VoiceTailor: Lightweight Plug-In Adapter for Diffusion-Based Personalized Text-to-Speech

0

Sign in to get full access
Overview
- VoiceTailor is a lightweight plug-in adapter for diffusion-based personalized text-to-speech (TTS) systems.
- It aims to enable efficient, personalized TTS without the need for full model fine-tuning.
- The proposed approach leverages parameter-efficient tuning techniques to adapt a pre-trained TTS model to a target speaker.
Plain English Explanation
VoiceTailor is a new way to customize text-to-speech (TTS) systems to sound like a specific person's voice. Typically, to get a TTS system to sound like a particular person, you'd need to fully retrain or fine-tune the entire TTS model on data from that person. This can be time-consuming and computationally intensive.
VoiceTailor takes a different approach. Instead of retraining the whole TTS model, it uses a lightweight "plug-in" adapter that can be easily added to an existing TTS system to adapt it to a new speaker. This adapter is trained on a small amount of data from the target speaker, allowing the TTS system to generate audio that sounds like that person's voice, without having to fully retrain the entire TTS model.
This makes the personalization process much more efficient and practical, as it requires far less computational power and training data compared to full model fine-tuning. The authors demonstrate that VoiceTailor can achieve high-quality personalized TTS while being lightweight and easy to integrate into existing TTS pipelines.
Technical Explanation
The key idea behind VoiceTailor is to leverage parameter-efficient tuning techniques to adapt a pre-trained TTS model to a target speaker, rather than retraining the entire model from scratch.
The VoiceTailor architecture consists of a base TTS model and a lightweight plug-in adapter. The base model is a pre-trained diffusion-based TTS system, while the adapter is a small neural network that is trained on a limited amount of data from the target speaker.
During the adaptation process, the base TTS model's parameters remain frozen, and only the adapter's parameters are updated. This ensures that the core TTS capabilities are preserved, while allowing the system to generate audio that matches the target speaker's voice.
The authors evaluate VoiceTailor on multiple datasets and compare its performance to full model fine-tuning and other parameter-efficient approaches. The results show that VoiceTailor can achieve high-quality personalized TTS while being significantly more efficient in terms of training time and computational resources.
Critical Analysis
The VoiceTailor paper presents a promising approach for efficient, personalized TTS. The key strength of the method is its ability to adapt a pre-trained TTS model to a new speaker without the need for full model fine-tuning, which can be computationally expensive and time-consuming.
However, the paper does not fully address the potential limitations of the approach. For example, it is unclear how well VoiceTailor would perform with limited target speaker data, or how it would scale to larger and more diverse speaker populations. Additionally, the paper does not discuss the potential privacy and ethical concerns associated with using a person's voice data to adapt a TTS model.
Further research is needed to explore the robustness and scalability of the VoiceTailor approach, as well as to address any potential ethical considerations around the use of personalized TTS systems.
Conclusion
VoiceTailor presents a novel and efficient approach for enabling personalized text-to-speech, which could have significant implications for a wide range of applications, from assistive technology to creative audio production. By leveraging parameter-efficient tuning techniques, the method allows for high-quality speaker adaptation without the need for computationally intensive full model fine-tuning.
While the paper demonstrates promising results, further research is needed to fully understand the capabilities and limitations of the VoiceTailor approach. Nonetheless, this work represents an important step forward in the development of flexible and efficient personalized TTS systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
VoiceTailor: Lightweight Plug-In Adapter for Diffusion-Based Personalized Text-to-Speech
Heeseung Kim, Sang-gil Lee, Jiheum Yeom, Che Hyun Lee, Sungwon Kim, Sungroh Yoon
We propose VoiceTailor, a parameter-efficient speaker-adaptive text-to-speech (TTS) system, by equipping a pre-trained diffusion-based TTS model with a personalized adapter. VoiceTailor identifies pivotal modules that benefit from the adapter based on a weight change ratio analysis. We utilize Low-Rank Adaptation (LoRA) as a parameter-efficient adaptation method and incorporate the adapter into pivotal modules of the pre-trained diffusion decoder. To achieve powerful adaptation performance with few parameters, we explore various guidance techniques for speaker adaptation and investigate the best strategies to strengthen speaker information. VoiceTailor demonstrates comparable speaker adaptation performance to existing adaptive TTS models by fine-tuning only 0.25% of the total parameters. VoiceTailor shows strong robustness when adapting to a wide range of real-world speakers, as shown in the demo.
