VRDSynth: Synthesizing Programs for Multilingual Visually Rich Document Information Extraction

0

Sign in to get full access
Overview
- The paper presents a novel approach called Bridgar for effective information extraction from visually-rich documents using a combination of graph neural networks and program synthesis.
- The proposed method aims to address the challenges of extracting structured information from complex, visually-dense documents like scientific papers, patents, and financial reports.
- Bridgar leverages the hierarchical and relational structure of documents to build a graph representation, which is then processed by a graph neural network to identify and extract relevant information.
- The extracted information is then used to synthesize executable programs that can automate the information extraction process for similar documents.
Plain English Explanation
The paper introduces a new system called Bridgar that can effectively extract important information from complex, visually-rich documents like research papers, patents, and financial reports. These types of documents often have a lot of visual elements like figures, tables, and formatting that can make it challenging to automatically extract the key facts and data.
Bridgar tackles this problem by first converting the document into a graph representation, which captures the hierarchical structure and relationships between different parts of the document. This graph is then processed by a specialized neural network that can understand the patterns and connections in the document. Based on this analysis, Bridgar is able to identify and extract the most relevant information, such as the study's objective, methodology, results, and conclusions.
But Bridgar goes one step further - it then uses this extracted information to synthesize a custom computer program that can automatically process similar documents in the future. This allows the system to scale and apply the information extraction process to large collections of documents, saving time and effort compared to manual review.
Overall, Bridgar represents an innovative approach to making sense of visually-dense, information-rich documents by combining advanced graph neural networks and program synthesis techniques. This could have valuable applications in fields like academic research, patent analysis, and financial reporting, where efficiently extracting key insights from complex documents is crucial.
Technical Explanation
The Bridgar system proposed in the paper leverages a graph neural network (GNN) architecture to extract structured information from visually-rich documents. The authors first construct a document graph that represents the hierarchical layout and semantic relationships within the document. This graph is then passed through a series of GNN layers that learn to encode the document's structure and content.
Building on this graph-based document representation, the authors use program synthesis techniques to generate executable programs that can automatically extract the desired information from the document. These programs are designed to generalize to similar documents, allowing the system to scale and apply the extraction process efficiently.
The authors evaluate Bridgar on a range of visually-rich document types, including scientific papers, patents, and financial reports. They demonstrate that Bridgar outperforms existing information extraction approaches, particularly for complex documents with heavy use of visual elements and formatting. The program synthesis component also allows Bridgar to generate extraction programs that can be applied to new, unseen documents with high accuracy.
Critical Analysis
The Bridgar system presented in the paper represents a promising approach to addressing the challenge of information extraction from visually-rich documents. By leveraging the power of graph neural networks and program synthesis, the authors have developed a scalable and adaptable solution that can handle the complexity of these types of documents.
One potential limitation of the Bridgar system is the reliance on the initial document graph construction, which could be sensitive to the quality and accuracy of the underlying document parsing and analysis. The authors do not provide a detailed discussion of the robustness of this step, which could be an important consideration for real-world deployment.
Additionally, while the program synthesis component allows for generalization to new documents, the authors do not explore the limits of this capability. It would be valuable to understand how well the synthesized extraction programs perform on documents that are significantly different from the training data, or how the system handles evolving document formats and structures over time.
Nonetheless, the Bridgar approach represents an important step forward in the field of information extraction, particularly for visually-rich and complex document types. The combination of graph-based document representation and program synthesis is a novel and promising direction that could have far-reaching implications for a variety of applications, from academic research to financial analysis and beyond.
Conclusion
The Bridgar system presented in this paper offers an innovative solution for effective information extraction from visually-rich documents. By leveraging graph neural networks and program synthesis, the authors have developed a scalable and adaptable system that can handle the complexity of documents like scientific papers, patents, and financial reports.
The key contributions of Bridgar include its ability to construct a hierarchical, graph-based representation of document structure and content, and its use of program synthesis to generate customized extraction programs that can be applied to new, unseen documents. This combination of advanced techniques allows Bridgar to outperform existing information extraction methods, particularly for complex, visually-dense documents.
