Robust Risk-Sensitive Reinforcement Learning with Conditional Value-at-Risk
2405.01718
0
0
Abstract
Robust Markov Decision Processes (RMDPs) have received significant research interest, offering an alternative to standard Markov Decision Processes (MDPs) that often assume fixed transition probabilities. RMDPs address this by optimizing for the worst-case scenarios within ambiguity sets. While earlier studies on RMDPs have largely centered on risk-neutral reinforcement learning (RL), with the goal of minimizing expected total discounted costs, in this paper, we analyze the robustness of CVaR-based risk-sensitive RL under RMDP. Firstly, we consider predetermined ambiguity sets. Based on the coherency of CVaR, we establish a connection between robustness and risk sensitivity, thus, techniques in risk-sensitive RL can be adopted to solve the proposed problem. Furthermore, motivated by the existence of decision-dependent uncertainty in real-world problems, we study problems with state-action-dependent ambiguity sets. To solve this, we define a new risk measure named NCVaR and build the equivalence of NCVaR optimization and robust CVaR optimization. We further propose value iteration algorithms and validate our approach in simulation experiments.
Create account to get full access
Overview
- This paper proposes a novel approach to risk-sensitive reinforcement learning (RL) using Conditional Value-at-Risk (CVaR) as the risk measure.
- The authors introduce a robust Markov Decision Process (RMDP) framework that allows for the modeling of ambiguity sets around the true reward and transition dynamics.
- The proposed method aims to find policies that are robust to this ambiguity and optimize the CVaR of the cumulative rewards.
- The paper provides theoretical guarantees and empirical results demonstrating the effectiveness of the approach on several benchmark tasks.
Plain English Explanation
In the field of reinforcement learning (RL), agents are trained to make decisions that maximize the long-term rewards they receive. However, in many real-world scenarios, there is uncertainty about the true underlying dynamics of the environment, which can make it challenging to find optimal policies.
This paper addresses this challenge by proposing a new approach to risk-sensitive RL using a measure called Conditional Value-at-Risk (CVaR). The key idea is to model the uncertainty in the environment as "ambiguity sets" - regions around the true reward and transition dynamics within which the real values may lie. The goal is then to find policies that are robust to this ambiguity and optimize the CVaR, which captures the expected value of the worst [link to "http://aimodels.fyi/papers/arxiv/curious-price-distributional-robustness-reinforcement-learning-generative"]100(1-α)%[/link] of outcomes.
By incorporating this robust and risk-sensitive perspective, the method aims to find policies that perform well even in the face of uncertainty, rather than policies that maximize the average expected reward but may be vulnerable to rare but catastrophic events. This can be particularly valuable in domains where the consequences of poor decisions can be severe, such as autonomous driving, healthcare, or financial applications.
Technical Explanation
The authors introduce a Robust Markov Decision Process (RMDP) framework to model the ambiguity in the reward and transition dynamics. In this framework, the true reward and transition functions are assumed to lie within predefined ambiguity sets, which can be constructed based on domain knowledge or historical data.
The authors then propose a risk-sensitive RL algorithm that seeks to optimize the Conditional Value-at-Risk (CVaR) of the cumulative rewards, which captures the expected value of the worst [link to "https://aimodels.fyi/papers/arxiv/sample-efficient-robust-multi-agent-reinforcement-learning"]100(1-α)%[/link] of outcomes. This is in contrast to traditional RL approaches that focus on maximizing the expected reward.
The paper provides theoretical guarantees, showing that the proposed algorithm converges to an optimal policy for the RMDP problem. The authors also present empirical results on several benchmark tasks, demonstrating the effectiveness of the method in finding policies that are robust to ambiguity and optimizing the CVaR objective.
Critical Analysis
The paper makes a valuable contribution to the field of risk-sensitive RL by introducing a principled framework for modeling and optimizing the CVaR of cumulative rewards in the presence of ambiguity. The authors' use of the RMDP model to capture the uncertainty in the environment is a well-founded approach, and the theoretical guarantees provide assurance about the algorithm's convergence properties.
That said, the paper does not delve into the potential limitations or caveats of the proposed method. For example, the construction of the ambiguity sets may be challenging in practice, and the method's performance may be sensitive to the choice of parameters, such as the level of risk aversion (α). Additionally, the paper does not explore the computational complexity of the algorithm or discuss its scalability to larger, more complex environments.
[link to "https://aimodels.fyi/papers/arxiv/distributionally-robust-reinforcement-learning-interactive-data-collection"]Furthermore, the paper does not compare the proposed approach to other risk-sensitive RL methods, such as those based on Markov Decision Processes with Coherent Risk Measures[/link] or [link to "https://aimodels.fyi/papers/arxiv/dynamic-programming-decompositions-static-risk-measures-markov"]Robust Dynamic Programming with Static Risk Measures[/link]. A more comprehensive comparison could help situate the contribution of this work within the broader context of risk-sensitive RL research.
Conclusion
This paper presents a novel approach to risk-sensitive reinforcement learning that leverages the Conditional Value-at-Risk (CVaR) as the risk measure and a Robust Markov Decision Process (RMDP) framework to model ambiguity in the environment. The proposed algorithm aims to find policies that are robust to this ambiguity and optimize the CVaR of the cumulative rewards.
