Visually grounded few-shot word learning in low-resource settings
2306.11371
0
0
Abstract
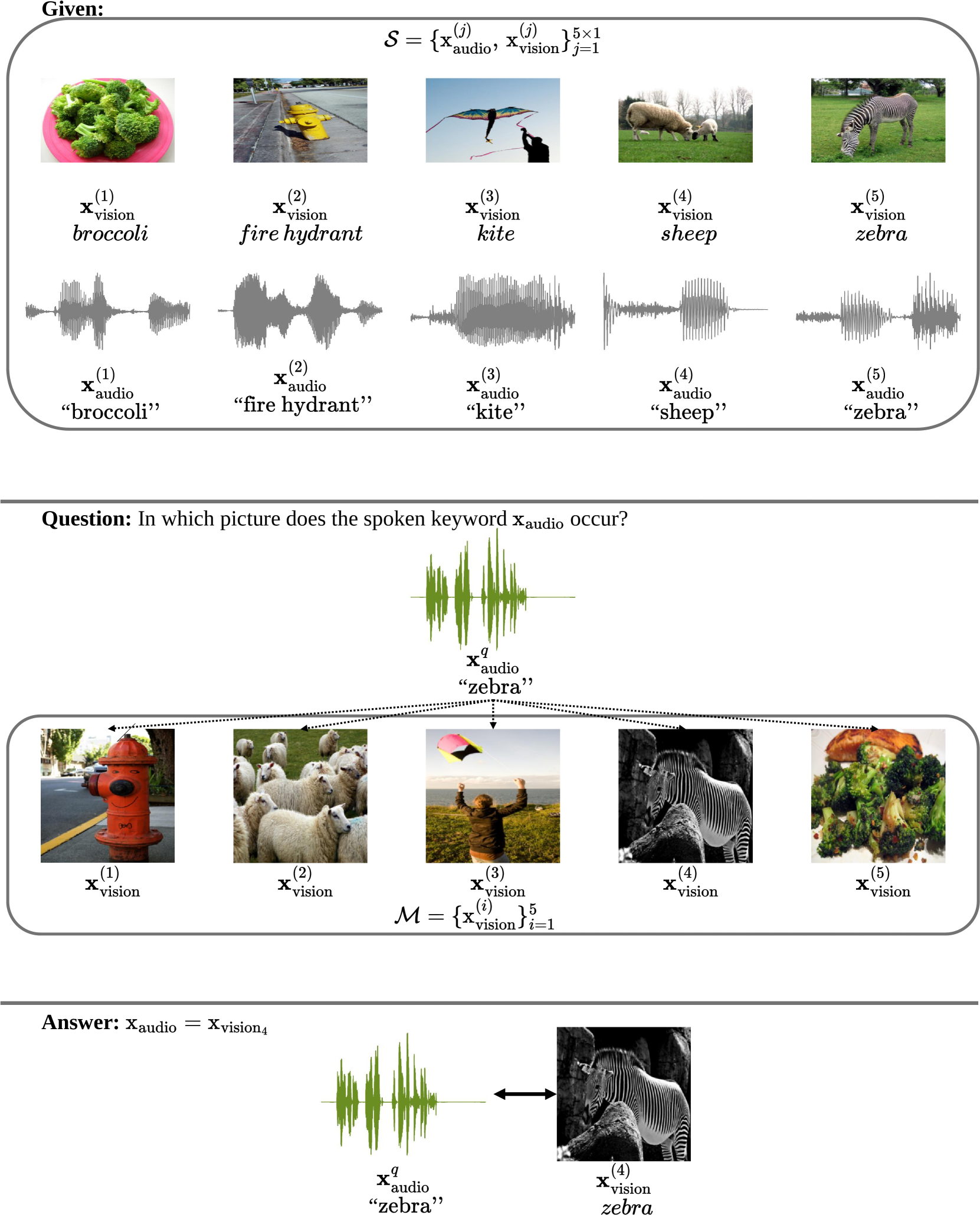
We propose a visually grounded speech model that learns new words and their visual depictions from just a few word-image example pairs. Given a set of test images and a spoken query, we ask the model which image depicts the query word. Previous work has simplified this few-shot learning problem by either using an artificial setting with digit word-image pairs or by using a large number of examples per class. Moreover, all previous studies were performed using English speech-image data. We propose an approach that can work on natural word-image pairs but with less examples, i.e. fewer shots, and then illustrate how this approach can be applied for multimodal few-shot learning in a real low-resource language, Yorub'a. Our approach involves using the given word-image example pairs to mine new unsupervised word-image training pairs from large collections of unlabelled speech and images. Additionally, we use a word-to-image attention mechanism to determine word-image similarity. With this new model, we achieve better performance with fewer shots than previous approaches on an existing English benchmark. Many of the model's mistakes are due to confusion between visual concepts co-occurring in similar contexts. The experiments on Yorub'a show the benefit of transferring knowledge from a multimodal model trained on a larger set of English speech-image data.
