SynthDoc: Bilingual Documents Synthesis for Visual Document Understanding

0
Sign in to get full access
Overview
- Summarizes a research paper on "SynthDoc: Bilingual Documents Synthesis for Visual Document Understanding"
- Covers the paper's key elements, including the introduction, related work, technical explanation, critical analysis, and conclusion
- Provides a plain English explanation of the paper's core ideas and their significance
- Highlights potential limitations and areas for further research
Plain English Explanation
The paper presents a novel approach called "SynthDoc" that aims to improve visual document understanding by generating synthetic bilingual documents. The core idea is to create a large and diverse dataset of realistic-looking documents in multiple languages, which can then be used to train more robust and accurate document analysis models.
Visual Document Understanding is the task of automatically extracting information from scanned or digital documents, such as extracting key text, tables, and figures. This is an important problem with applications in areas like document analysis, financial document processing, and medical record management.
The researchers argue that existing document understanding models often struggle with diverse, real-world documents, especially those in multiple languages. By generating a large, high-quality dataset of synthetic bilingual documents, the SynthDoc approach aims to boost the performance of these models and make them more robust to the types of documents they will encounter in the real world.
Technical Explanation
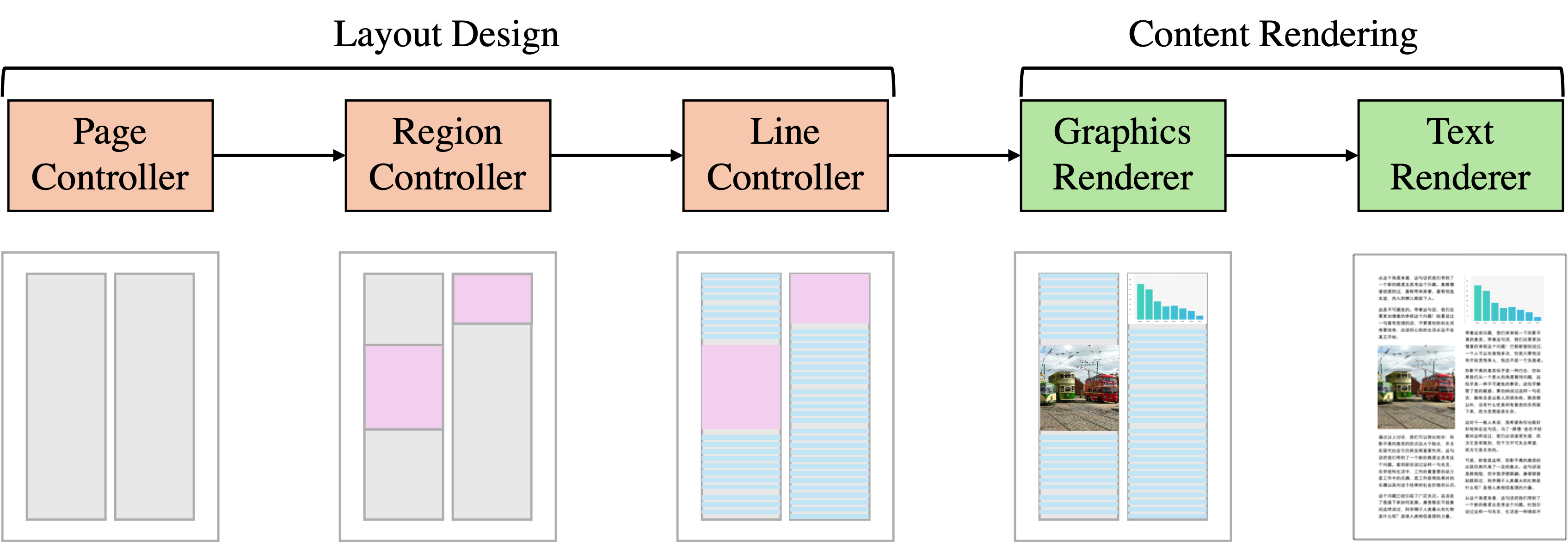
The SynthDoc approach involves several key steps:
-
Document Template Generation: The researchers develop a set of document templates that capture the structural and visual characteristics of various document types, such as invoices, forms, and scientific papers.