Read more8/29/2024

0
Lightweight Zero-shot Text-to-Speech with Mixture of Adapters
Kenichi Fujita, Takanori Ashihara, Marc Delcroix, Yusuke Ijima
The advancements in zero-shot text-to-speech (TTS) methods, based on large-scale models, have demonstrated high fidelity in reproducing speaker characteristics. However, these models are too large for practical daily use. We propose a lightweight zero-shot TTS method using a mixture of adapters (MoA). Our proposed method incorporates MoA modules into the decoder and the variance adapter of a non-autoregressive TTS model. These modules enhance the ability to adapt a wide variety of speakers in a zero-shot manner by selecting appropriate adapters associated with speaker characteristics on the basis of speaker embeddings. Our method achieves high-quality speech synthesis with minimal additional parameters. Through objective and subjective evaluations, we confirmed that our method achieves better performance than the baseline with less than 40% of parameters at 1.9 times faster inference speed. Audio samples are available on our demo page (https://ntt-hilab-gensp.github.io/is2024lightweightTTS/).
Read more7/2/2024
0
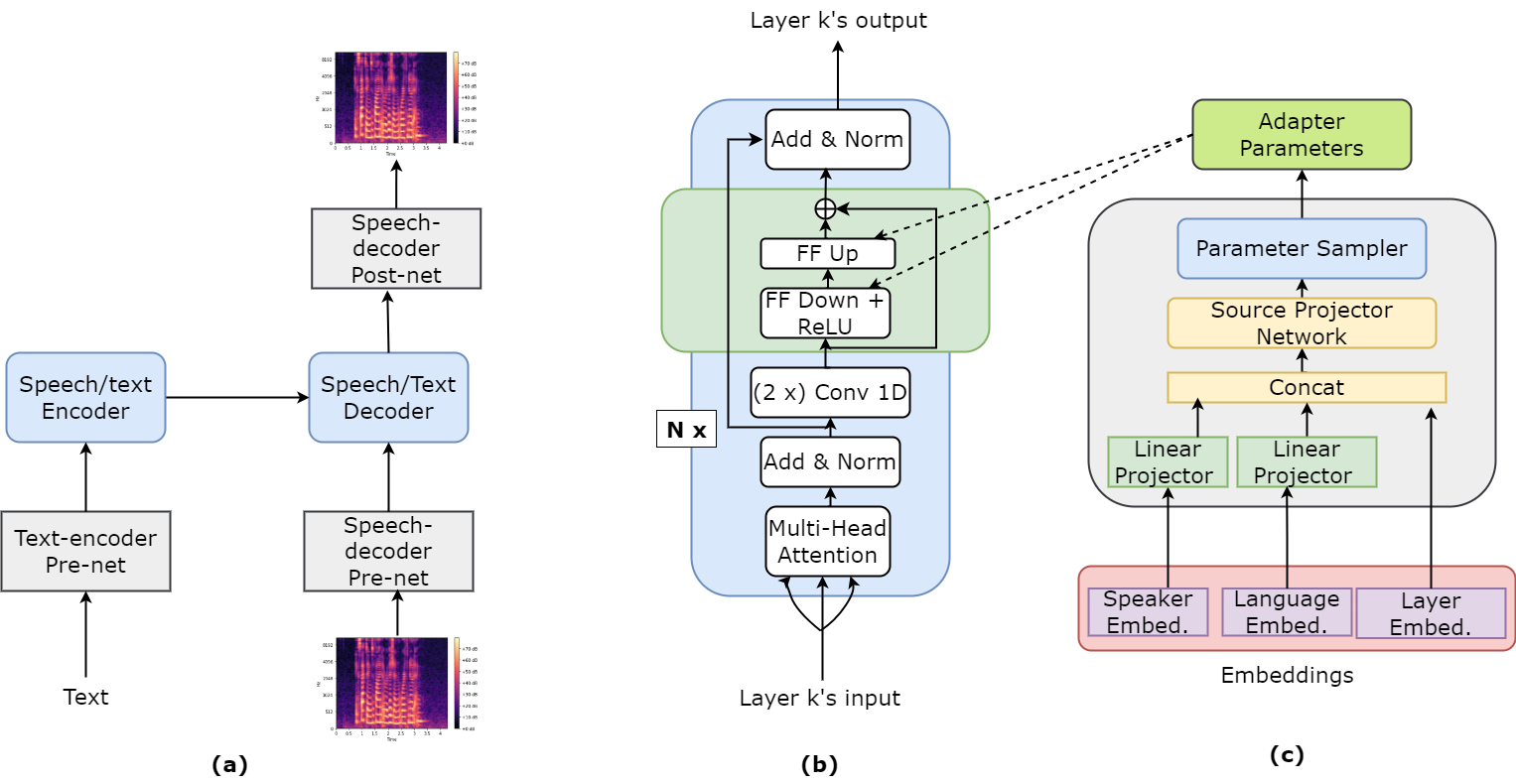
Leveraging Parameter-Efficient Transfer Learning for Multi-Lingual Text-to-Speech Adaptation
Yingting Li, Ambuj Mehrish, Bryan Chew, Bo Cheng, Soujanya Poria
