VulnLLMEval: A Framework for Evaluating Large Language Models in Software Vulnerability Detection and Patching

0

Sign in to get full access
Overview
- Introduces VulnLLMEval, a framework for evaluating large language models (LLMs) in software vulnerability detection and patching
- Aims to benchmark the capabilities of LLMs in identifying and fixing security vulnerabilities in code
- Provides a standardized evaluation setup and datasets to enable fair and comprehensive assessment of LLM performance
Plain English Explanation
VulnLLMEval is a new framework that allows researchers to test how well large language models (LLMs) can identify and fix security vulnerabilities in software code. LLMs are powerful AI systems that can understand and generate human-like text, and the researchers wanted to see if these models could be used to improve software security.
The framework includes standardized datasets and evaluation procedures, which means that different LLMs can be tested in the same way. This allows for a fair and comprehensive assessment of the models' capabilities in detecting and patching vulnerabilities. The researchers hope that VulnLLMEval will help advance the field of using LLMs for cybersecurity applications, such as automatically finding and fixing security flaws in software.
Technical Explanation
VulnLLMEval is a framework designed to evaluate the performance of large language models (LLMs) in software vulnerability detection and patching. The framework includes a suite of standardized datasets, tasks, and evaluation metrics to enable a fair and comprehensive assessment of LLM capabilities in this domain.
The key components of VulnLLMEval include:
- Datasets: The framework provides several datasets of real-world software codebases with known vulnerabilities, which can be used to test LLM performance on vulnerability detection and patching tasks.
- Tasks: VulnLLMEval defines two main tasks: (1) identifying the presence and location of security vulnerabilities in code, and (2) generating patches to fix those vulnerabilities.
- Evaluation Metrics: The framework uses a range of metrics, such as precision, recall, and F1-score, to measure LLM performance on the vulnerability detection and patching tasks.
By using this standardized framework, researchers can compare the performance of different LLMs on software security tasks, and gain insights into the strengths and limitations of these models for real-world cybersecurity applications.
Critical Analysis
The VulnLLMEval framework provides a valuable contribution to the field of using large language models for software security. By standardizing the evaluation setup and datasets, the framework enables a fair and comprehensive assessment of LLM capabilities in vulnerability detection and patching.
However, the paper also acknowledges some limitations of the current framework. For example, the datasets used may not fully capture the diversity and complexity of real-world software vulnerabilities, and the tasks defined may not reflect all the nuances of how LLMs would be used in practical security scenarios.
Additionally, the paper does not address potential biases or ethical concerns that may arise from using LLMs for security-critical applications. As these models become more powerful, it will be important to carefully consider the implications and potential misuse of such technology.
Further research is needed to explore the long-term viability and scalability of using LLMs for software vulnerability management, as well as to address the ethical and societal impacts of this technology.
Conclusion
VulnLLMEval is a promising framework that can help advance the use of large language models for improving software security. By providing a standardized evaluation setup, the framework enables researchers to better understand the capabilities and limitations of LLMs in detecting and fixing security vulnerabilities.