Create account to get full access
Overview
- This paper explores how to enable visually grounded few-shot word learning in low-resource language settings.
- The researchers propose new multimodal deep learning architectures that can acquire vocabulary from limited visual and linguistic input.
- The goal is to develop models that can efficiently learn words and their meanings, even with minimal training data, similar to how humans learn language.
Plain English Explanation
The paper focuses on the challenge of teaching computers new words and their meanings, especially for languages that have limited online data and resources available. The researchers wanted to develop AI systems that can learn vocabulary in a similar way to how young children pick up language - by connecting what they see in the world around them to the words they hear.
To do this, they created new deep learning models that can take in both visual information (like images) and linguistic information (like words and sentences) to learn the associations between them. The key innovation is that these models can learn new words and their meanings very efficiently, even when only shown a few examples.
This is important for building AI assistants and conversational agents that can operate in low-resource language settings, where there may not be huge datasets available for training. By mimicking human language acquisition, these models have the potential to learn new vocabulary just like people do - by connecting what they see to what they hear.
Technical Explanation
The paper introduces two new multimodal deep learning architectures for visually grounded few-shot word learning:
-
DAVEnet (Deep Audio-Visual Embedding Network) - a neural network that learns a joint embedding space for visual and linguistic inputs, allowing it to connect images and words.
-
ResDAVEnet (Residual Deep Audio-Visual Embedding Network) - an extension of DAVEnet that incorporates residual connections to improve learning from limited data.
These models are trained on a dataset of images paired with their corresponding captions in low-resource languages. The key innovation is the use of few-shot learning techniques, where the models can acquire new word-image associations from just a handful of examples, similar to how humans learn language.
The paper evaluates the models on several benchmark tasks, including zero-shot and few-shot word learning, and shows that they outperform previous state-of-the-art approaches, especially in low-resource settings. The results demonstrate the potential of these visually grounded models to enable efficient vocabulary acquisition for AI systems, even when training data is scarce.
Critical Analysis
The paper makes a compelling case for the importance of developing models that can learn new words and their meanings from limited data, similar to how humans acquire language. The proposed architectures, DAVEnet and ResDAVEnet, represent a promising step towards this goal, with strong performance on benchmark tasks.
However, the paper does acknowledge some limitations of the current work. For example, the models are still constrained by the quality and diversity of the training data available, and may struggle to generalize to real-world settings with even greater linguistic and visual diversity. Additionally, the paper does not explore the potential biases or ethical considerations that may arise from these types of visually grounded language models.
Further research is needed to address these challenges and to better understand the broader implications of this approach. Potential future directions could include exploring zero-shot and few-shot learning techniques in more depth, incorporating language models to better leverage linguistic information, or [investigating how these models can be applied to language-informed visual concept learning and referring expression comprehension.
Conclusion
This paper presents a novel approach to enabling visually grounded few-shot word learning in low-resource language settings. By developing multimodal deep learning models that can efficiently acquire new vocabulary from limited data, the researchers have taken an important step towards building AI systems that can learn language more like humans do.
