Models
Wang Lin, Jingyuan Chen, Jiaxin Shi, Yichen Zhu, Chen Liang, Junzhong Miao, Tao Jin, Zhou Zhao, Fei Wu, Shuicheng Yan, Hanwang Zhang
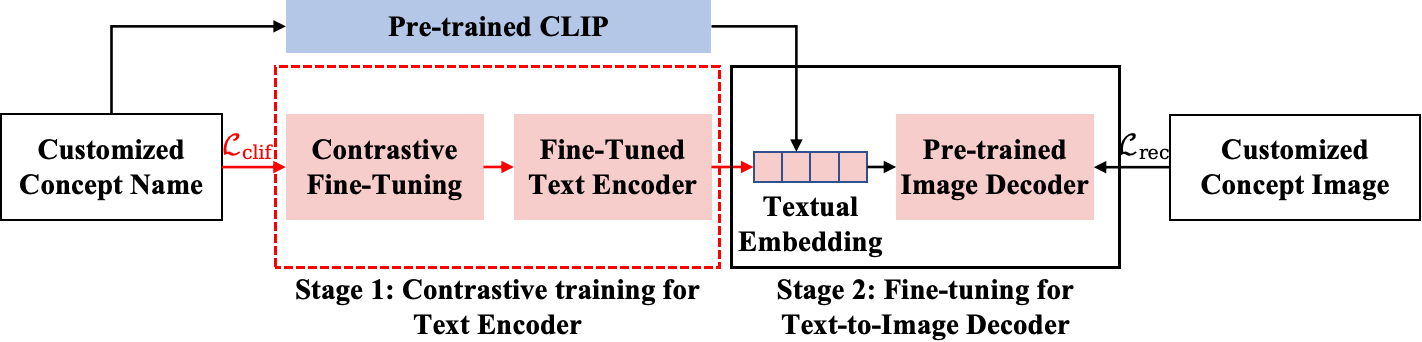
We tackle the common challenge of inter-concept visual confusion in compositional concept generation using text-guided diffusion models (TGDMs). It becomes even more pronounced in the generation of customized concepts, due to the scarcity of user-provided concept visual examples. By revisiting the two major stages leading to the success of TGDMs -- 1) contrastive image-language pre-training (CLIP) for text encoder that encodes visual semantics, and 2) training TGDM that decodes the textual embeddings into pixels -- we point that existing customized generation methods only focus on fine-tuning the second stage while overlooking the first one. To this end, we propose a simple yet effective solution called CLIF: contrastive image-language fine-tuning. Specifically, given a few samples of customized concepts, we obtain non-confusing textual embeddings of a concept by fine-tuning CLIP via contrasting a concept and the over-segmented visual regions of other concepts. Experimental results demonstrate the effectiveness of CLIF in preventing the confusion of multi-customized concept generation.
Read more5/14/2024

0
An Improved Method for Personalizing Diffusion Models
Yan Zeng, Masanori Suganuma, Takayuki Okatani
Diffusion models have demonstrated impressive image generation capabilities. Personalized approaches, such as textual inversion and Dreambooth, enhance model individualization using specific images. These methods enable generating images of specific objects based on diverse textual contexts. Our proposed approach aims to retain the model's original knowledge during new information integration, resulting in superior outcomes while necessitating less training time compared to Dreambooth and textual inversion.
Read more7/9/2024
0
Concept Weaver: Enabling Multi-Concept Fusion in Text-to-Image Models
Gihyun Kwon, Simon Jenni, Dingzeyu Li, Joon-Young Lee, Jong Chul Ye, Fabian Caba Heilbron
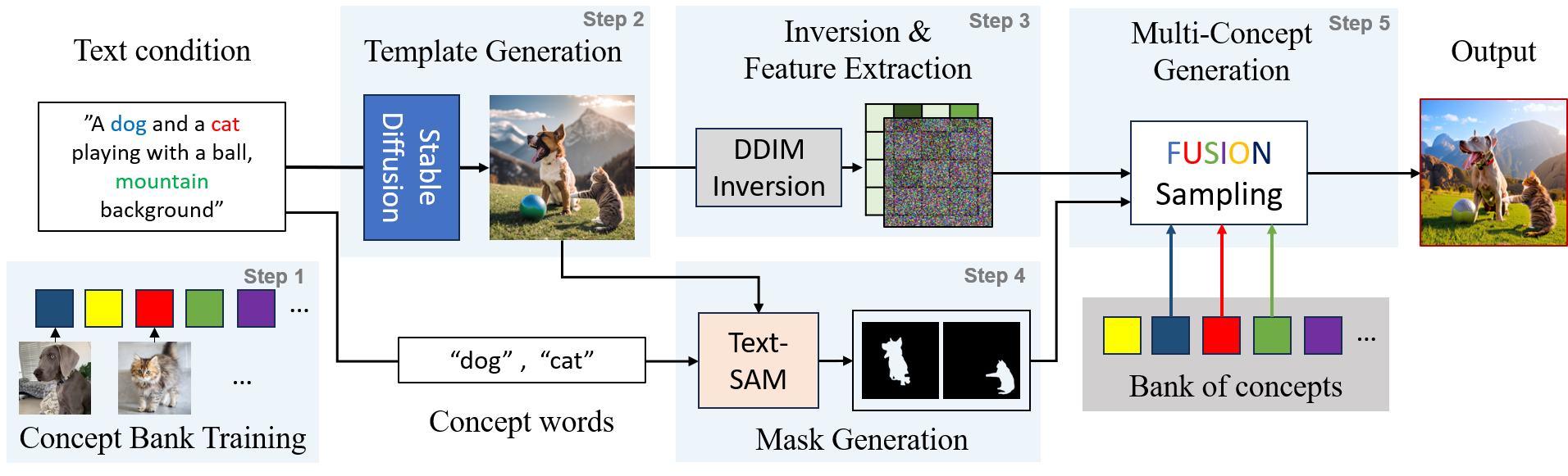
While there has been significant progress in customizing text-to-image generation models, generating images that combine multiple personalized concepts remains challenging. In this work, we introduce Concept Weaver, a method for composing customized text-to-image diffusion models at inference time. Specifically, the method breaks the process into two steps: creating a template image aligned with the semantics of input prompts, and then personalizing the template using a concept fusion strategy. The fusion strategy incorporates the appearance of the target concepts into the template image while retaining its structural details. The results indicate that our method can generate multiple custom concepts with higher identity fidelity compared to alternative approaches. Furthermore, the method is shown to seamlessly handle more than two concepts and closely follow the semantic meaning of the input prompt without blending appearances across different subjects.
Read more4/8/2024