VSSD: Vision Mamba with Non-Casual State Space Duality

0

Sign in to get full access
Overview
- This paper introduces a new computer vision model called VSSD (Vision Mamba with Non-Casual State Space Duality).
- VSSD combines the capabilities of the Vision Mamba architecture with a novel non-causal state space duality approach.
- The goal is to improve the performance and robustness of visual state space models for various computer vision tasks.
Plain English Explanation
The paper presents a new deep learning model called VSSD (Vision Mamba with Non-Casual State Space Duality). VSSD builds upon the Vision Mamba architecture, which is a powerful visual state space model. VSSD adds a novel "non-causal state space duality" component to the Vision Mamba model.
The key idea behind non-causal state space duality is to allow the model to learn and represent visual information in a more flexible and robust way. Traditional deep learning models often make assumptions about the causal relationships between input and output data. In contrast, VSSD's non-causal approach enables the model to capture more complex, multi-directional dependencies in the visual data.
By combining the strengths of Vision Mamba with this new non-causal state space mechanism, the VSSD model aims to achieve better performance and increased robustness on a variety of computer vision tasks, such as image classification, object detection, and segmentation.
Technical Explanation
The VSSD model builds upon the Vision Mamba architecture, which is a multi-scale, hierarchical visual state space model. VSSD adds a novel "non-causal state space duality" component to the core Vision Mamba model.
The non-causal state space duality allows the VSSD model to learn and represent visual information in a more flexible and expressive way, compared to traditional causal deep learning models. Instead of making strict assumptions about the directionality of the relationships between input and output data, VSSD's non-causal approach enables the model to capture more complex, multi-directional dependencies in the visual data.
To implement this, the VSSD model incorporates additional state space layers that operate in a non-causal manner, complementing the causal state space mechanisms of the original Vision Mamba. This dual state space structure allows the model to learn richer, more robust representations of the visual input.
The authors evaluate VSSD on a range of computer vision benchmarks, including image classification, object detection, and segmentation tasks. The results demonstrate that VSSD outperforms the original Vision Mamba model and other state-of-the-art approaches, highlighting the advantages of the non-causal state space duality for improving the performance and robustness of visual state space models.
Critical Analysis
The paper presents a novel and promising approach with the VSSD model, but there are a few potential limitations and areas for further research:
-
Computational Complexity: The addition of the non-causal state space duality component may increase the computational complexity and memory requirements of the VSSD model compared to the original Vision Mamba. The authors should investigate the trade-offs between the performance gains and the increased computational cost.
-
Interpretability: While the non-causal state space duality aims to capture more complex visual relationships, it may also introduce challenges in interpreting the model's internal representations and decision-making processes. Further research on the interpretability of VSSD could be valuable.
-
Generalization: The authors should explore the generalization capabilities of VSSD beyond the specific benchmarks presented in the paper. Evaluating the model's performance on a broader range of computer vision tasks and datasets would provide a more comprehensive understanding of its strengths and limitations.
-
Real-world Deployment: The paper does not address the practical considerations for deploying VSSD in real-world applications, such as its performance on edge devices or its sensitivity to noisy or adversarial inputs. Investigating these aspects could broaden the impact of the research.
Overall, the VSSD model presents an interesting and potentially impactful advancement in the field of visual state space models, but further research and validation will be necessary to fully understand its capabilities and limitations.
Conclusion
This paper introduces the VSSD (Vision Mamba with Non-Casual State Space Duality) model, which combines the strengths of the Vision Mamba architecture with a novel non-causal state space duality approach. The key contribution of VSSD is its ability to learn more flexible and robust visual representations by capturing complex, multi-directional dependencies in the data, rather than relying on strict causal assumptions.
The experimental results demonstrate that VSSD outperforms the original Vision Mamba model and other state-of-the-art approaches on various computer vision tasks, highlighting the potential of this new technique for improving the performance and robustness of visual state space models. While the paper presents a promising advancement, further research is needed to fully understand the limitations, scalability, and real-world applicability of the VSSD model.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
VSSD: Vision Mamba with Non-Casual State Space Duality
Yuheng Shi, Minjing Dong, Mingjia Li, Chang Xu
Vision transformers have significantly advanced the field of computer vision, offering robust modeling capabilities and global receptive field. However, their high computational demands limit their applicability in processing long sequences. To tackle this issue, State Space Models (SSMs) have gained prominence in vision tasks as they offer linear computational complexity. Recently, State Space Duality (SSD), an improved variant of SSMs, was introduced in Mamba2 to enhance model performance and efficiency. However, the inherent causal nature of SSD/SSMs restricts their applications in non-causal vision tasks. To address this limitation, we introduce Visual State Space Duality (VSSD) model, which has a non-causal format of SSD. Specifically, we propose to discard the magnitude of interactions between the hidden state and tokens while preserving their relative weights, which relieves the dependencies of token contribution on previous tokens. Together with the involvement of multi-scan strategies, we show that the scanning results can be integrated to achieve non-causality, which not only improves the performance of SSD in vision tasks but also enhances its efficiency. We conduct extensive experiments on various benchmarks including image classification, detection, and segmentation, where VSSD surpasses existing state-of-the-art SSM-based models. Code and weights are available at url{https://github.com/YuHengsss/VSSD}.
