Visual Grounding with Attention-Driven Constraint Balancing

0
Sign in to get full access
Overview
- This paper presents a new approach for visual grounding, which is the task of associating visual elements in an image with corresponding textual descriptions.
- The key idea is to use an attention-driven constraint balancing mechanism to better align the visual and textual representations during training.
- The proposed method aims to improve upon existing visual grounding techniques by capturing the complex relationships between visual and linguistic cues more effectively.
Plain English Explanation
The paper focuses on the problem of visual grounding, which is about connecting parts of an image (like objects, people, or scenes) with the words that describe them. Imagine looking at a picture of a park and being able to say "there's a tree" or "a person is walking" - that's visual grounding.
The researchers developed a new technique that uses "attention" to better understand the connections between the visual and textual information. Attention is a way for AI models to focus on the most relevant parts of the input when making decisions. In this case, the attention mechanism helps the model align the visual elements in the image with the corresponding words in the text description.
The key innovation is a "constraint balancing" approach, which ensures that the model maintains a good balance between the visual and textual cues during training. This helps the model build a stronger understanding of how the visual and linguistic information relate to each other, leading to better performance on visual grounding tasks.
Overall, this work advances the state-of-the-art in visual grounding by tackling the challenge of effectively combining visual and textual information. By using attention and constraint balancing, the proposed method can better capture the complex relationships between images and their descriptions.
Technical Explanation
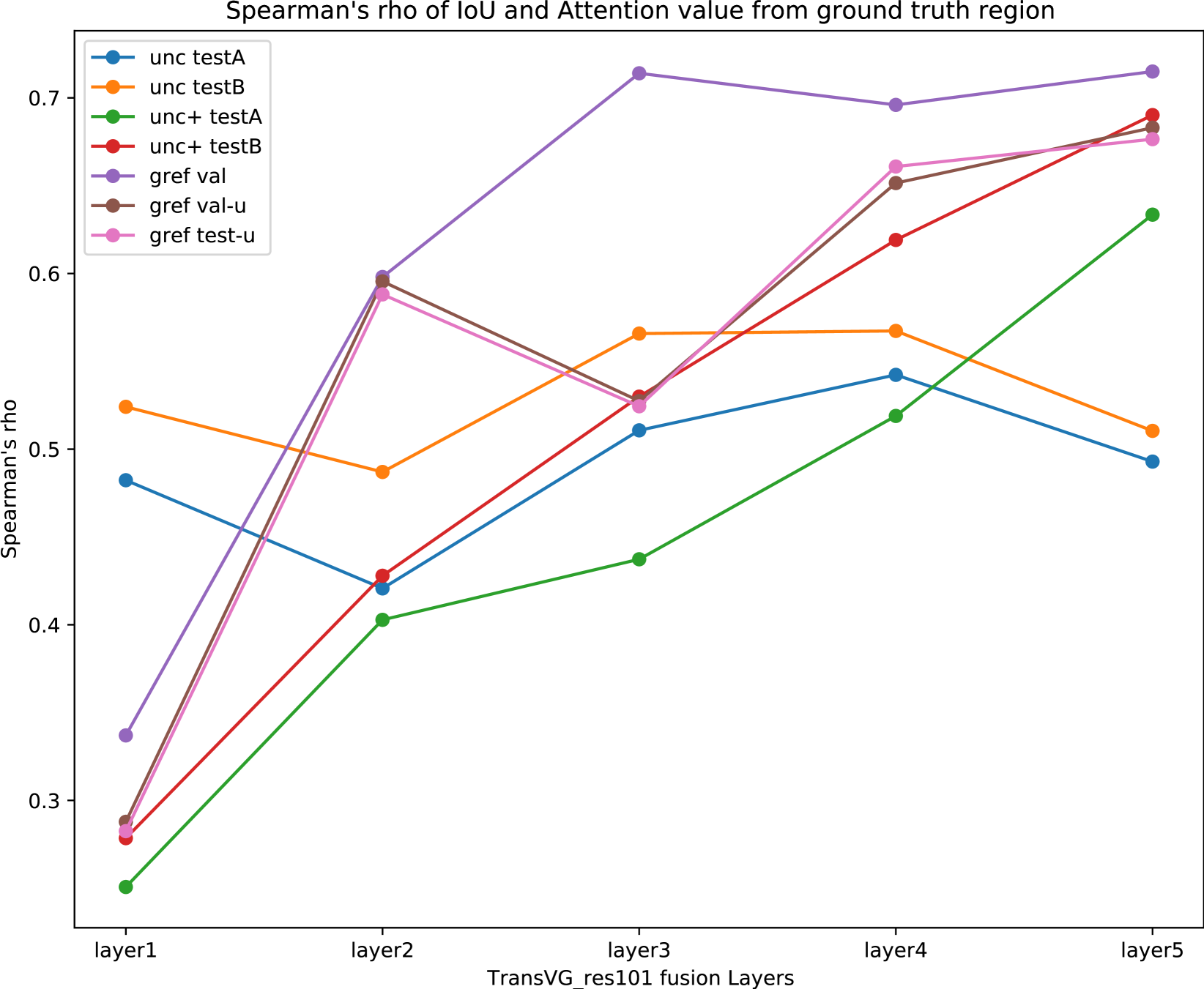
The paper introduces a new visual grounding framework called Attention-Driven Constraint Balancing (ADCB). The core idea is to use an attention-driven mechanism to better align the visual and textual representations during training.