Overall, the Bridgar system represents an important step forward in the field of information extraction, with the potential to have a significant impact on a wide range of applications that rely on efficiently and accurately extracting insights from large collections of complex documents. As the volume and complexity of data continues to grow, innovative approaches like Bridgar will be increasingly essential for unlocking the value hidden within these visually-rich information sources.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
VRDSynth: Synthesizing Programs for Multilingual Visually Rich Document Information Extraction
Thanh-Dat Nguyen (Pick), Tung Do-Viet (Pick), Hung Nguyen-Duy (Pick), Tuan-Hai Luu (Pick), Hung Le (Pick), Bach Le (Pick), Patanamon (Pick), Thongtanunam
Businesses need to query visually rich documents (VRDs) like receipts, medical records, and insurance forms to make decisions. Existing techniques for extracting entities from VRDs struggle with new layouts or require extensive pre-training data. We introduce VRDSynth, a program synthesis method to automatically extract entity relations from multilingual VRDs without pre-training data. To capture the complexity of VRD domain, we design a domain-specific language (DSL) to capture spatial and textual relations to describe the synthesized programs. Along with this, we also derive a new synthesis algorithm utilizing frequent spatial relations, search space pruning, and a combination of positive, negative, and exclusive programs to improve coverage. We evaluate VRDSynth on the FUNSD and XFUND benchmarks for semantic entity linking, consisting of 1,592 forms in 8 languages. VRDSynth outperforms state-of-the-art pre-trained models (LayoutXLM, InfoXLMBase, and XLMRobertaBase) in 5, 6, and 7 out of 8 languages, respectively, improving the F1 score by 42% over LayoutXLM in English. To test the extensibility of the model, we further improve VRDSynth with automated table recognition, creating VRDSynth(Table), and compare it with extended versions of the pre-trained models, InfoXLM(Large) and XLMRoberta(Large). VRDSynth(Table) outperforms these baselines in 4 out of 8 languages and in average F1 score. VRDSynth also significantly reduces memory footprint (1M and 380MB vs. 1.48GB and 3GB for LayoutXLM) while maintaining similar time efficiency.
Read more7/10/2024
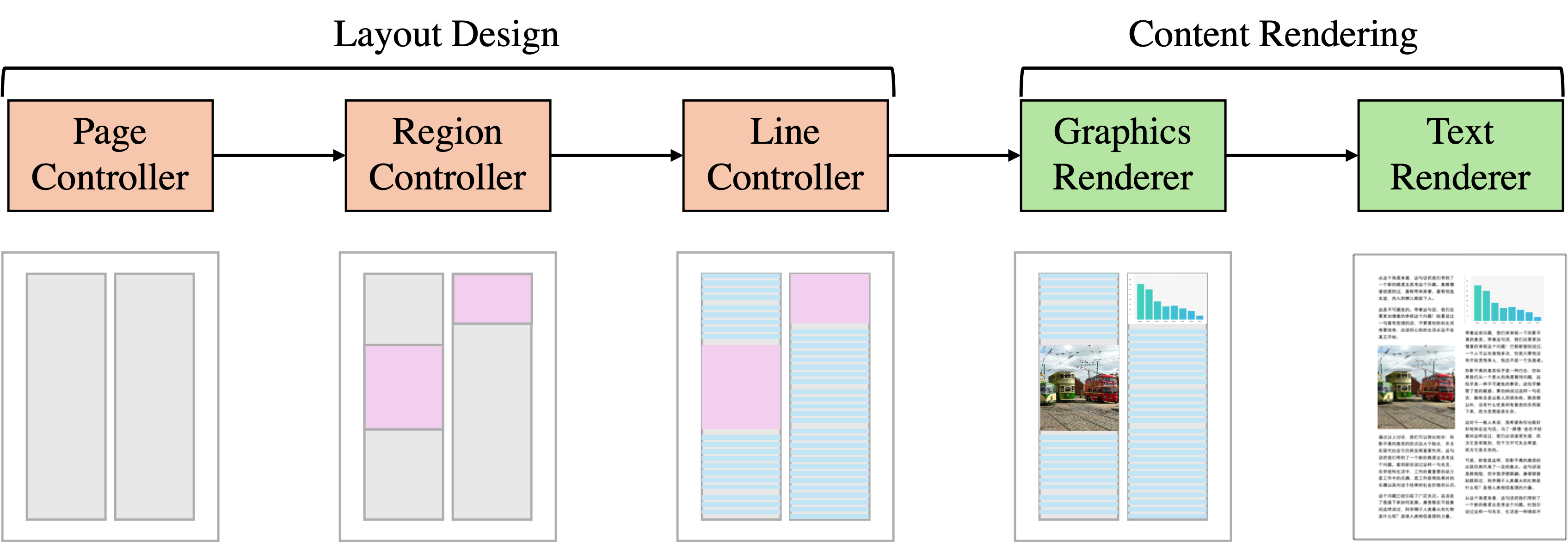
0
SynthDoc: Bilingual Documents Synthesis for Visual Document Understanding
Chuanghao Ding, Xuejing Liu, Wei Tang, Juan Li, Xiaoliang Wang, Rui Zhao, Cam-Tu Nguyen, Fei Tan
This paper introduces SynthDoc, a novel synthetic document generation pipeline designed to enhance Visual Document Understanding (VDU) by generating high-quality, diverse datasets that include text, images, tables, and charts. Addressing the challenges of data acquisition and the limitations of existing datasets, SynthDoc leverages publicly available corpora and advanced rendering tools to create a comprehensive and versatile dataset. Our experiments, conducted using the Donut model, demonstrate that models trained with SynthDoc's data achieve superior performance in pre-training read tasks and maintain robustness in downstream tasks, despite language inconsistencies. The release of a benchmark dataset comprising 5,000 image-text pairs not only showcases the pipeline's capabilities but also provides a valuable resource for the VDU community to advance research and development in document image recognition. This work significantly contributes to the field by offering a scalable solution to data scarcity and by validating the efficacy of end-to-end models in parsing complex, real-world documents.
