vMFER: Von Mises-Fisher Experience Resampling Based on Uncertainty of Gradient Directions for Policy Improvement
2405.08638
0
0
Abstract
Reinforcement Learning (RL) is a widely employed technique in decision-making problems, encompassing two fundamental operations -- policy evaluation and policy improvement. Enhancing learning efficiency remains a key challenge in RL, with many efforts focused on using ensemble critics to boost policy evaluation efficiency. However, when using multiple critics, the actor in the policy improvement process can obtain different gradients. Previous studies have combined these gradients without considering their disagreements. Therefore, optimizing the policy improvement process is crucial to enhance learning efficiency. This study focuses on investigating the impact of gradient disagreements caused by ensemble critics on policy improvement. We introduce the concept of uncertainty of gradient directions as a means to measure the disagreement among gradients utilized in the policy improvement process. Through measuring the disagreement among gradients, we find that transitions with lower uncertainty of gradient directions are more reliable in the policy improvement process. Building on this analysis, we propose a method called von Mises-Fisher Experience Resampling (vMFER), which optimizes the policy improvement process by resampling transitions and assigning higher confidence to transitions with lower uncertainty of gradient directions. Our experiments demonstrate that vMFER significantly outperforms the benchmark and is particularly well-suited for ensemble structures in RL.
Create account to get full access
Overview
- This paper introduces a new experience resampling method called vMFER (Von Mises-Fisher Experience Resampling) for improving reinforcement learning policy optimization.
- vMFER resamples experiences based on the uncertainty of the gradient directions, aiming to improve sample efficiency and robustness.
- The method is evaluated on various reinforcement learning tasks and shows promising results compared to existing experience replay techniques.
Plain English Explanation
In the field of reinforcement learning, agents learn by interacting with an environment and collecting experiences (observations, actions, rewards) over time. These experiences are often stored in a replay buffer and sampled during training to update the agent's policy.
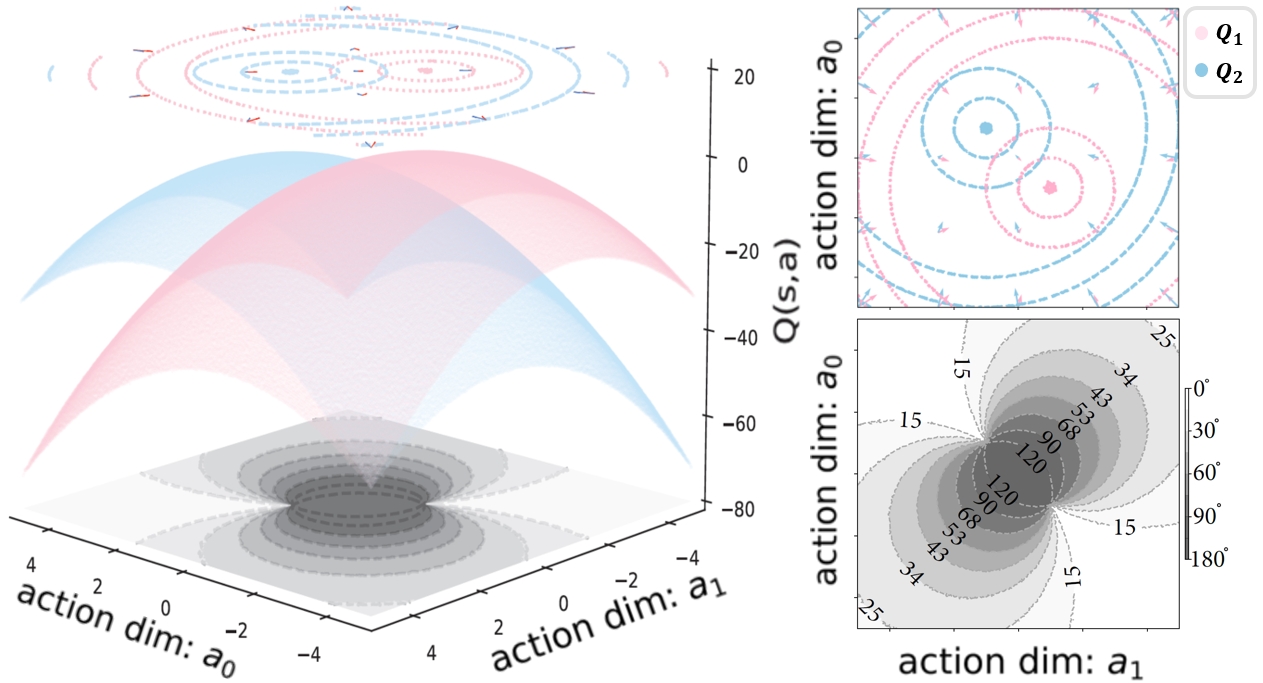
The key idea behind vMFER is to resample experiences based on the uncertainty of the gradient directions. Gradients are the directions in which the policy should be updated to improve performance. By focusing on experiences that have high gradient uncertainty, the method aims to efficiently explore the environment and learn a more robust and stable policy.