The authors first extract visual and textual features using pre-trained encoders. They then apply an attention module to compute attention weights that indicate the relevance of each visual element to the textual description. These attention weights are used to guide the optimization process and ensure a balanced contribution from the visual and textual cues.
Specifically, the ADCB framework incorporates two loss terms: a visual-textual matching loss and a constraint balancing loss. The matching loss encourages the model to correctly associate the visual and textual representations. The balancing loss ensures that the model does not over-rely on either the visual or textual input, maintaining a healthy balance between the two modalities.
The authors evaluate their approach on several visual grounding benchmarks, including four-ways-to-improve-verbo-visual-fusion, naturally-supervised-3d-visual-grounding-language-regularized, and hierarchical-point-attention-indoor-3d-object-detection. The results demonstrate that ADCB outperforms previous state-of-the-art methods, highlighting the effectiveness of the attention-driven constraint balancing mechanism.
Critical Analysis
The paper presents a compelling approach to visual grounding, but there are a few potential limitations and areas for further research:
-
Dataset Bias: The authors evaluate their method on a limited set of visual grounding benchmarks. It would be important to test the approach on a more diverse range of datasets to ensure it generalizes well, as adversarial-robustness-visual-grounding-multimodal-large-language have shown datasets can exhibit significant biases.
-
Computational Complexity: The attention-driven constraint balancing mechanism may add computational overhead compared to simpler visual grounding methods. The authors should analyze the runtime and memory requirements of their approach to understand its practical deployment feasibility.
-
Interpretability: While the attention mechanism provides some insight into the model's decision-making process, a more thorough analysis of the learned representations and their interpretability would be valuable. This could help users understand the model's behavior and build trust in its outputs.
-
Real-World Applicability: The paper focuses on academic benchmarks, but it would be interesting to see how the ADCB framework performs on real-world visual grounding tasks, such as in assistive technologies or content moderation systems.
Overall, the paper presents a promising direction for improving visual grounding, but further research is needed to fully understand the strengths, limitations, and practical implications of the proposed approach.
Conclusion
This paper introduces a new visual grounding framework called Attention-Driven Constraint Balancing (ADCB) that uses an attention-driven mechanism to better align visual and textual representations. The key innovation is the constraint balancing loss, which ensures a healthy balance between the visual and textual cues during training.
The results on several benchmark datasets show that ADCB outperforms previous state-of-the-art methods, demonstrating the effectiveness of the attention-driven constraint balancing approach. This work advances the field of visual grounding by providing a more robust and effective way to associate visual elements with their corresponding textual descriptions.
While the paper presents a promising solution, there are still opportunities for further research, such as evaluating the approach on more diverse datasets, analyzing its computational complexity, and exploring its interpretability and real-world applicability. Overall, this research represents an important step forward in the challenging task of visual grounding.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Visual Grounding with Attention-Driven Constraint Balancing
Weitai Kang, Luowei Zhou, Junyi Wu, Changchang Sun, Yan Yan
Unlike Object Detection, Visual Grounding task necessitates the detection of an object described by complex free-form language. To simultaneously model such complex semantic and visual representations, recent state-of-the-art studies adopt transformer-based models to fuse features from both modalities, further introducing various modules that modulate visual features to align with the language expressions and eliminate the irrelevant redundant information. However, their loss function, still adopting common Object Detection losses, solely governs the bounding box regression output, failing to fully optimize for the above objectives. To tackle this problem, in this paper, we first analyze the attention mechanisms of transformer-based models. Building upon this, we further propose a novel framework named Attention-Driven Constraint Balancing (AttBalance) to optimize the behavior of visual features within language-relevant regions. Extensive experimental results show that our method brings impressive improvements. Specifically, we achieve constant improvements over five different models evaluated on four different benchmarks. Moreover, we attain a new state-of-the-art performance by integrating our method into QRNet.