Read more8/28/2024

0
3D Vision and Language Pretraining with Large-Scale Synthetic Data
Dejie Yang, Zhu Xu, Wentao Mo, Qingchao Chen, Siyuan Huang, Yang Liu
3D Vision-Language Pre-training (3D-VLP) aims to provide a pre-train model which can bridge 3D scenes with natural language, which is an important technique for embodied intelligence. However, current 3D-VLP datasets are hindered by limited scene-level diversity and insufficient fine-grained annotations (only 1.2K scenes and 280K textual annotations in ScanScribe), primarily due to the labor-intensive of collecting and annotating 3D scenes. To overcome these obstacles, we construct SynVL3D, a comprehensive synthetic scene-text corpus with 10K indoor scenes and 1M descriptions at object, view, and room levels, which has the advantages of diverse scene data, rich textual descriptions, multi-grained 3D-text associations, and low collection cost. Utilizing the rich annotations in SynVL3D, we pre-train a simple and unified Transformer for aligning 3D and language with multi-grained pretraining tasks. Moreover, we propose a synthetic-to-real domain adaptation in downstream task fine-tuning process to address the domain shift. Through extensive experiments, we verify the effectiveness of our model design by achieving state-of-the-art performance on downstream tasks including visual grounding, dense captioning, and question answering.
Read more7/9/2024

0
Deep Learning based Visually Rich Document Content Understanding: A Survey
Yihao Ding, Jean Lee, Soyeon Caren Han
Visually Rich Documents (VRDs) are essential in academia, finance, medical fields, and marketing due to their multimodal information content. Traditional methods for extracting information from VRDs depend on expert knowledge and manual labor, making them costly and inefficient. The advent of deep learning has revolutionized this process, introducing models that leverage multimodal information vision, text, and layout along with pretraining tasks to develop comprehensive document representations. These models have achieved state-of-the-art performance across various downstream tasks, significantly enhancing the efficiency and accuracy of information extraction from VRDs. In response to the growing demands and rapid developments in Visually Rich Document Understanding (VRDU), this paper provides a comprehensive review of deep learning-based VRDU frameworks. We systematically survey and analyze existing methods and benchmark datasets, categorizing them based on adopted strategies and downstream tasks. Furthermore, we compare different techniques used in VRDU models, focusing on feature representation and fusion, model architecture, and pretraining methods, while highlighting their strengths, limitations, and appropriate scenarios. Finally, we identify emerging trends and challenges in VRDU, offering insights into future research directions and practical applications. This survey aims to provide a thorough understanding of VRDU advancements, benefiting both academic and industrial sectors.
Read more8/6/2024