The proposed architectures, DAVEnet and ResDAVEnet, demonstrate promising results on benchmark tasks, and have the potential to significantly impact the development of conversational agents and other language-based AI applications, especially in regions with limited online resources. While further research is needed to address the remaining challenges, this work represents an exciting advancement in the field of multimodal language learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Translating speech with just images
Dan Oneata, Herman Kamper
0
0
Visually grounded speech models link speech to images. We extend this connection by linking images to text via an existing image captioning system, and as a result gain the ability to map speech audio directly to text. This approach can be used for speech translation with just images by having the audio in a different language from the generated captions. We investigate such a system on a real low-resource language, Yor`ub'a, and propose a Yor`ub'a-to-English speech translation model that leverages pretrained components in order to be able to learn in the low-resource regime. To limit overfitting, we find that it is essential to use a decoding scheme that produces diverse image captions for training. Results show that the predicted translations capture the main semantics of the spoken audio, albeit in a simpler and shorter form.
6/12/2024
Few Shot Class Incremental Learning using Vision-Language models
Anurag Kumar, Chinmay Bharti, Saikat Dutta, Srikrishna Karanam, Biplab Banerjee
0
0
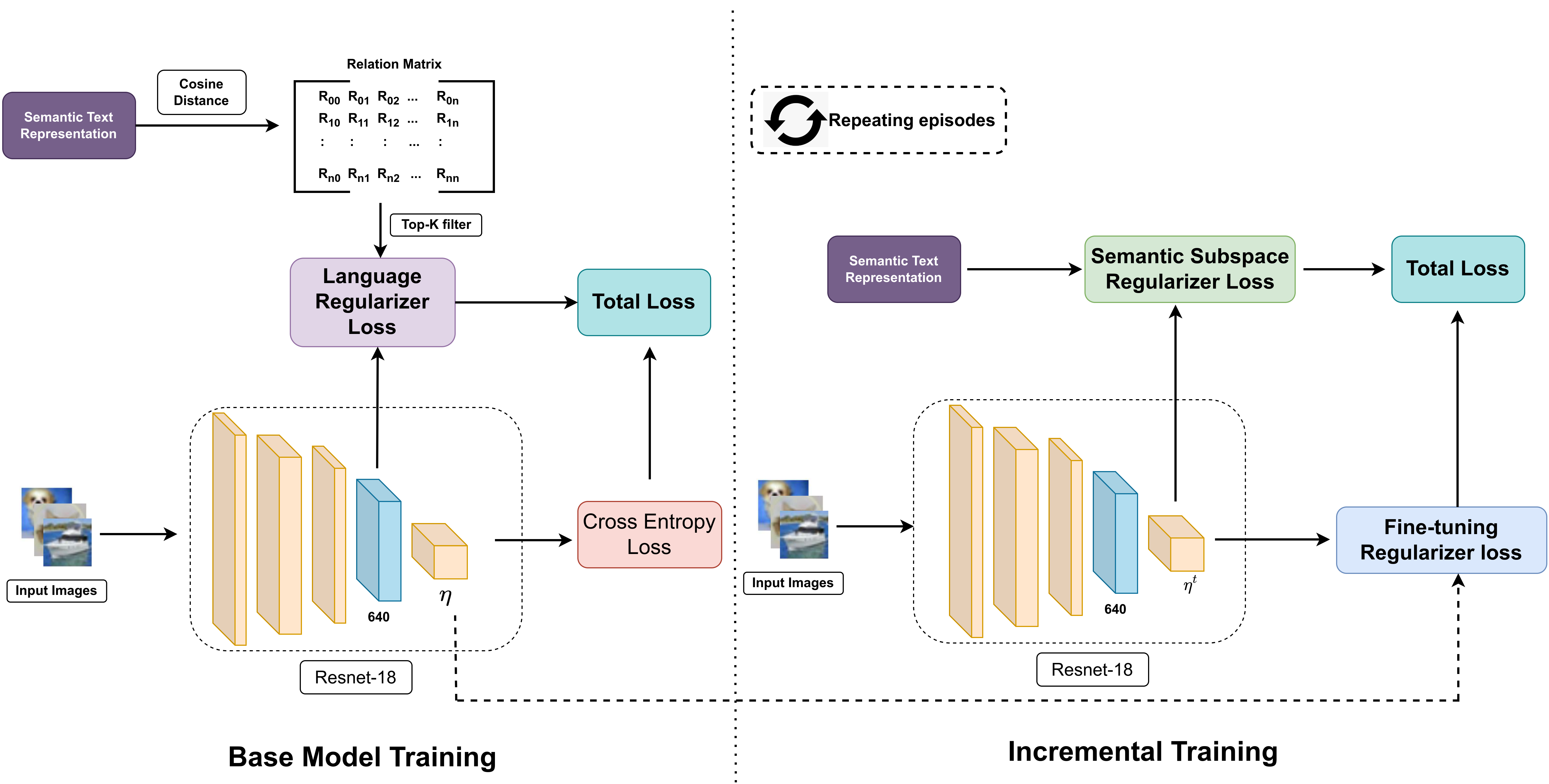
Recent advancements in deep learning have demonstrated remarkable performance comparable to human capabilities across various supervised computer vision tasks. However, the prevalent assumption of having an extensive pool of training data encompassing all classes prior to model training often diverges from real-world scenarios, where limited data availability for novel classes is the norm. The challenge emerges in seamlessly integrating new classes with few samples into the training data, demanding the model to adeptly accommodate these additions