Visual Prompt Tuning in Null Space for Continual Learning

0

Sign in to get full access
Overview
- This paper proposes a novel method called Visual Prompt Tuning in Null Space (VPTN) for continual learning, which aims to overcome the catastrophic forgetting problem in deep neural networks.
- VPTN introduces a prompt-based approach that tunes the visual prompts in the null space of the model's parameters, allowing the model to learn new tasks without forgetting previous ones.
- The paper presents experimental results on various continual learning benchmarks, demonstrating the effectiveness of VPTN in achieving high performance while mitigating catastrophic forgetting.
Plain English Explanation
In machine learning, a common challenge is the "catastrophic forgetting" problem, where a model trained on a new task tends to forget what it has learned from previous tasks. The Visual Prompt Tuning in Null Space (VPTN) method proposed in this paper aims to address this issue.
The key idea behind VPTN is to use "prompts" - short text or image inputs that can guide the model to perform a specific task. Instead of modifying the model's internal parameters, VPTN tunes the prompts in a way that they reside in the "null space" of the model's parameters. This means the changes to the prompts do not significantly impact the model's performance on previous tasks, effectively preventing catastrophic forgetting.
By tuning the prompts in the null space, the model can learn new tasks without losing its ability to perform the old ones. This is similar to how human brains can learn new skills without forgetting previous ones. The paper demonstrates the effectiveness of VPTN through experiments on various continual learning benchmarks, showing that it can achieve high performance while mitigating catastrophic forgetting.
Technical Explanation
The paper introduces a novel method called Visual Prompt Tuning in Null Space (VPTN) for continual learning, which aims to overcome the catastrophic forgetting problem in deep neural networks.
The key idea behind VPTN is to use visual prompts, which are short image inputs that can guide the model to perform a specific task. Instead of modifying the model's internal parameters, VPTN tunes the prompts in a way that they reside in the "null space" of the model's parameters. The null space is the subspace of the model's parameter space where changes have a minimal impact on the model's performance on previous tasks.
The authors formulate the prompt tuning problem as an optimization problem, where the goal is to find the optimal prompt that maximizes the model's performance on the current task while minimizing the change in the model's performance on previous tasks. To solve this optimization problem, the authors propose an efficient algorithm that leverages the null space of the model's parameters.
The paper presents extensive experimental results on various continual learning benchmarks, such as Revisiting Power of Prompt Visual Tuning and Memory Space Visual Prompting for Efficient Vision-Language. The results demonstrate that VPTN outperforms existing continual learning methods in terms of both performance and the ability to mitigate catastrophic forgetting.
Critical Analysis
The paper presents a well-designed and thorough study on the problem of continual learning, a crucial challenge in the field of machine learning. The authors' proposed VPTN method offers a promising approach to address the catastrophic forgetting problem by leveraging the null space of the model's parameters.
One potential limitation of the study is the reliance on visual prompts, which may not be suitable for all types of tasks or datasets. It would be interesting to see how VPTN could be extended to handle other modalities, such as text or multimodal prompts, and whether the same principles would still apply.
Additionally, the paper does not explore the interpretability or explainability of the learned prompts. Understanding how the prompts are tuned and their relationship to the model's internal representations could provide valuable insights into the mechanics of the VPTN method and its ability to overcome catastrophic forgetting.
Further research could also investigate the scalability of VPTN, particularly as the number of tasks or the complexity of the tasks increases. Exploring the computational and memory efficiency of the method would be important for its practical applicability in real-world scenarios.
Overall, the VPTN method presented in this paper represents a promising step forward in the field of continual learning, and the authors' experimental results are compelling. Continued research and refinement of this approach could lead to significant advancements in the ability of deep neural networks to learn continually without forgetting.
Conclusion
The Visual Prompt Tuning in Null Space (VPTN) method proposed in this paper offers a novel approach to addressing the catastrophic forgetting problem in continual learning. By tuning visual prompts in the null space of the model's parameters, VPTN can effectively learn new tasks without forgetting previous ones.
