Language-Informed Visual Concept Learning
2312.03587
0
0
⛏️
Abstract
Our understanding of the visual world is centered around various concept axes, characterizing different aspects of visual entities. While different concept axes can be easily specified by language, e.g. color, the exact visual nuances along each axis often exceed the limitations of linguistic articulations, e.g. a particular style of painting. In this work, our goal is to learn a language-informed visual concept representation, by simply distilling large pre-trained vision-language models. Specifically, we train a set of concept encoders to encode the information pertinent to a set of language-informed concept axes, with an objective of reproducing the input image through a pre-trained Text-to-Image (T2I) model. To encourage better disentanglement of different concept encoders, we anchor the concept embeddings to a set of text embeddings obtained from a pre-trained Visual Question Answering (VQA) model. At inference time, the model extracts concept embeddings along various axes from new test images, which can be remixed to generate images with novel compositions of visual concepts. With a lightweight test-time finetuning procedure, it can also generalize to novel concepts unseen at training.
Create account to get full access
Overview
- Researchers aim to learn a language-informed visual concept representation by distilling large pre-trained vision-language models.
- They train a set of concept encoders to encode information about language-informed concept axes, with the goal of reproducing input images using a pre-trained Text-to-Image (T2I) model.
- The concept embeddings are anchored to text embeddings from a pre-trained Visual Question Answering (VQA) model to encourage better disentanglement.
- At inference, the model extracts concept embeddings from new test images, which can be remixed to generate images with novel compositions of visual concepts.
- A lightweight test-time finetuning procedure allows the model to generalize to novel concepts unseen during training.
Plain English Explanation
Our understanding of the visual world is shaped by various conceptual frameworks, each capturing a different aspect of visual entities. While we can easily describe these conceptual axes using language, like color, the nuances we perceive often exceed what language can convey, such as the style of a painting.
The researchers in this work aim to create a visual representation that is informed by language. They do this by distilling, or extracting, the relevant information from large pre-trained models that can understand both language and images. Specifically, they train a set of "concept encoders" that can identify and encode the different conceptual aspects of an image, like color, shape, texture, and so on.
These concept encoders are trained to reproduce the original image using a pre-existing text-to-image model. To help the encoders focus on distinct conceptual dimensions, the researchers anchor the concept embeddings to text embeddings from a model trained on visual question answering.
At inference time, the model can extract these conceptual embeddings from new images, and then recombine them in novel ways to generate images with unique compositions of visual concepts. The model can also be quickly fine-tuned to work with new concepts it wasn't trained on originally.
The key idea is to create a flexible visual representation that is grounded in and informed by language, allowing for more nuanced and expressive image generation and manipulation.
Technical Explanation
The core of this research is training a set of "concept encoders" that can identify and encode different conceptual aspects of visual entities, such as color, texture, shape, etc. These concept encoders are trained in a distillation process, where the objective is to reproduce the input image using a pre-trained Text-to-Image (T2I) model.
To encourage the concept encoders to focus on distinct conceptual dimensions, the researchers anchor the concept embeddings to text embeddings obtained from a pre-trained Visual Question Answering (VQA) model. This helps the concept encoders learn to disentangle the different conceptual axes.
At inference time, the trained model can extract the concept embeddings from new test images. These extracted embeddings can then be remixed and fed into the pre-trained T2I model to generate novel images that combine the visual concepts in unique ways.
The researchers also demonstrate that the model can be quickly fine-tuned on novel concepts during test time, allowing it to generalize beyond the original training distribution.
Critical Analysis
The proposed approach offers a flexible and language-informed visual representation that can enable novel image generation and manipulation capabilities. By distilling the knowledge from large pre-trained vision-language models, the researchers are able to create a modular and disentangled representation of visual concepts.
However, the paper does not delve into the potential limitations or failure modes of this approach. For example, it's unclear how well the concept encoders would perform on more complex or abstract visual concepts, or how robust the system would be to distribution shifts or adversarial attacks.
Additionally, the paper does not provide a comprehensive analysis of the generated images, such as their coherence, realism, or fidelity to the intended conceptual composition. Further user studies or perceptual evaluations could help shed light on the practical usefulness and limitations of this approach.
It would also be interesting to see how this language-informed visual representation could be leveraged for other downstream tasks, such as visual reasoning or image editing, beyond just image generation.
Conclusion
This research presents a novel approach to learning a language-informed visual concept representation by distilling knowledge from large pre-trained vision-language models. The resulting system can extract distinct conceptual embeddings from images and recombine them in novel ways to generate unique visual compositions.