without compromising its performance on base classes. To address this exigency, the research community has introduced several solutions under the realm of few-shot class incremental learning (FSCIL). In this study, we introduce an innovative FSCIL framework that utilizes language regularizer and subspace regularizer. During base training, the language regularizer helps incorporate semantic information extracted from a Vision-Language model. The subspace regularizer helps in facilitating the model's acquisition of nuanced connections between image and text semantics inherent to base classes during incremental training. Our proposed framework not only empowers the model to embrace novel classes with limited data, but also ensures the preservation of performance on base classes. To substantiate the efficacy of our approach, we conduct comprehensive experiments on three distinct FSCIL benchmarks, where our framework attains state-of-the-art performance.
5/3/2024
The Devil is in the Few Shots: Iterative Visual Knowledge Completion for Few-shot Learning
Yaohui Li, Qifeng Zhou, Haoxing Chen, Jianbing Zhang, Xinyu Dai, Hao Zhou
0
0
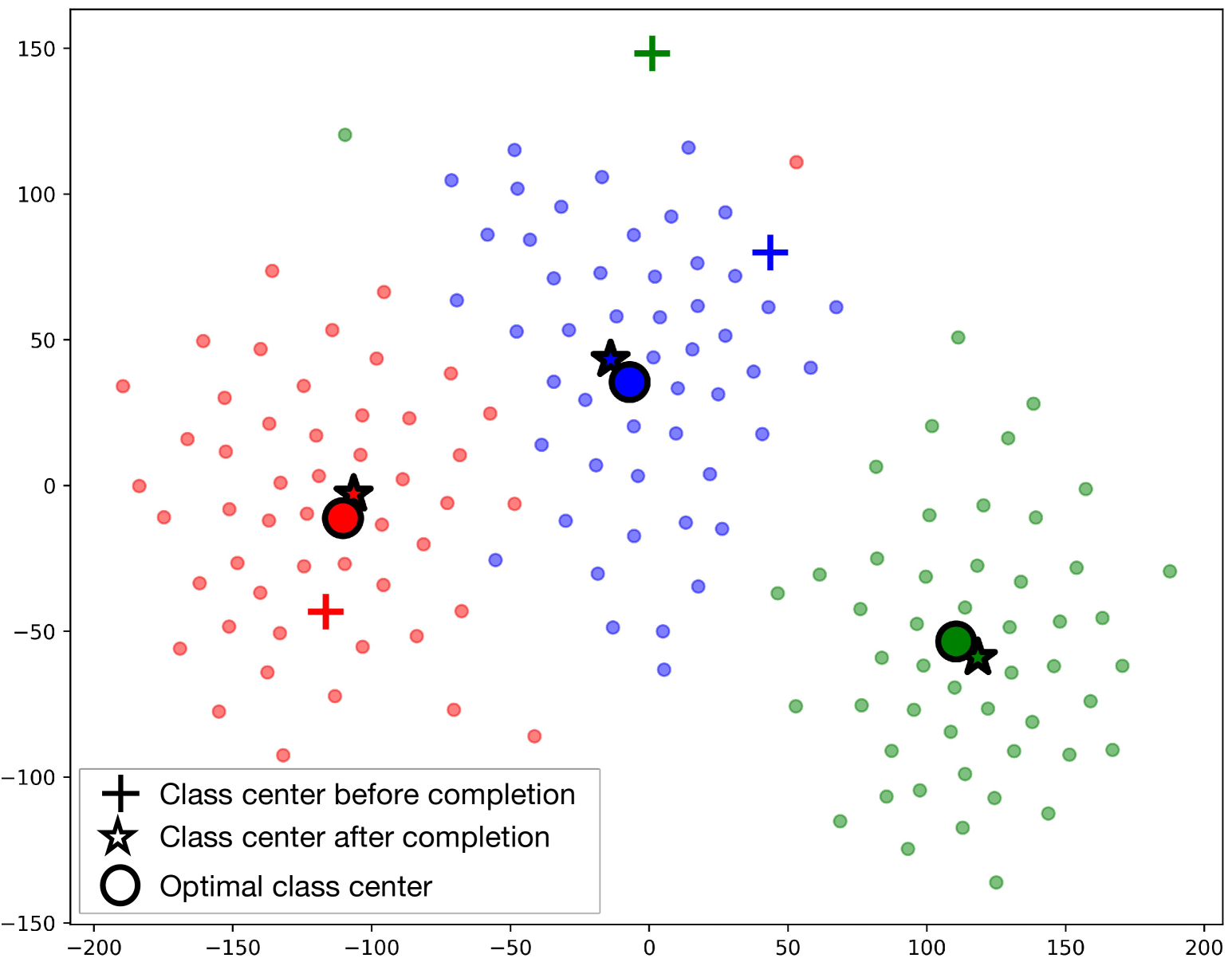
Contrastive Language-Image Pre-training (CLIP) has shown powerful zero-shot learning performance. Few-shot learning aims to further enhance the transfer capability of CLIP by giving few images in each class, aka 'few shots'. Most existing methods either implicitly learn from the few shots by incorporating learnable prompts or adapters, or explicitly embed them in a cache model for inference. However, the narrow distribution of few shots often contains incomplete class information, leading to biased visual knowledge with high risk of misclassification. To tackle this problem, recent methods propose to supplement visual knowledge by generative models or extra databases, which can be costly and time-consuming. In this paper, we propose an Iterative Visual Knowledge CompLetion (KCL) method to complement visual knowledge by properly taking advantages of unlabeled samples without access to any auxiliary or synthetic data. Specifically, KCL first measures