The experimental results demonstrate the effectiveness of VPTN in achieving high performance while mitigating catastrophic forgetting, making it a promising technique for a wide range of continual learning applications. As the field of machine learning continues to evolve, methods like VPTN that can enable models to learn continuously and adaptively will become increasingly important.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Visual Prompt Tuning in Null Space for Continual Learning
Yue Lu, Shizhou Zhang, De Cheng, Yinghui Xing, Nannan Wang, Peng Wang, Yanning Zhang
Existing prompt-tuning methods have demonstrated impressive performances in continual learning (CL), by selecting and updating relevant prompts in the vision-transformer models. On the contrary, this paper aims to learn each task by tuning the prompts in the direction orthogonal to the subspace spanned by previous tasks' features, so as to ensure no interference on tasks that have been learned to overcome catastrophic forgetting in CL. However, different from the orthogonal projection in the traditional CNN architecture, the prompt gradient orthogonal projection in the ViT architecture shows completely different and greater challenges, i.e., 1) the high-order and non-linear self-attention operation; 2) the drift of prompt distribution brought by the LayerNorm in the transformer block. Theoretically, we have finally deduced two consistency conditions to achieve the prompt gradient orthogonal projection, which provide a theoretical guarantee of eliminating interference on previously learned knowledge via the self-attention mechanism in visual prompt tuning. In practice, an effective null-space-based approximation solution has been proposed to implement the prompt gradient orthogonal projection. Extensive experimental results demonstrate the effectiveness of anti-forgetting on four class-incremental benchmarks with diverse pre-trained baseline models, and our approach achieves superior performances to state-of-the-art methods. Our code is available at https://github.com/zugexiaodui/VPTinNSforCL.
Read more9/27/2024
🐍
0
Mixture of Experts Meets Prompt-Based Continual Learning
Minh Le, An Nguyen, Huy Nguyen, Trang Nguyen, Trang Pham, Linh Van Ngo, Nhat Ho
Exploiting the power of pre-trained models, prompt-based approaches stand out compared to other continual learning solutions in effectively preventing catastrophic forgetting, even with very few learnable parameters and without the need for a memory buffer. While existing prompt-based continual learning methods excel in leveraging prompts for state-of-the-art performance, they often lack a theoretical explanation for the effectiveness of prompting. This paper conducts a theoretical analysis to unravel how prompts bestow such advantages in continual learning, thus offering a new perspective on prompt design. We first show that the attention block of pre-trained models like Vision Transformers inherently encodes a special mixture of experts architecture, characterized by linear experts and quadratic gating score functions. This realization drives us to provide a novel view on prefix tuning, reframing it as the addition of new task-specific experts, thereby inspiring the design of a novel gating mechanism termed Non-linear Residual Gates (NoRGa). Through the incorporation of non-linear activation and residual connection, NoRGa enhances continual learning performance while preserving parameter efficiency. The effectiveness of NoRGa is substantiated both theoretically and empirically across diverse benchmarks and pretraining paradigms.