-
Bilingual Content Synthesis: For each document template, the system generates corresponding text content in two languages (e.g., English and Chinese). This is done using language models and translation techniques to ensure the content is coherent and grammatically correct.
-
Visual Rendering: The system then combines the bilingual content with the document templates to create the final synthetic documents, complete with realistic layouts, fonts, and visual elements.
The resulting SynthDoc dataset contains a large number of high-quality, bilingual documents that can be used to train and evaluate document understanding models. The researchers demonstrate that models trained on SynthDoc data outperform those trained on existing document datasets, especially on cross-lingual and visually complex documents.
Critical Analysis
The SynthDoc approach is a promising step forward in the field of visual document understanding, but it also has some potential limitations:
-
Limited Diversity: While the researchers generate a large number of synthetic documents, the diversity of document types and layouts may be limited by the set of predefined templates. Real-world documents can be highly varied and unpredictable, which could pose challenges for models trained solely on synthetic data.
-
Language Limitations: The current SynthDoc dataset focuses on English and Chinese, which may limit its applicability to documents in other languages. Extending the approach to support a wider range of languages could be an area for future research.
-
Evaluation Challenges: Assessing the true effectiveness of the SynthDoc approach may require extensive real-world testing and validation, as the performance gains observed in the paper's experiments may not fully translate to practical document understanding tasks.
Despite these potential limitations, the SynthDoc approach represents an important step forward in the quest for more robust and accurate document understanding models. By leveraging synthetic data generation, the researchers have demonstrated a novel way to address the challenges posed by the diversity and multilingualism of real-world documents.
Conclusion
The SynthDoc paper presents a novel approach to improving visual document understanding by generating a large, high-quality dataset of synthetic bilingual documents. By combining document templates, bilingual content synthesis, and realistic visual rendering, the researchers have created a powerful tool for training more robust and accurate document analysis models.
While the approach has some potential limitations, the paper's findings suggest that synthetic data generation could be a valuable technique for addressing the challenges of diverse, multilingual documents in real-world applications. As the field of document understanding continues to evolve, the SynthDoc approach may serve as a model for future innovations in this important area of research.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
SynthDoc: Bilingual Documents Synthesis for Visual Document Understanding
Chuanghao Ding, Xuejing Liu, Wei Tang, Juan Li, Xiaoliang Wang, Rui Zhao, Cam-Tu Nguyen, Fei Tan
This paper introduces SynthDoc, a novel synthetic document generation pipeline designed to enhance Visual Document Understanding (VDU) by generating high-quality, diverse datasets that include text, images, tables, and charts. Addressing the challenges of data acquisition and the limitations of existing datasets, SynthDoc leverages publicly available corpora and advanced rendering tools to create a comprehensive and versatile dataset. Our experiments, conducted using the Donut model, demonstrate that models trained with SynthDoc's data achieve superior performance in pre-training read tasks and maintain robustness in downstream tasks, despite language inconsistencies. The release of a benchmark dataset comprising 5,000 image-text pairs not only showcases the pipeline's capabilities but also provides a valuable resource for the VDU community to advance research and development in document image recognition. This work significantly contributes to the field by offering a scalable solution to data scarcity and by validating the efficacy of end-to-end models in parsing complex, real-world documents.