While the paper demonstrates the potential of this approach, further research is needed to fully understand its limitations and explore its broader applications. Nonetheless, this work represents an exciting step towards more expressive and flexible visual representations that are grounded in language.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Pre-trained Vision-Language Models Learn Discoverable Visual Concepts
Yuan Zang, Tian Yun, Hao Tan, Trung Bui, Chen Sun
0
0
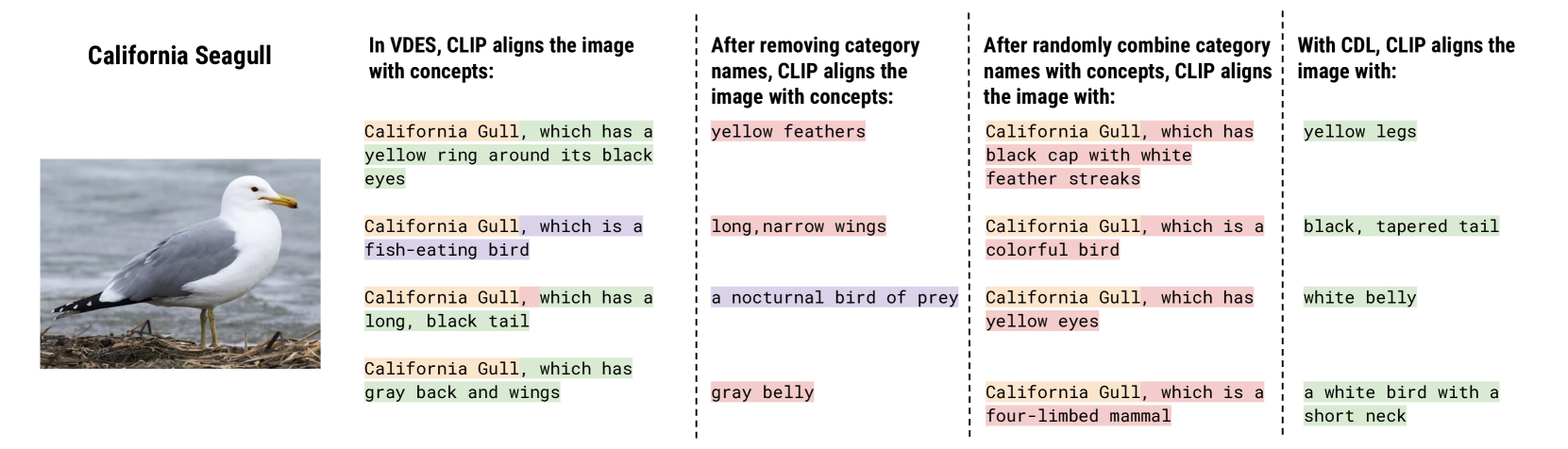
Do vision-language models (VLMs) pre-trained to caption an image of a durian learn visual concepts such as brown (color) and spiky (texture) at the same time? We aim to answer this question as visual concepts learned for free would enable wide applications such as neuro-symbolic reasoning or human-interpretable object classification. We assume that the visual concepts, if captured by pre-trained VLMs, can be extracted by their vision-language interface with text-based concept prompts. We observe that recent works prompting VLMs with concepts often differ in their strategies to define and evaluate the visual concepts, leading to conflicting conclusions. We propose a new concept definition strategy based on two observations: First, certain concept prompts include shortcuts that recognize correct concepts for wrong reasons; Second, multimodal information (e.g. visual discriminativeness, and textual knowledge) should be leveraged when selecting the concepts. Our proposed concept discovery and learning (CDL) framework is thus designed to identify a diverse list of generic visual concepts (e.g. spiky as opposed to spiky durian), which are ranked and selected based on visual and language mutual information. We carefully design quantitative and human evaluations of the discovered concepts on six diverse visual recognition datasets, which confirm that pre-trained VLMs do learn visual concepts that provide accurate and thorough descriptions for the recognized objects. All code and models are publicly released.