The theoretical guarantees and empirical results provided in the paper demonstrate the effectiveness of the method, making it a valuable contribution to the field of RL. The approach could have significant practical implications in domains where the consequences of poor decisions can be severe, as it allows for the identification of policies that balance expected performance with risk mitigation.
While the paper does not address all potential limitations of the method, it lays the groundwork for further research in this area, such as exploring alternative ambiguity set constructions, improving the algorithm's scalability, and comparing the approach to other risk-sensitive RL techniques. Overall, this work represents an important step forward in the development of robust and risk-aware reinforcement learning systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏅
The Curious Price of Distributional Robustness in Reinforcement Learning with a Generative Model
Laixi Shi, Gen Li, Yuting Wei, Yuxin Chen, Matthieu Geist, Yuejie Chi
0
0
This paper investigates model robustness in reinforcement learning (RL) to reduce the sim-to-real gap in practice. We adopt the framework of distributionally robust Markov decision processes (RMDPs), aimed at learning a policy that optimizes the worst-case performance when the deployed environment falls within a prescribed uncertainty set around the nominal MDP. Despite recent efforts, the sample complexity of RMDPs remained mostly unsettled regardless of the uncertainty set in use. It was unclear if distributional robustness bears any statistical consequences when benchmarked against standard RL. Assuming access to a generative model that draws samples based on the nominal MDP, we characterize the sample complexity of RMDPs when the uncertainty set is specified via either the total variation (TV) distance or $chi^2$ divergence. The algorithm studied here is a model-based method called {em distributionally robust value iteration}, which is shown to be near-optimal for the full range of uncertainty levels. Somewhat surprisingly, our results uncover that RMDPs are not necessarily easier or harder to learn than standard MDPs. The statistical consequence incurred by the robustness requirement depends heavily on the size and shape of the uncertainty set: in the case w.r.t.~the TV distance, the minimax sample complexity of RMDPs is always smaller than that of standard MDPs; in the case w.r.t.~the $chi^2$ divergence, the sample complexity of RMDPs can often far exceed the standard MDP counterpart.
4/15/2024

Simplification of Risk Averse POMDPs with Performance Guarantees
Yaacov Pariente, Vadim Indelman
0
0
Risk averse decision making under uncertainty in partially observable domains is a fundamental problem in AI and essential for reliable autonomous agents. In our case, the problem is modeled using partially observable Markov decision processes (POMDPs), when the value function is the conditional value at risk (CVaR) of the return. Calculating an optimal solution for POMDPs is computationally intractable in general. In this work we develop a simplification framework to speedup the evaluation of the value function, while providing performance guarantees. We consider as simplification a computationally cheaper belief-MDP transition model, that can correspond, e.g., to cheaper observation or transition models. Our contributions include general bounds for CVaR that allow bounding the CVaR of a random variable X, using a random variable Y, by assuming bounds between their cumulative distributions. We then derive bounds for the CVaR value function in a POMDP setting, and show how to bound the value function using the computationally cheaper belief-MDP transition model and without accessing the computationally expensive model in real-time. Then, we provide theoretical performance guarantees for the estimated bounds. Our results apply for a general simplification of a belief-MDP transition model and support simplification of both the observation and state transition models simultaneously.
6/11/2024
➖
Robust Lagrangian and Adversarial Policy Gradient for Robust Constrained Markov Decision Processes
David M. Bossens
0
0
The robust constrained Markov decision process (RCMDP) is a recent task-modelling framework for reinforcement learning that incorporates behavioural constraints and that provides robustness to errors in the transition dynamics model through the use of an uncertainty set. Simulating RCMDPs requires computing the worst-case dynamics based on value estimates for each state, an approach which has previously been used in the Robust Constrained Policy Gradient (RCPG). Highlighting potential downsides of RCPG such as not robustifying the full constrained objective and the lack of incremental learning, this paper introduces two algorithms, called RCPG with Robust Lagrangian and Adversarial RCPG. RCPG with Robust Lagrangian modifies RCPG by taking the worst-case dynamics based on the Lagrangian rather than either the value or the constraint. Adversarial RCPG also formulates the worst-case dynamics based on the Lagrangian but learns this directly and incrementally as an adversarial policy through gradient descent rather than indirectly and abruptly through constrained optimisation on a sorted value list. A theoretical analysis first derives the Lagrangian policy gradient for the policy optimisation of both proposed algorithms and then the adversarial policy gradient to learn the adversary for Adversarial RCPG. Empirical experiments injecting perturbations in inventory management and safe navigation tasks demonstrate the competitive performance of both algorithms compared to traditional RCPG variants as well as non-robust and non-constrained ablations. In particular, Adversarial RCPG ranks among the top two performing algorithms on all tests.