Read more8/28/2024

0
SynthVLM: High-Efficiency and High-Quality Synthetic Data for Vision Language Models
Zheng Liu, Hao Liang, Xijie Huang, Wentao Xiong, Qinhan Yu, Linzhuang Sun, Chong Chen, Conghui He, Bin Cui, Wentao Zhang
Recently, with the rise of web images, managing and understanding large-scale image datasets has become increasingly important. Vision Large Language Models (VLLMs) have recently emerged due to their robust vision-understanding capabilities. However, training these models requires vast amounts of data, posing challenges to efficiency, effectiveness, data quality, and privacy. In this paper, we introduce SynthVLM, a novel data synthesis pipeline for VLLMs. Unlike existing methods that generate captions from images, SynthVLM employs advanced diffusion models and high-quality captions to automatically generate and select high-resolution images from captions, creating precisely aligned image-text pairs. Leveraging these pairs, we achieve state-of-the-art (SoTA) performance on various vision question answering tasks, maintaining high alignment quality and preserving advanced language abilities. Moreover, SynthVLM surpasses traditional GPT-4 Vision-based caption generation methods in performance while significantly reducing computational overhead. Crucially, our method's reliance on purely generated data ensures the preservation of privacy, achieving SoTA performance with just 100k data points (only 18% of the official dataset size).
Read more8/13/2024

0
VRDSynth: Synthesizing Programs for Multilingual Visually Rich Document Information Extraction
Thanh-Dat Nguyen (Pick), Tung Do-Viet (Pick), Hung Nguyen-Duy (Pick), Tuan-Hai Luu (Pick), Hung Le (Pick), Bach Le (Pick), Patanamon (Pick), Thongtanunam
Businesses need to query visually rich documents (VRDs) like receipts, medical records, and insurance forms to make decisions. Existing techniques for extracting entities from VRDs struggle with new layouts or require extensive pre-training data. We introduce VRDSynth, a program synthesis method to automatically extract entity relations from multilingual VRDs without pre-training data. To capture the complexity of VRD domain, we design a domain-specific language (DSL) to capture spatial and textual relations to describe the synthesized programs. Along with this, we also derive a new synthesis algorithm utilizing frequent spatial relations, search space pruning, and a combination of positive, negative, and exclusive programs to improve