4/22/2024
🤔
Probing Conceptual Understanding of Large Visual-Language Models
Madeline Schiappa, Raiyaan Abdullah, Shehreen Azad, Jared Claypoole, Michael Cogswell, Ajay Divakaran, Yogesh Rawat
0
0
In recent years large visual-language (V+L) models have achieved great success in various downstream tasks. However, it is not well studied whether these models have a conceptual grasp of the visual content. In this work we focus on conceptual understanding of these large V+L models. To facilitate this study, we propose novel benchmarking datasets for probing three different aspects of content understanding, 1) textit{relations}, 2) textit{composition}, and 3) textit{context}. Our probes are grounded in cognitive science and help determine if a V+L model can, for example, determine if snow garnished with a man is implausible, or if it can identify beach furniture by knowing it is located on a beach. We experimented with many recent state-of-the-art V+L models and observe that these models mostly textit{fail to demonstrate} a conceptual understanding. This study reveals several interesting insights such as that textit{cross-attention} helps learning conceptual understanding, and that CNNs are better with textit{texture and patterns}, while Transformers are better at textit{color and shape}. We further utilize some of these insights and investigate a textit{simple finetuning technique} that rewards the three conceptual understanding measures with promising initial results. The proposed benchmarks will drive the community to delve deeper into conceptual understanding and foster advancements in the capabilities of large V+L models. The code and dataset is available at: url{https://tinyurl.com/vlm-robustness}
4/29/2024

Understanding Visual Concepts Across Models
Brandon Trabucco, Max Gurinas, Kyle Doherty, Ruslan Salakhutdinov
0
0
Large multimodal models such as Stable Diffusion can generate, detect, and classify new visual concepts after fine-tuning just a single word embedding. Do models learn similar words for the same concepts (i.e. = orange + cat)? We conduct a large-scale analysis on three state-of-the-art models in text-to-image generation, open-set object detection, and zero-shot classification, and find that new word embeddings are model-specific and non-transferable. Across 4,800 new embeddings trained for 40 diverse visual concepts on four standard datasets, we find perturbations within an $epsilon$-ball to any prior embedding that generate, detect, and classify an arbitrary concept. When these new embeddings are spliced into new models, fine-tuning that targets the original model is lost. We show popular soft prompt-tuning approaches find these perturbative solutions when applied to visual concept learning tasks, and embeddings for visual concepts are not transferable. Code for reproducing our work is available at: https://visual-words.github.io.
6/12/2024
Concept-based Analysis of Neural Networks via Vision-Language Models
Ravi Mangal, Nina Narodytska, Divya Gopinath, Boyue Caroline Hu, Anirban Roy, Susmit Jha, Corina Pasareanu
0
0
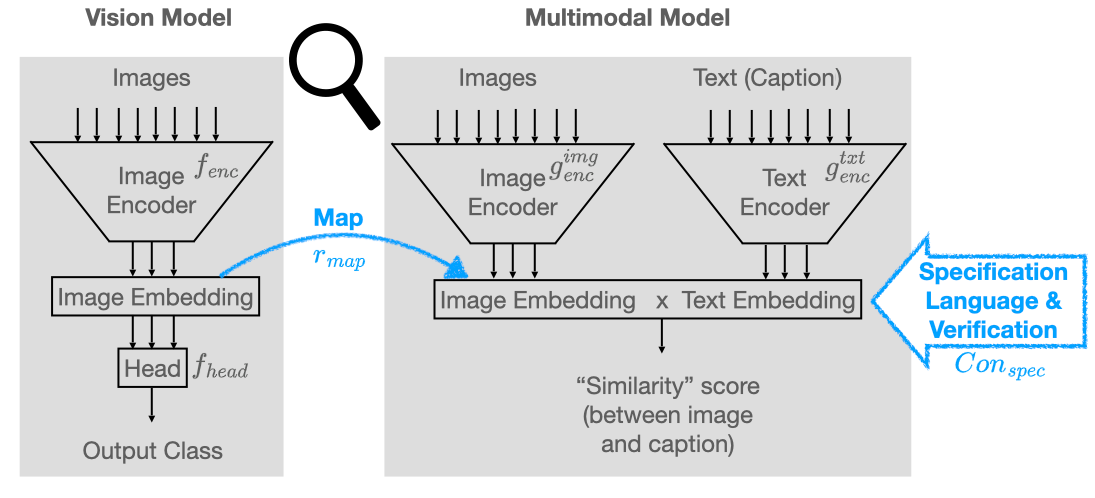
The analysis of vision-based deep neural networks (DNNs) is highly desirable but it is very challenging due to the difficulty of expressing formal specifications for vision tasks and the lack of efficient verification procedures. In this paper, we propose to leverage emerging multimodal, vision-language, foundation models (VLMs) as a lens through which we can reason about vision models. VLMs have been trained on a large body of images accompanied by their textual description, and are thus implicitly aware of high-level, human-understandable concepts describing the images. We describe a logical specification language $texttt{Con}_{texttt{spec}}$ designed to facilitate writing specifications in terms of these concepts. To define and formally check $texttt{Con}_{texttt{spec}}$ specifications, we build a map between the internal representations of a given vision model and a VLM, leading to an efficient verification procedure of natural-language properties for vision models. We demonstrate our techniques on a ResNet-based classifier trained on the RIVAL-10 dataset using CLIP as the multimodal model.
4/12/2024