As LLMs continue to evolve and become more powerful, the insights gained from VulnLLMEval could lead to significant improvements in automated vulnerability management and the overall security of software systems. However, it will be crucial to address the ethical considerations and potential risks associated with deploying these AI-powered security tools in real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
VulnLLMEval: A Framework for Evaluating Large Language Models in Software Vulnerability Detection and Patching
Arastoo Zibaeirad, Marco Vieira
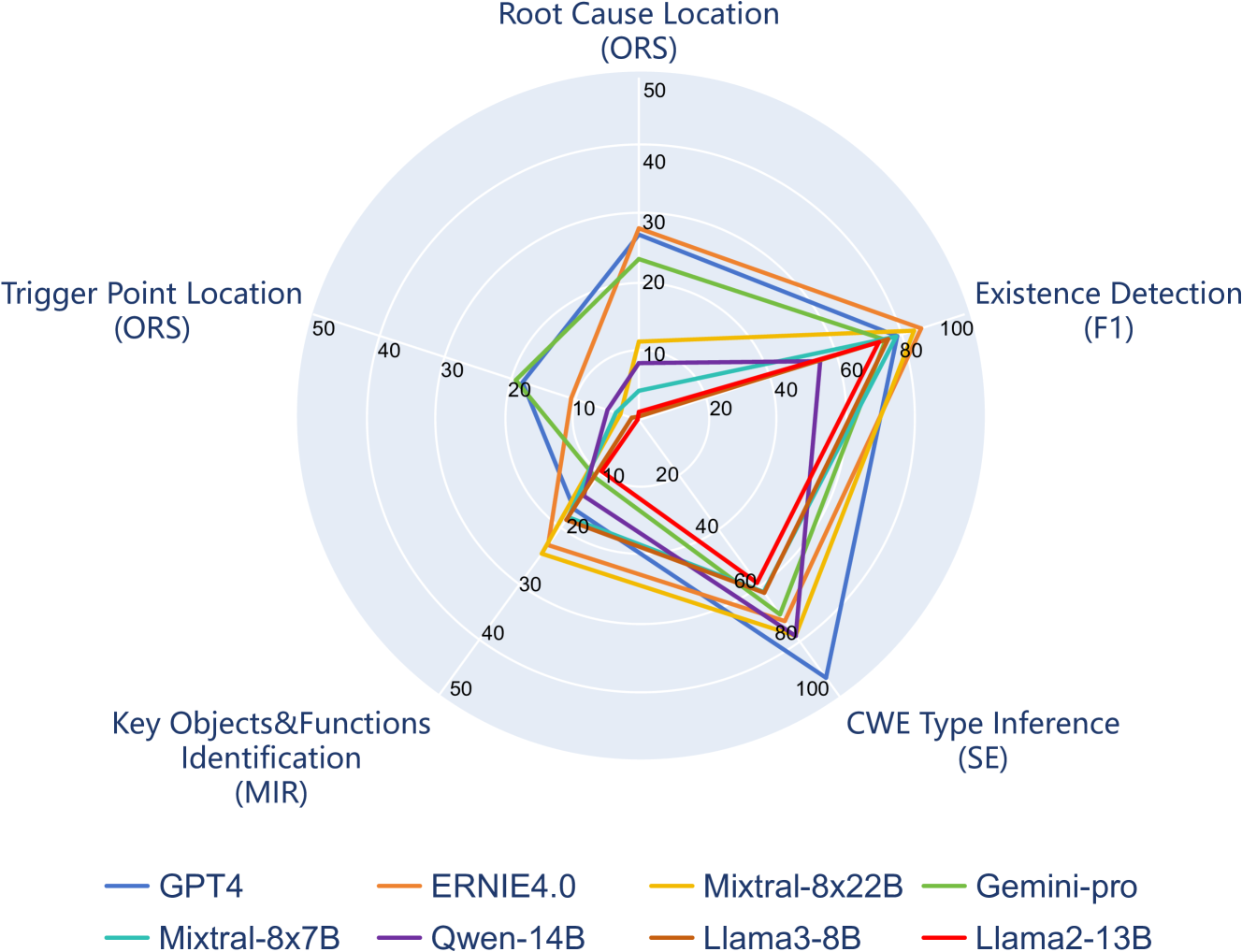
Large Language Models (LLMs) have shown promise in tasks like code translation, prompting interest in their potential for automating software vulnerability detection (SVD) and patching (SVP). To further research in this area, establishing a benchmark is essential for evaluating the strengths and limitations of LLMs in these tasks. Despite their capabilities, questions remain regarding whether LLMs can accurately analyze complex vulnerabilities and generate appropriate patches. This paper introduces VulnLLMEval, a framework designed to assess the performance of LLMs in identifying and patching vulnerabilities in C code. Our study includes 307 real-world vulnerabilities extracted from the Linux kernel, creating a well-curated dataset that includes both vulnerable and patched code. This dataset, based on real-world code, provides a diverse and representative testbed for evaluating LLM performance in SVD and SVP tasks, offering a robust foundation for rigorous assessment. Our results reveal that LLMs often struggle with distinguishing between vulnerable and patched code. Furthermore, in SVP tasks, these models tend to oversimplify the code, producing solutions that may not be directly usable without further refinement.