This approach differs from traditional experience replay, which often samples experiences uniformly or based on their importance. vMFER leverages the uncertainty of the gradient directions to guide the experience replay, potentially leading to faster learning and better generalization.
Technical Explanation
The paper first provides background on reinforcement learning and the use of experience replay for policy optimization. It then introduces the vMFER method, which models the gradient directions using a Von Mises-Fisher (vMF) distribution and resamples experiences based on the uncertainty of this distribution.
The key steps of the vMFER algorithm are:
- Compute the gradients of the policy with respect to each experience in the replay buffer.
- Fit a vMF distribution to the gradient directions.
- Sample new experiences from the vMF distribution, prioritizing those with higher uncertainty (i.e., lower concentration parameter).
- Use the sampled experiences to update the policy.
The authors evaluate vMFER on a variety of reinforcement learning tasks, including multi-agent settings, distributional robustness, and privacy-constrained settings. The results demonstrate that vMFER can improve sample efficiency and robustness compared to standard experience replay techniques.
Critical Analysis
The paper provides a well-designed and thorough evaluation of the vMFER method, including comparisons to various baselines and analysis of the method's properties. However, the authors acknowledge some limitations:
- The performance of vMFER may depend on the accuracy of the vMF distribution fit to the gradient directions, which could be challenging in high-dimensional or complex environments.
- The method assumes that the gradient directions are meaningful for guiding the experience replay, which may not always be the case, especially in risk-sensitive settings.
Additionally, it would be interesting to see further research on the theoretical properties of vMFER, such as its convergence guarantees and sample complexity analysis. Exploring the method's performance on a wider range of tasks and environments would also help establish its broader applicability.
Conclusion
The vMFER method presented in this paper offers a novel approach to experience replay for reinforcement learning policy optimization. By resampling experiences based on the uncertainty of gradient directions, the method aims to improve sample efficiency and robustness. The promising results on various tasks suggest that vMFER could be a valuable tool for developing more effective and reliable reinforcement learning agents.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
➖
Variance Reduction based Experience Replay for Policy Optimization
Hua Zheng, Wei Xie, M. Ben Feng
0
0
For reinforcement learning on complex stochastic systems, it is desirable to effectively leverage the information from historical samples collected in previous iterations to accelerate policy optimization. Classical experience replay, while effective, treats all observations uniformly, neglecting their relative importance. To address this limitation, we introduce a novel Variance Reduction Experience Replay (VRER) framework, enabling the selective reuse of relevant samples to improve policy gradient estimation. VRER, as an adaptable method that can seamlessly integrate with different policy optimization algorithms, forms the foundation of our sample efficient off-policy learning algorithm known as Policy Gradient with VRER (PG-VRER). Furthermore, the lack of a rigorous understanding of the experience replay approach in the literature motivates us to introduce a novel theoretical framework that accounts for sample dependencies induced by Markovian noise and behavior policy interdependencies. This framework is then employed to analyze the finite-time convergence of the proposed PG-VRER algorithm, revealing a crucial bias-variance trade-off in policy gradient estimation: the reuse of older experience tends to introduce a larger bias while simultaneously reducing gradient estimation variance. Extensive experiments have shown that VRER offers a notable and consistent acceleration in learning optimal policies and enhances the performance of state-of-the-art (SOTA) policy optimization approaches.