the similarities between unlabeled samples and each category. Then, the samples with top confidence to each category is selected and collected by a designed confidence criterion. Finally, the collected samples are treated as labeled ones and added to few shots to jointly re-estimate the remaining unlabeled ones. The above procedures will be repeated for a certain number of iterations with more and more samples being collected until convergence, ensuring a progressive and robust knowledge completion process. Extensive experiments on 11 benchmark datasets demonstrate the effectiveness and efficiency of KCL as a plug-and-play module under both few-shot and zero-shot learning settings. Code is available at https://github.com/Mark-Sky/KCL.
4/22/2024

Low-Rank Few-Shot Adaptation of Vision-Language Models
Maxime Zanella, Ismail Ben Ayed
0
0
Recent progress in the few-shot adaptation of Vision-Language Models (VLMs) has further pushed their generalization capabilities, at the expense of just a few labeled samples within the target downstream task. However, this promising, already quite abundant few-shot literature has focused principally on prompt learning and, to a lesser extent, on adapters, overlooking the recent advances in Parameter-Efficient Fine-Tuning (PEFT). Furthermore, existing few-shot learning methods for VLMs often rely on heavy training procedures and/or carefully chosen, task-specific hyper-parameters, which might impede their applicability. In response, we introduce Low-Rank Adaptation (LoRA) in few-shot learning for VLMs, and show its potential on 11 datasets, in comparison to current state-of-the-art prompt- and adapter-based approaches. Surprisingly, our simple CLIP-LoRA method exhibits substantial improvements, while reducing the training times and keeping the same hyper-parameters in all the target tasks, i.e., across all the datasets and numbers of shots. Certainly, our surprising results do not dismiss the potential of prompt-learning and adapter-based research. However, we believe that our strong baseline could be used to evaluate progress in these emergent subjects in few-shot VLMs.
6/4/2024