coverage. We evaluate VRDSynth on the FUNSD and XFUND benchmarks for semantic entity linking, consisting of 1,592 forms in 8 languages. VRDSynth outperforms state-of-the-art pre-trained models (LayoutXLM, InfoXLMBase, and XLMRobertaBase) in 5, 6, and 7 out of 8 languages, respectively, improving the F1 score by 42% over LayoutXLM in English. To test the extensibility of the model, we further improve VRDSynth with automated table recognition, creating VRDSynth(Table), and compare it with extended versions of the pre-trained models, InfoXLM(Large) and XLMRoberta(Large). VRDSynth(Table) outperforms these baselines in 4 out of 8 languages and in average F1 score. VRDSynth also significantly reduces memory footprint (1M and 380MB vs. 1.48GB and 3GB for LayoutXLM) while maintaining similar time efficiency.
Read more7/10/2024
0
Synth$^2$: Boosting Visual-Language Models with Synthetic Captions and Image Embeddings
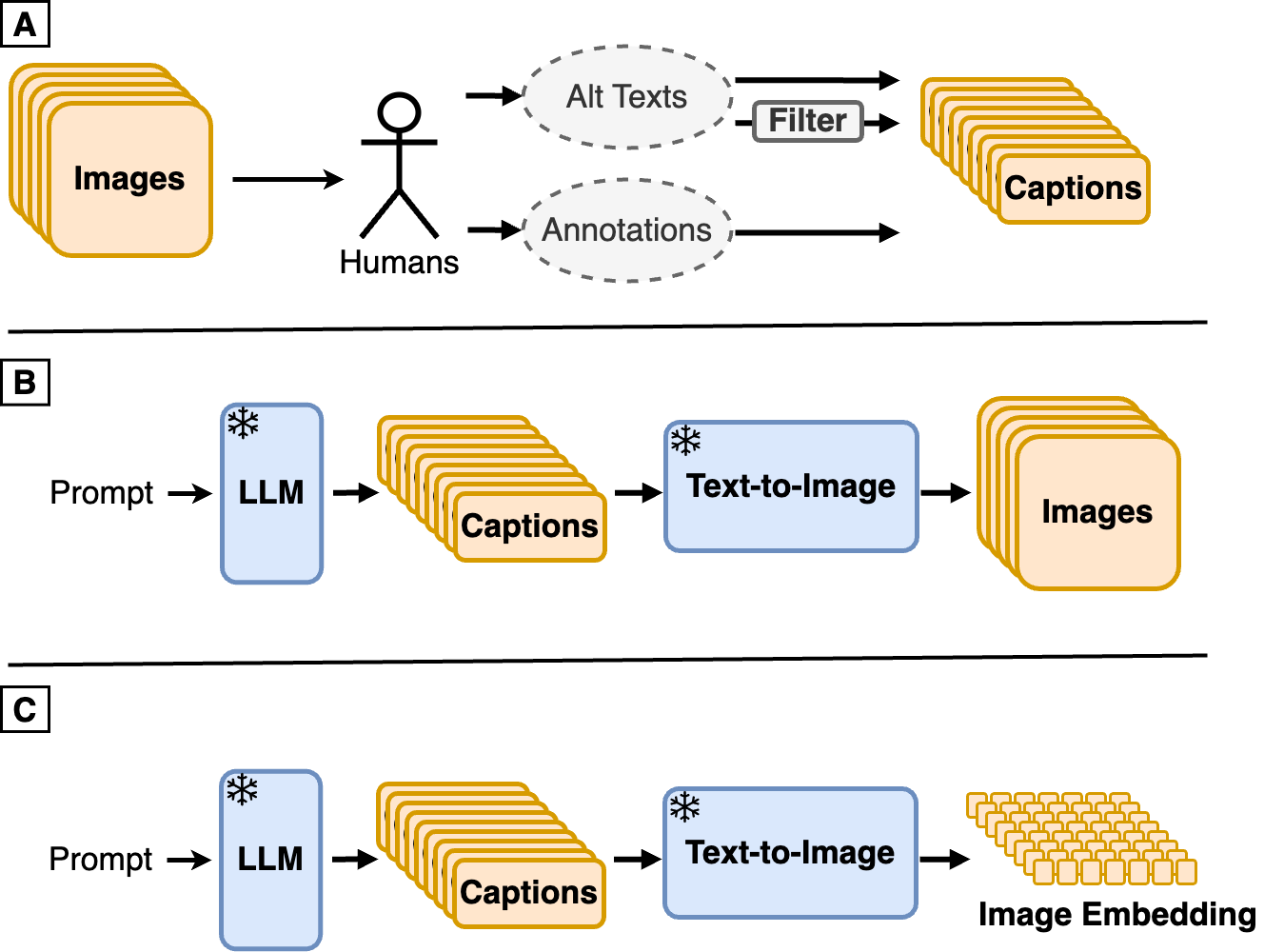
Sahand Sharifzadeh, Christos Kaplanis, Shreya Pathak, Dharshan Kumaran, Anastasija Ilic, Jovana Mitrovic, Charles Blundell, Andrea Banino
The creation of high-quality human-labeled image-caption datasets presents a significant bottleneck in the development of Visual-Language Models (VLMs). In this work, we investigate an approach that leverages the strengths of Large Language Models (LLMs) and image generation models to create synthetic image-text pairs for efficient and effective VLM training. Our method employs a pretrained text-to-image model to synthesize image embeddings from captions generated by an LLM. Despite the text-to-image model and VLM initially being trained on the same data, our approach leverages the image generator's ability to create novel compositions, resulting in synthetic image embeddings that expand beyond the limitations of the original dataset. Extensive experiments demonstrate that our VLM, finetuned on synthetic data achieves comparable performance to models trained solely on human-annotated data, while requiring significantly less data. Furthermore, we perform a set of analyses on captions which reveals that semantic diversity and balance are key aspects for better downstream performance. Finally, we show that synthesizing images in the image embedding space is 25% faster than in the pixel space. We believe our work not only addresses a significant challenge in VLM training but also opens up promising avenues for the development of self-improving multi-modal models.
Read more6/10/2024