Read more5/24/2024
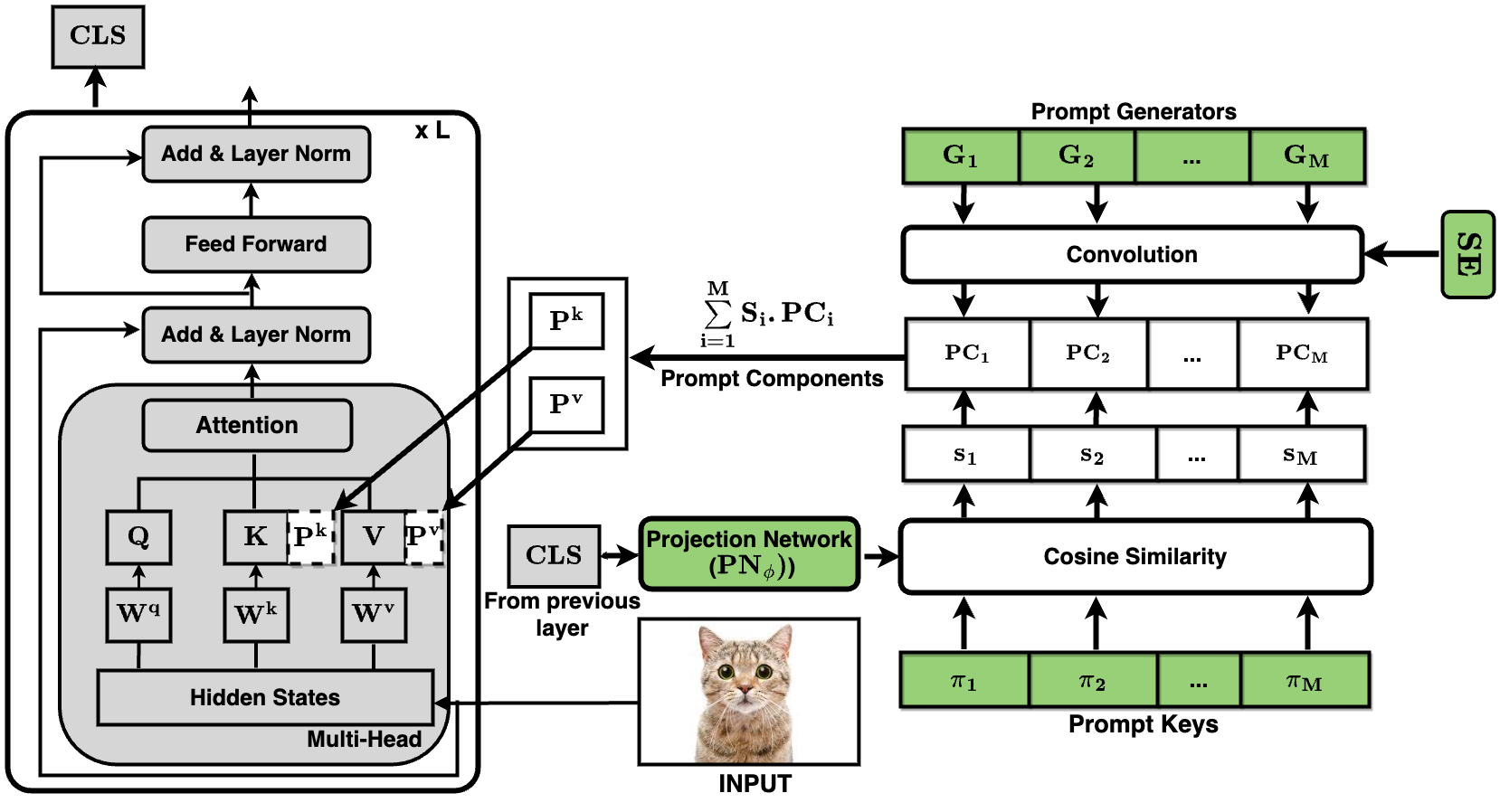
0
Convolutional Prompting meets Language Models for Continual Learning
Anurag Roy, Riddhiman Moulick, Vinay K. Verma, Saptarshi Ghosh, Abir Das
Continual Learning (CL) enables machine learning models to learn from continuously shifting new training data in absence of data from old tasks. Recently, pretrained vision transformers combined with prompt tuning have shown promise for overcoming catastrophic forgetting in CL. These approaches rely on a pool of learnable prompts which can be inefficient in sharing knowledge across tasks leading to inferior performance. In addition, the lack of fine-grained layer specific prompts does not allow these to fully express the strength of the prompts for CL. We address these limitations by proposing ConvPrompt, a novel convolutional prompt creation mechanism that maintains layer-wise shared embeddings, enabling both layer-specific learning and better concept transfer across tasks. The intelligent use of convolution enables us to maintain a low parameter overhead without compromising performance. We further leverage Large Language Models to generate fine-grained text descriptions of each category which are used to get task similarity and dynamically decide the number of prompts to be learned. Extensive experiments demonstrate the superiority of ConvPrompt and improves SOTA by ~3% with significantly less parameter overhead. We also perform strong ablation over various modules to disentangle the importance of different components.
Read more4/1/2024

0
Efficient Prompt Tuning by Multi-Space Projection and Prompt Fusion
Pengxiang Lan, Enneng Yang, Yuting Liu, Guibing Guo, Linying Jiang, Jianzhe Zhao, Xingwei Wang
Prompt tuning is a promising method to fine-tune a pre-trained language model without retraining its large-scale parameters. Instead, it attaches a soft prompt to the input text, whereby downstream tasks can be well adapted by merely learning the embeddings of prompt tokens. Nevertheless, existing methods still suffer from two challenges: (i) they are hard to balance accuracy and efficiency. A longer (shorter) soft prompt generally leads to a better(worse) accuracy but at the cost of more (less) training time. (ii)The performance may not be consistent when adapting to different downstream tasks. We attribute it to the same embedding space but responsible for different requirements of downstream tasks. To address these issues, we propose an Efficient Prompt Tuning method (EPT) by multi-space projection and prompt fusion. Specifically, it decomposes a given soft prompt into a shorter prompt and two low-rank matrices, significantly reducing the training time. Accuracy is also enhanced by leveraging low-rank matrices and the short prompt as additional knowledge sources to enrich the semantics of the original short prompt. In addition, we project the soft prompt into multiple subspaces to improve the performance consistency, and then adaptively learn the combination weights of different spaces through a gating network. Experiments on 13 natural language processing downstream tasks show that our method significantly and consistently outperforms 11 comparison methods with the relative percentage of improvements up to 12.9%, and training time decreased by 14%.
Read more7/2/2024