Read more7/29/2024
📈
0
Multi-Scale VMamba: Hierarchy in Hierarchy Visual State Space Model
Yuheng Shi, Minjing Dong, Chang Xu
Despite the significant achievements of Vision Transformers (ViTs) in various vision tasks, they are constrained by the quadratic complexity. Recently, State Space Models (SSMs) have garnered widespread attention due to their global receptive field and linear complexity with respect to the input length, demonstrating substantial potential across fields including natural language processing and computer vision. To improve the performance of SSMs in vision tasks, a multi-scan strategy is widely adopted, which leads to significant redundancy of SSMs. For a better trade-off between efficiency and performance, we analyze the underlying reasons behind the success of the multi-scan strategy, where long-range dependency plays an important role. Based on the analysis, we introduce Multi-Scale Vision Mamba (MSVMamba) to preserve the superiority of SSMs in vision tasks with limited parameters. It employs a multi-scale 2D scanning technique on both original and downsampled feature maps, which not only benefits long-range dependency learning but also reduces computational costs. Additionally, we integrate a Convolutional Feed-Forward Network (ConvFFN) to address the lack of channel mixing. Our experiments demonstrate that MSVMamba is highly competitive, with the MSVMamba-Tiny model achieving 82.8% top-1 accuracy on ImageNet, 46.9% box mAP, and 42.2% instance mAP with the Mask R-CNN framework, 1x training schedule on COCO, and 47.6% mIoU with single-scale testing on ADE20K.Code is available at url{https://github.com/YuHengsss/MSVMamba}.
Read more5/24/2024
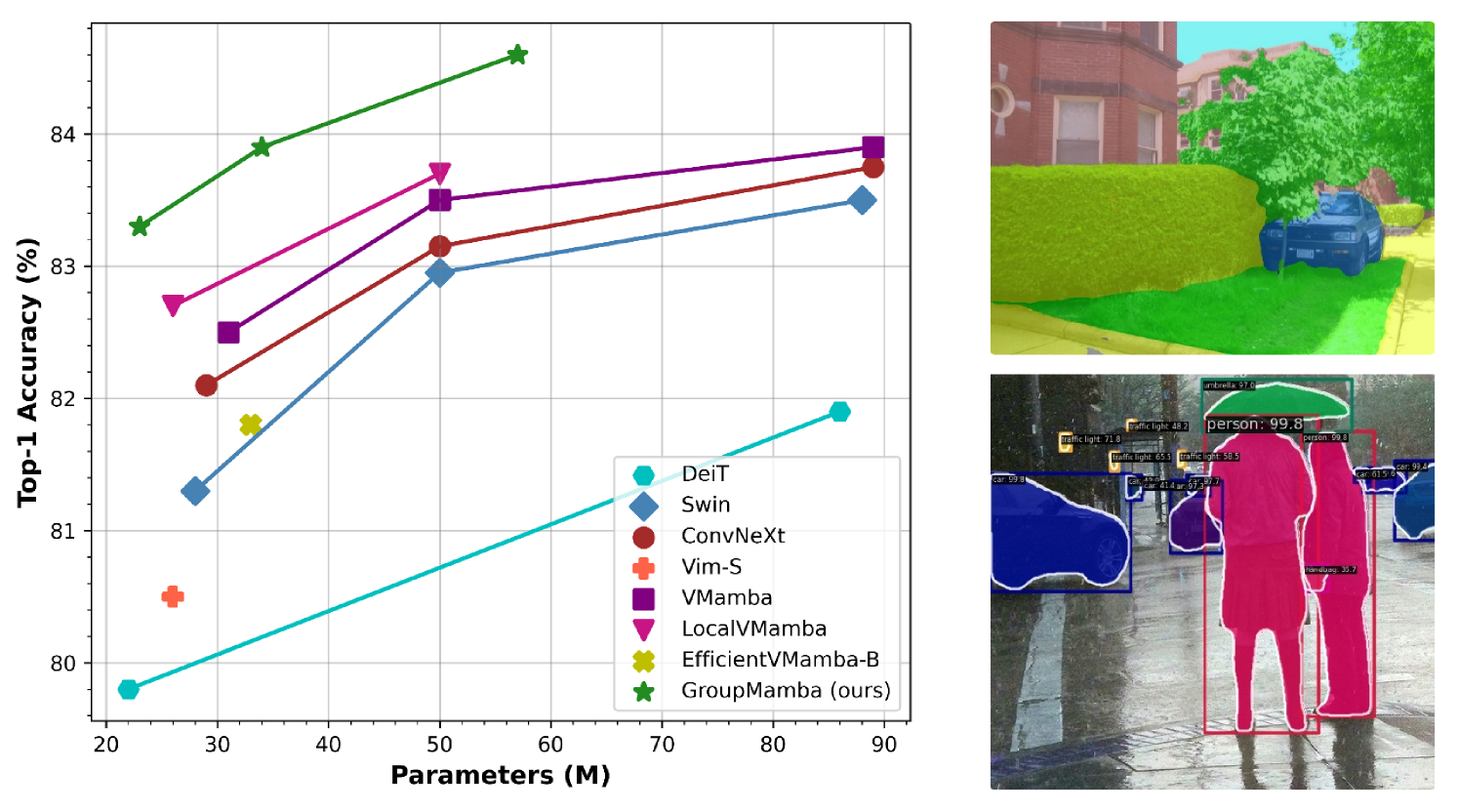
0
GroupMamba: Parameter-Efficient and Accurate Group Visual State Space Model
Abdelrahman Shaker, Syed Talal Wasim, Salman Khan, Juergen Gall, Fahad Shahbaz Khan
Recent advancements in state-space models (SSMs) have showcased effective performance in modeling long-range dependencies with subquadratic complexity. However, pure SSM-based models still face challenges related to stability and achieving optimal performance on computer vision tasks. Our paper addresses the challenges of scaling SSM-based models for computer vision, particularly the instability and inefficiency of large model sizes. To address this, we introduce a Modulated Group Mamba layer which divides the input channels into four groups and applies our proposed SSM-based efficient Visual Single Selective Scanning (VSSS) block independently to each group, with each VSSS block scanning in one of the four spatial directions. The Modulated Group Mamba layer also wraps the four VSSS blocks into a channel modulation operator to improve cross-channel