W-RAG: Weakly Supervised Dense Retrieval in RAG for Open-domain Question Answering

0
Sign in to get full access
Overview
- Paper presents W-RAG, a weakly supervised approach to dense retrieval in Retrieval Augmented Generation (RAG) for open-domain question answering
- Key contributions include a novel weakly supervised training objective and an end-to-end architecture that integrates dense retrieval and generation
- Experiments show W-RAG outperforms strong RAG baselines and achieves state-of-the-art results on open-domain QA benchmarks
Plain English Explanation
The paper introduces W-RAG, a new way to improve how Retrieval Augmented Generation (RAG) models work for answering open-ended questions.
RAG models combine retrieval (finding relevant information) and generation (producing answers) to answer questions. W-RAG proposes a "weakly supervised" approach to train the retrieval part of the model. This means the model learns retrieval without having perfect training data, which can be expensive to create.
The key ideas in W-RAG are:
- A new training objective that allows the retrieval part to learn from imperfect training data
- An end-to-end architecture that tightly integrates retrieval and generation
Experiments show W-RAG outperforms previous RAG models and achieves state-of-the-art results on open-domain question answering benchmarks. This demonstrates the benefits of the weakly supervised approach and tight integration of retrieval and generation.
Technical Explanation
The paper introduces W-RAG, a novel approach to Retrieval Augmented Generation (RAG) for open-domain question answering.
RAG models combine a retrieval module, which finds relevant information, and a generation module, which produces answers from the retrieved information. W-RAG proposes a weakly supervised training approach for the retrieval module.
The key technical contributions are:
-
Weakly Supervised Dense Retrieval: W-RAG introduces a novel training objective for the retrieval module that can learn from imperfect training data, rather than requiring expensive human-annotated relevance labels. This allows the model to be trained more efficiently.
-
End-to-End Architecture: W-RAG integrates the retrieval and generation modules into a single end-to-end model, allowing them to be trained jointly and leverage synergies between the two components.
The authors conduct extensive experiments on open-domain question answering benchmarks, demonstrating that W-RAG outperforms strong RAG baselines and achieves state-of-the-art results. This highlights the benefits of the weakly supervised retrieval approach and tight integration of retrieval and generation.
Critical Analysis
The paper presents a compelling approach to improving open-domain question answering by enhancing the retrieval component of RAG models. The key strengths are the novel weakly supervised training objective and the end-to-end architecture.
However, the paper does not deeply explore the limitations of the weakly supervised approach. For example, it is unclear how the performance of W-RAG scales with the quality and quantity of the weakly supervised training data. Further analysis on the robustness and generalization of the approach would be valuable.
Additionally, the paper focuses mainly on quantitative results, with limited discussion of qualitative insights or error analysis. Understanding the types of questions or scenarios where W-RAG excels or struggles could provide valuable guidance for future research directions.
Overall, the paper makes a compelling contribution, but there are opportunities for further research to better understand the strengths, weaknesses, and broader implications of the W-RAG approach.
Conclusion
The W-RAG paper presents a novel approach to enhancing Retrieval Augmented Generation (RAG) models for open-domain question answering. By introducing a weakly supervised training objective for the retrieval module and integrating retrieval and generation in an end-to-end architecture, W-RAG achieves state-of-the-art results on benchmark tasks.