Different languages have distinct phonetic systems and vary in their prosodic features making it challenging to develop a Text-to-Speech (TTS) model that can effectively synthesise speech in multilingual settings. Furthermore, TTS architecture needs to be both efficient enough to capture nuances in multiple languages and efficient enough to be practical for deployment. The standard approach is to build transformer based model such as SpeechT5 and train it on large multilingual dataset. As the size of these models grow the conventional fine-tuning for adapting these model becomes impractical due to heavy computational cost. In this paper, we proposes to integrate parameter-efficient transfer learning (PETL) methods such as adapters and hypernetwork with TTS architecture for multilingual speech synthesis. Notably, in our experiments PETL methods able to achieve comparable or even better performance compared to full fine-tuning with only $sim$2.5% tunable parameters.The code and samples are available at: https://anonymous.4open.science/r/multilingualTTS-BA4C.
Read more6/26/2024
0
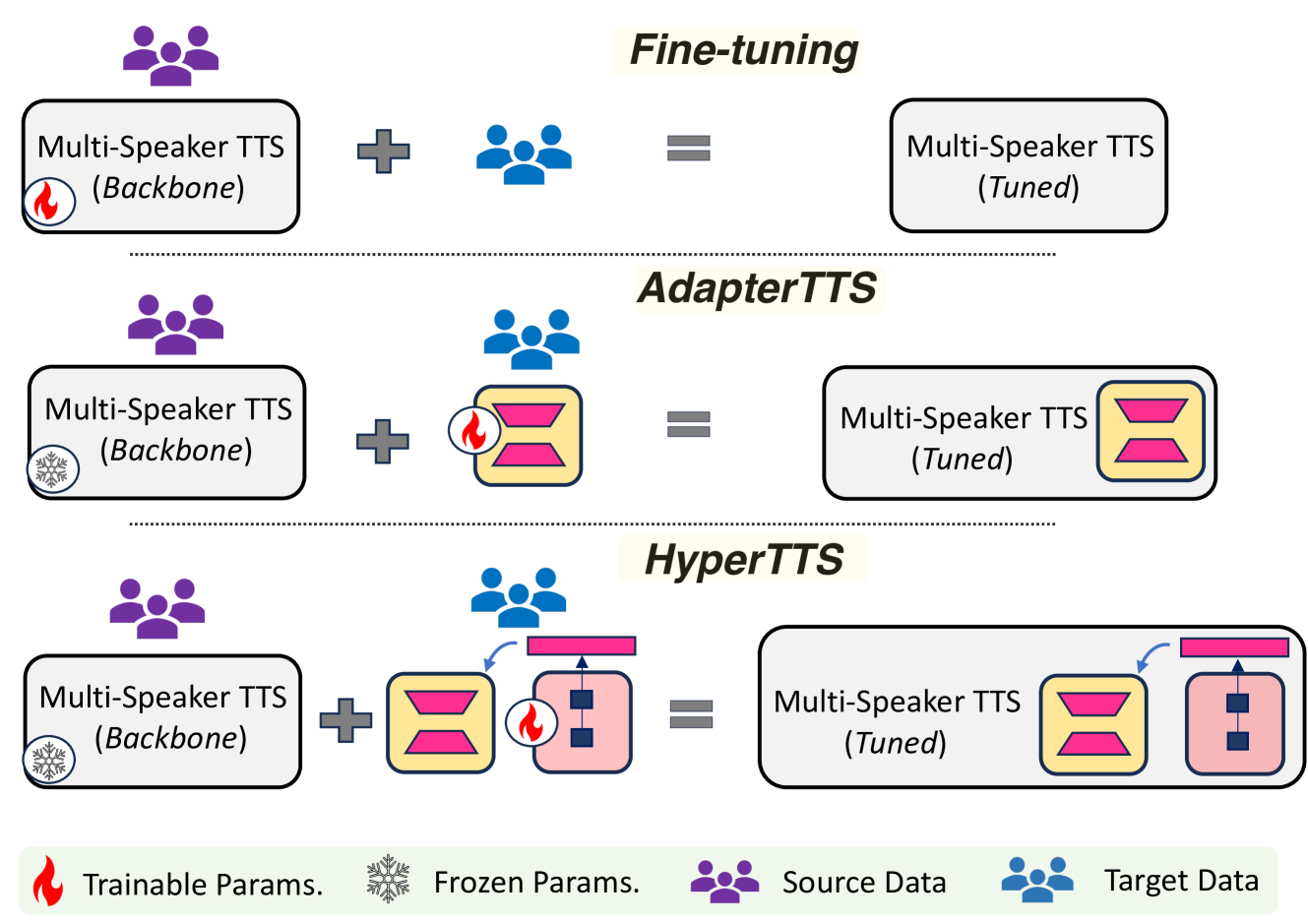
HyperTTS: Parameter Efficient Adaptation in Text to Speech using Hypernetworks
Yingting Li, Rishabh Bhardwaj, Ambuj Mehrish, Bo Cheng, Soujanya Poria
Neural speech synthesis, or text-to-speech (TTS), aims to transform a signal from the text domain to the speech domain. While developing TTS architectures that train and test on the same set of speakers has seen significant improvements, out-of-domain speaker performance still faces enormous limitations. Domain adaptation on a new set of speakers can be achieved by fine-tuning the whole model for each new domain, thus making it parameter-inefficient. This problem can be solved by Adapters that provide a parameter-efficient alternative to domain adaptation. Although famous in NLP, speech synthesis has not seen much improvement from Adapters. In this work, we present HyperTTS, which comprises a small learnable network, hypernetwork, that generates parameters of the Adapter blocks, allowing us to condition Adapters on speaker representations and making them dynamic. Extensive evaluations of two domain adaptation settings demonstrate its effectiveness in achieving state-of-the-art performance in the parameter-efficient regime. We also compare different variants of HyperTTS, comparing them with baselines in different studies. Promising results on the dynamic adaptation of adapter parameters using hypernetworks open up new avenues for domain-generic multi-speaker TTS systems. The audio samples and code are available at https://github.com/declare-lab/HyperTTS.
Read more4/9/2024