communication. Furthermore, we introduce a distillation-based training objective to stabilize the training of large models, leading to consistent performance gains. Our comprehensive experiments demonstrate the merits of the proposed contributions, leading to superior performance over existing methods for image classification on ImageNet-1K, object detection, instance segmentation on MS-COCO, and semantic segmentation on ADE20K. Our tiny variant with 23M parameters achieves state-of-the-art performance with a classification top-1 accuracy of 83.3% on ImageNet-1K, while being 26% efficient in terms of parameters, compared to the best existing Mamba design of same model size. Our code and models are available at: https://github.com/Amshaker/GroupMamba.
Read more7/19/2024
0
Vision Mamba: A Comprehensive Survey and Taxonomy
Xiao Liu, Chenxu Zhang, Lei Zhang
State Space Model (SSM) is a mathematical model used to describe and analyze the behavior of dynamic systems. This model has witnessed numerous applications in several fields, including control theory, signal processing, economics and machine learning. In the field of deep learning, state space models are used to process sequence data, such as time series analysis, natural language processing (NLP) and video understanding. By mapping sequence data to state space, long-term dependencies in the data can be better captured. In particular, modern SSMs have shown strong representational capabilities in NLP, especially in long sequence modeling, while maintaining linear time complexity. Notably, based on the latest state-space models, Mamba merges time-varying parameters into SSMs and formulates a hardware-aware algorithm for efficient training and inference. Given its impressive efficiency and strong long-range dependency modeling capability, Mamba is expected to become a new AI architecture that may outperform Transformer. Recently, a number of works have attempted to study the potential of Mamba in various fields, such as general vision, multi-modal, medical image analysis and remote sensing image analysis, by extending Mamba from natural language domain to visual domain. To fully understand Mamba in the visual domain, we conduct a comprehensive survey and present a taxonomy study. This survey focuses on Mamba's application to a variety of visual tasks and data types, and discusses its predecessors, recent advances and far-reaching impact on a wide range of domains. Since Mamba is now on an upward trend, please actively notice us if you have new findings, and new progress on Mamba will be included in this survey in a timely manner and updated on the Mamba project at https://github.com/lx6c78/Vision-Mamba-A-Comprehensive-Survey-and-Taxonomy.
Read more5/8/2024