5/16/2024
Robust Model-Based Reinforcement Learning with an Adversarial Auxiliary Model
Siemen Herremans, Ali Anwar, Siegfried Mercelis
0
0
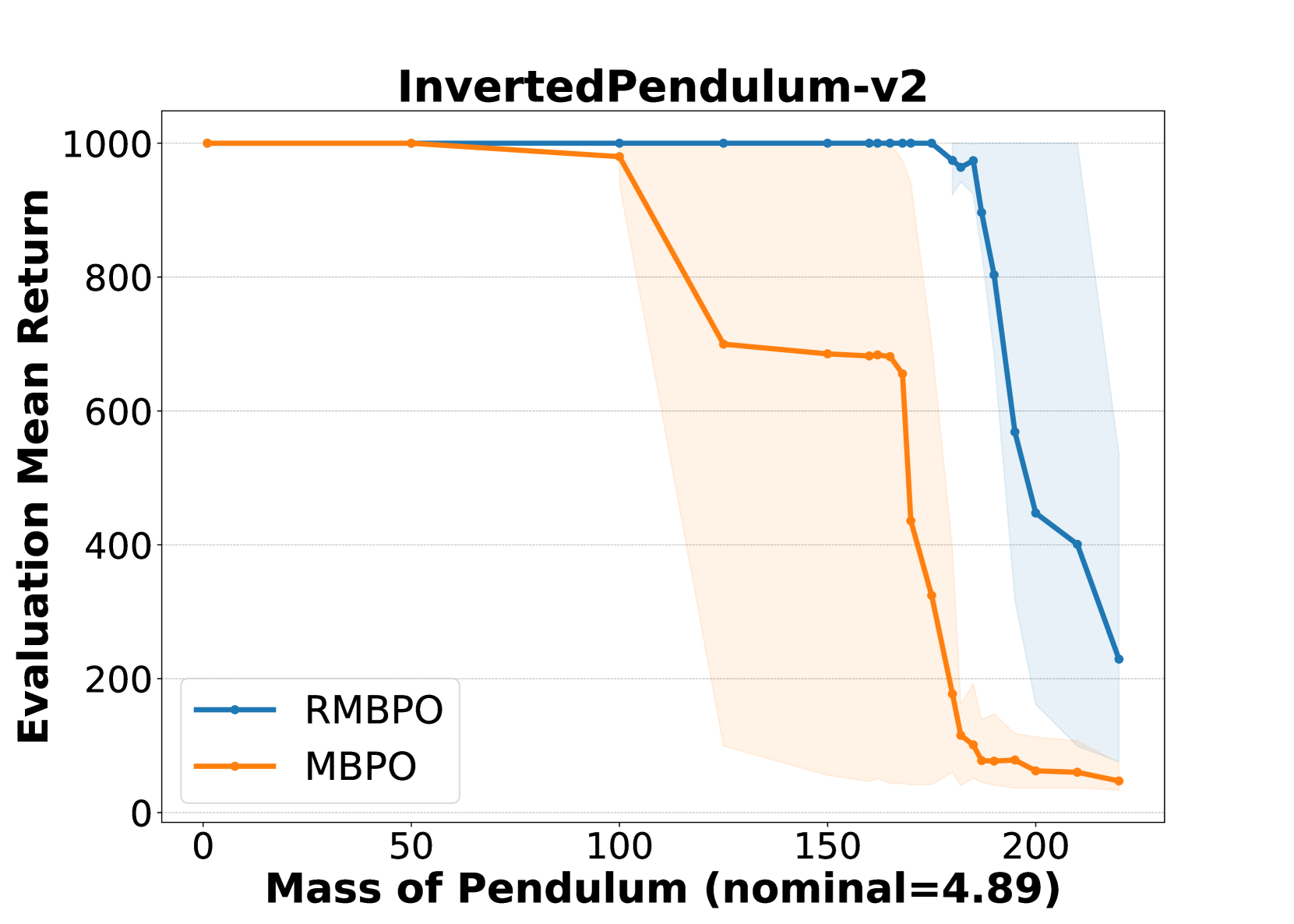
Reinforcement learning has demonstrated impressive performance in various challenging problems such as robotics, board games, and classical arcade games. However, its real-world applications can be hindered by the absence of robustness and safety in the learned policies. More specifically, an RL agent that trains in a certain Markov decision process (MDP) often struggles to perform well in nearly identical MDPs. To address this issue, we employ the framework of Robust MDPs (RMDPs) in a model-based setting and introduce a novel learned transition model. Our method specifically incorporates an auxiliary pessimistic model, updated adversarially, to estimate the worst-case MDP within a Kullback-Leibler uncertainty set. In comparison to several existing works, our work does not impose any additional conditions on the training environment, such as the need for a parametric simulator. To test the effectiveness of the proposed pessimistic model in enhancing policy robustness, we integrate it into a practical RL algorithm, called Robust Model-Based Policy Optimization (RMBPO). Our experimental results indicate a notable improvement in policy robustness on high-dimensional MuJoCo control tasks, with the auxiliary model enhancing the performance of the learned policy in distorted MDPs. We further explore the learned deviation between the proposed auxiliary world model and the nominal model, to examine how pessimism is achieved. By learning a pessimistic world model and demonstrating its role in improving policy robustness, our research contributes towards making (model-based) RL more robust.
6/17/2024