Read more7/9/2024
0
An Efficient and Effective Transformer Decoder-Based Framework for Multi-Task Visual Grounding
Wei Chen, Long Chen, Yu Wu
Most advanced visual grounding methods rely on Transformers for visual-linguistic feature fusion. However, these Transformer-based approaches encounter a significant drawback: the computational costs escalate quadratically due to the self-attention mechanism in the Transformer Encoder, particularly when dealing with high-resolution images or long context sentences. This quadratic increase in computational burden restricts the applicability of visual grounding to more intricate scenes, such as conversation-based reasoning segmentation, which involves lengthy language expressions. In this paper, we propose an efficient and effective multi-task visual grounding (EEVG) framework based on Transformer Decoder to address this issue, which reduces the cost in both language and visual aspects. In the language aspect, we employ the Transformer Decoder to fuse visual and linguistic features, where linguistic features are input as memory and visual features as queries. This allows fusion to scale linearly with language expression length. In the visual aspect, we introduce a parameter-free approach to reduce computation by eliminating background visual tokens based on attention scores. We then design a light mask head to directly predict segmentation masks from the remaining sparse feature maps. Extensive results and ablation studies on benchmarks demonstrate the efficiency and effectiveness of our approach. Code is available in https://github.com/chenwei746/EEVG.
Read more8/6/2024

0
SegVG: Transferring Object Bounding Box to Segmentation for Visual Grounding
Weitai Kang, Gaowen Liu, Mubarak Shah, Yan Yan
Different from Object Detection, Visual Grounding deals with detecting a bounding box for each text-image pair. This one box for each text-image data provides sparse supervision signals. Although previous works achieve impressive results, their passive utilization of annotation, i.e. the sole use of the box annotation as regression ground truth, results in a suboptimal performance. In this paper, we present SegVG, a novel method transfers the box-level annotation as Segmentation signals to provide an additional pixel-level supervision for Visual Grounding. Specifically, we propose the Multi-layer Multi-task Encoder-Decoder as the target grounding stage, where we learn a regression query and multiple segmentation queries to ground the target by regression and segmentation of the box in each decoding layer, respectively. This approach allows us to iteratively exploit the annotation as signals for both box-level regression and pixel-level segmentation. Moreover, as the backbones are typically initialized by pretrained parameters learned from unimodal tasks and the queries for both regression and segmentation are static learnable embeddings, a domain discrepancy remains among these three types of features, which impairs subsequent target grounding. To mitigate this discrepancy, we introduce the Triple Alignment module, where the query, text, and vision tokens are triangularly updated to share the same space by triple attention mechanism. Extensive experiments on five widely used datasets validate our state-of-the-art (SOTA) performance.
Read more7/9/2024

0
Learning Visual Grounding from Generative Vision and Language Model
Shijie Wang, Dahun Kim, Ali Taalimi, Chen Sun, Weicheng Kuo
Visual grounding tasks aim to localize image regions based on natural language references. In this work, we explore whether generative VLMs predominantly trained on image-text data could be leveraged to scale up the text annotation of visual grounding data. We find that grounding knowledge already exists in generative VLM and can be elicited by proper prompting. We thus prompt a VLM to generate object-level descriptions by feeding it object regions from existing object detection datasets. We further propose attribute modeling to explicitly capture the important object attributes, and spatial relation modeling to capture inter-object relationship, both of which are common linguistic pattern in referring expression. Our constructed dataset (500K images, 1M objects, 16M referring expressions) is one of the largest grounding datasets to date, and the first grounding dataset with purely model-generated queries and human-annotated objects. To verify the quality of this data, we conduct zero-shot transfer experiments to the popular RefCOCO benchmarks for both referring expression comprehension (REC) and segmentation (RES) tasks. On both tasks, our model significantly outperform the state-of-the-art approaches without using human annotated visual grounding data. Our results demonstrate the promise of generative VLM to scale up visual grounding in the real world. Code and models will be released.
Read more7/23/2024