Read more9/18/2024
0
VulDetectBench: Evaluating the Deep Capability of Vulnerability Detection with Large Language Models
Yu Liu, Lang Gao, Mingxin Yang, Yu Xie, Ping Chen, Xiaojin Zhang, Wei Chen
Large Language Models (LLMs) have training corpora containing large amounts of program code, greatly improving the model's code comprehension and generation capabilities. However, sound comprehensive research on detecting program vulnerabilities, a more specific task related to code, and evaluating the performance of LLMs in this more specialized scenario is still lacking. To address common challenges in vulnerability analysis, our study introduces a new benchmark, VulDetectBench, specifically designed to assess the vulnerability detection capabilities of LLMs. The benchmark comprehensively evaluates LLM's ability to identify, classify, and locate vulnerabilities through five tasks of increasing difficulty. We evaluate the performance of 17 models (both open- and closed-source) and find that while existing models can achieve over 80% accuracy on tasks related to vulnerability identification and classification, they still fall short on specific, more detailed vulnerability analysis tasks, with less than 30% accuracy, making it difficult to provide valuable auxiliary information for professional vulnerability mining. Our benchmark effectively evaluates the capabilities of various LLMs at different levels in the specific task of vulnerability detection, providing a foundation for future research and improvements in this critical area of code security. VulDetectBench is publicly available at https://github.com/Sweetaroo/VulDetectBench.
Read more8/22/2024
💬
0
Harnessing Large Language Models for Software Vulnerability Detection: A Comprehensive Benchmarking Study
Karl Tamberg, Hayretdin Bahsi
Despite various approaches being employed to detect vulnerabilities, the number of reported vulnerabilities shows an upward trend over the years. This suggests the problems are not caught before the code is released, which could be caused by many factors, like lack of awareness, limited efficacy of the existing vulnerability detection tools or the tools not being user-friendly. To help combat some issues with traditional vulnerability detection tools, we propose using large language models (LLMs) to assist in finding vulnerabilities in source code. LLMs have shown a remarkable ability to understand and generate code, underlining their potential in code-related tasks. The aim is to test multiple state-of-the-art LLMs and identify the best prompting strategies, allowing extraction of the best value from the LLMs. We provide an overview of the strengths and weaknesses of the LLM-based approach and compare the results to those of traditional static analysis tools. We find that LLMs can pinpoint many more issues than traditional static analysis tools, outperforming traditional tools in terms of recall and F1 scores. The results should benefit software developers and security analysts responsible for ensuring that the code is free of vulnerabilities.
Read more5/27/2024
🎯
0
Can LLMs Patch Security Issues?
Kamel Alrashedy, Abdullah Aljasser, Pradyumna Tambwekar, Matthew Gombolay
Large Language Models (LLMs) have shown impressive proficiency in code generation. Unfortunately, these models share a weakness with their human counterparts: producing code that inadvertently has security vulnerabilities. These vulnerabilities could allow unauthorized attackers to access sensitive data or systems, which is unacceptable for safety-critical applications. In this work, we propose Feedback-Driven Security Patching (FDSP), where LLMs automatically refine generated, vulnerable code. Our approach leverages automatic static code analysis to empower the LLM to generate and implement potential solutions to address vulnerabilities. We address the research communitys needs for safe code generation by introducing a large-scale dataset, PythonSecurityEval, covering the diversity of real-world applications, including databases, websites and operating systems. We empirically validate that FDSP outperforms prior work that uses self-feedback from LLMs by up to 17.6% through our procedure that injects targeted, external feedback. Code and data are available at url{https://github.com/Kamel773/LLM-code-refine}
Read more7/19/2024