4/16/2024
Sample-Efficient Robust Multi-Agent Reinforcement Learning in the Face of Environmental Uncertainty
Laixi Shi, Eric Mazumdar, Yuejie Chi, Adam Wierman
0
0
To overcome the sim-to-real gap in reinforcement learning (RL), learned policies must maintain robustness against environmental uncertainties. While robust RL has been widely studied in single-agent regimes, in multi-agent environments, the problem remains understudied -- despite the fact that the problems posed by environmental uncertainties are often exacerbated by strategic interactions. This work focuses on learning in distributionally robust Markov games (RMGs), a robust variant of standard Markov games, wherein each agent aims to learn a policy that maximizes its own worst-case performance when the deployed environment deviates within its own prescribed uncertainty set. This results in a set of robust equilibrium strategies for all agents that align with classic notions of game-theoretic equilibria. Assuming a non-adaptive sampling mechanism from a generative model, we propose a sample-efficient model-based algorithm (DRNVI) with finite-sample complexity guarantees for learning robust variants of various notions of game-theoretic equilibria. We also establish an information-theoretic lower bound for solving RMGs, which confirms the near-optimal sample complexity of DRNVI with respect to problem-dependent factors such as the size of the state space, the target accuracy, and the horizon length.
5/10/2024

Diffusion Actor-Critic with Entropy Regulator
Yinuo Wang, Likun Wang, Yuxuan Jiang, Wenjun Zou, Tong Liu, Xujie Song, Wenxuan Wang, Liming Xiao, Jiang Wu, Jingliang Duan, Shengbo Eben Li
0
0
Reinforcement learning (RL) has proven highly effective in addressing complex decision-making and control tasks. However, in most traditional RL algorithms, the policy is typically parameterized as a diagonal Gaussian distribution with learned mean and variance, which constrains their capability to acquire complex policies. In response to this problem, we propose an online RL algorithm termed diffusion actor-critic with entropy regulator (DACER). This algorithm conceptualizes the reverse process of the diffusion model as a novel policy function and leverages the capability of the diffusion model to fit multimodal distributions, thereby enhancing the representational capacity of the policy. Since the distribution of the diffusion policy lacks an analytical expression, its entropy cannot be determined analytically. To mitigate this, we propose a method to estimate the entropy of the diffusion policy utilizing Gaussian mixture model. Building on the estimated entropy, we can learn a parameter $alpha$ that modulates the degree of exploration and exploitation. Parameter $alpha$ will be employed to adaptively regulate the variance of the added noise, which is applied to the action output by the diffusion model. Experimental trials on MuJoCo benchmarks and a multimodal task demonstrate that the DACER algorithm achieves state-of-the-art (SOTA) performance in most MuJoCo control tasks while exhibiting a stronger representational capacity of the diffusion policy.
6/18/2024
🔗
Adaptive Horizon Actor-Critic for Policy Learning in Contact-Rich Differentiable Simulation
Ignat Georgiev, Krishnan Srinivasan, Jie Xu, Eric Heiden, Animesh Garg
0
0
Model-Free Reinforcement Learning (MFRL), leveraging the policy gradient theorem, has demonstrated considerable success in continuous control tasks. However, these approaches are plagued by high gradient variance due to zeroth-order gradient estimation, resulting in suboptimal policies. Conversely, First-Order Model-Based Reinforcement Learning (FO-MBRL) methods employing differentiable simulation provide gradients with reduced variance but are susceptible to sampling error in scenarios involving stiff dynamics, such as physical contact. This paper investigates the source of this error and introduces Adaptive Horizon Actor-Critic (AHAC), an FO-MBRL algorithm that reduces gradient error by adapting the model-based horizon to avoid stiff dynamics. Empirical findings reveal that AHAC outperforms MFRL baselines, attaining 40% more reward across a set of locomotion tasks and efficiently scaling to high-dimensional control environments with improved wall-clock-time efficiency.
6/5/2024