This work demonstrates the potential benefits of weakly supervised learning and tight integration of retrieval and generation for open-domain QA. As language models continue to advance, techniques like W-RAG may play an important role in building more robust and efficient question answering systems that can be deployed in real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
W-RAG: Weakly Supervised Dense Retrieval in RAG for Open-domain Question Answering
Jinming Nian, Zhiyuan Peng, Qifan Wang, Yi Fang
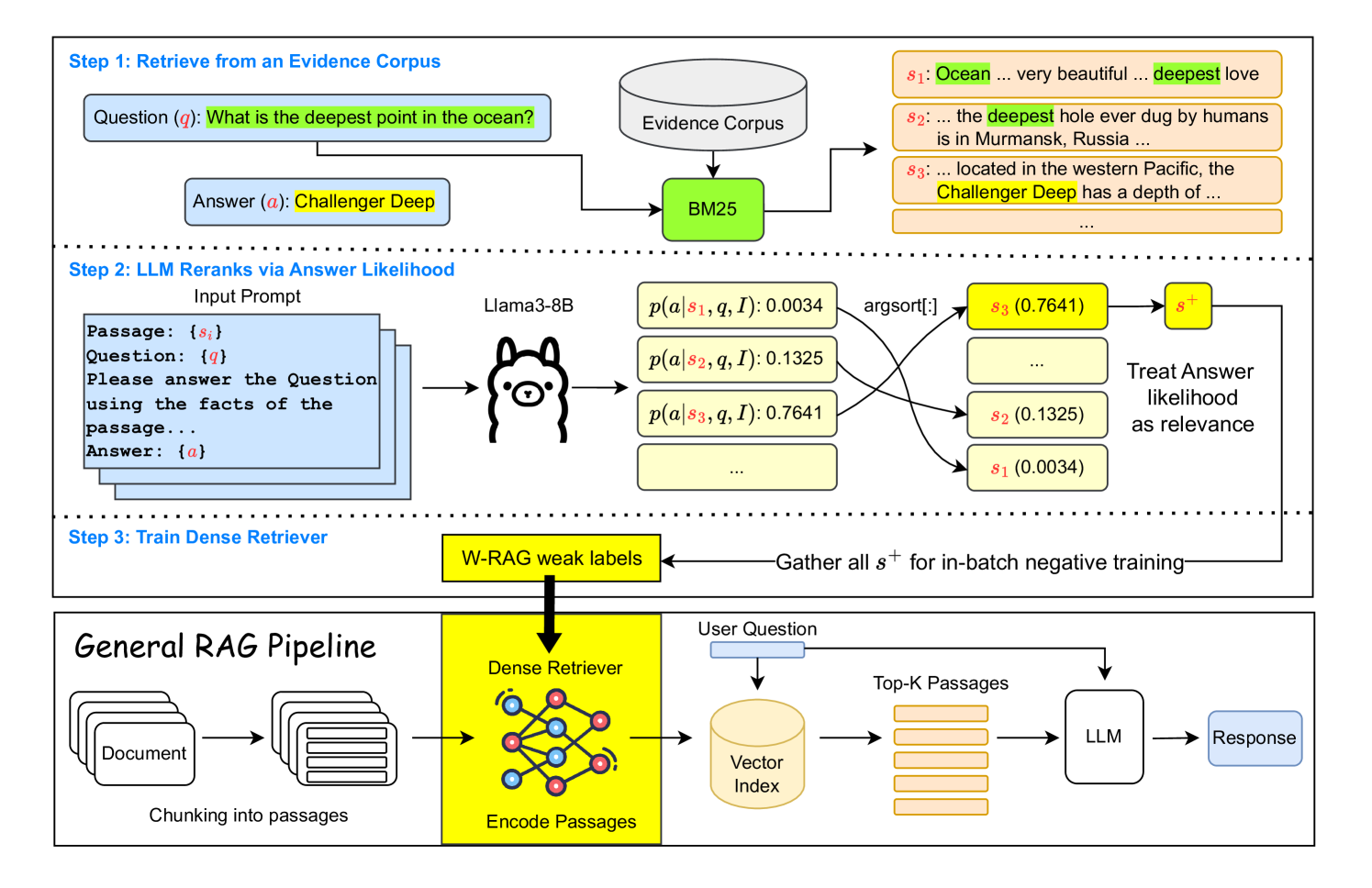
In knowledge-intensive tasks such as open-domain question answering (OpenQA), Large Language Models (LLMs) often struggle to generate factual answers relying solely on their internal (parametric) knowledge. To address this limitation, Retrieval-Augmented Generation (RAG) systems enhance LLMs by retrieving relevant information from external sources, thereby positioning the retriever as a pivotal component. Although dense retrieval demonstrates state-of-the-art performance, its training poses challenges due to the scarcity of ground-truth evidence, largely attributed to the high costs of human annotation. In this paper, we propose W-RAG by utilizing the ranking capabilities of LLMs to create weakly labeled data for training dense retrievers. Specifically, we rerank the top-$K$ passages retrieved via BM25 by assessing the probability that LLMs will generate the correct answer based on the question and each passage. The highest-ranking passages are then used as positive training examples for dense retrieval. Our comprehensive experiments across four publicly available OpenQA datasets demonstrate that our approach enhances both retrieval and OpenQA performance compared to baseline models.
Read more8/19/2024
0
DR-RAG: Applying Dynamic Document Relevance to Retrieval-Augmented Generation for Question-Answering
Zijian Hei, Weiling Liu, Wenjie Ou, Juyi Qiao, Junming Jiao, Guowen Song, Ting Tian, Yi Lin
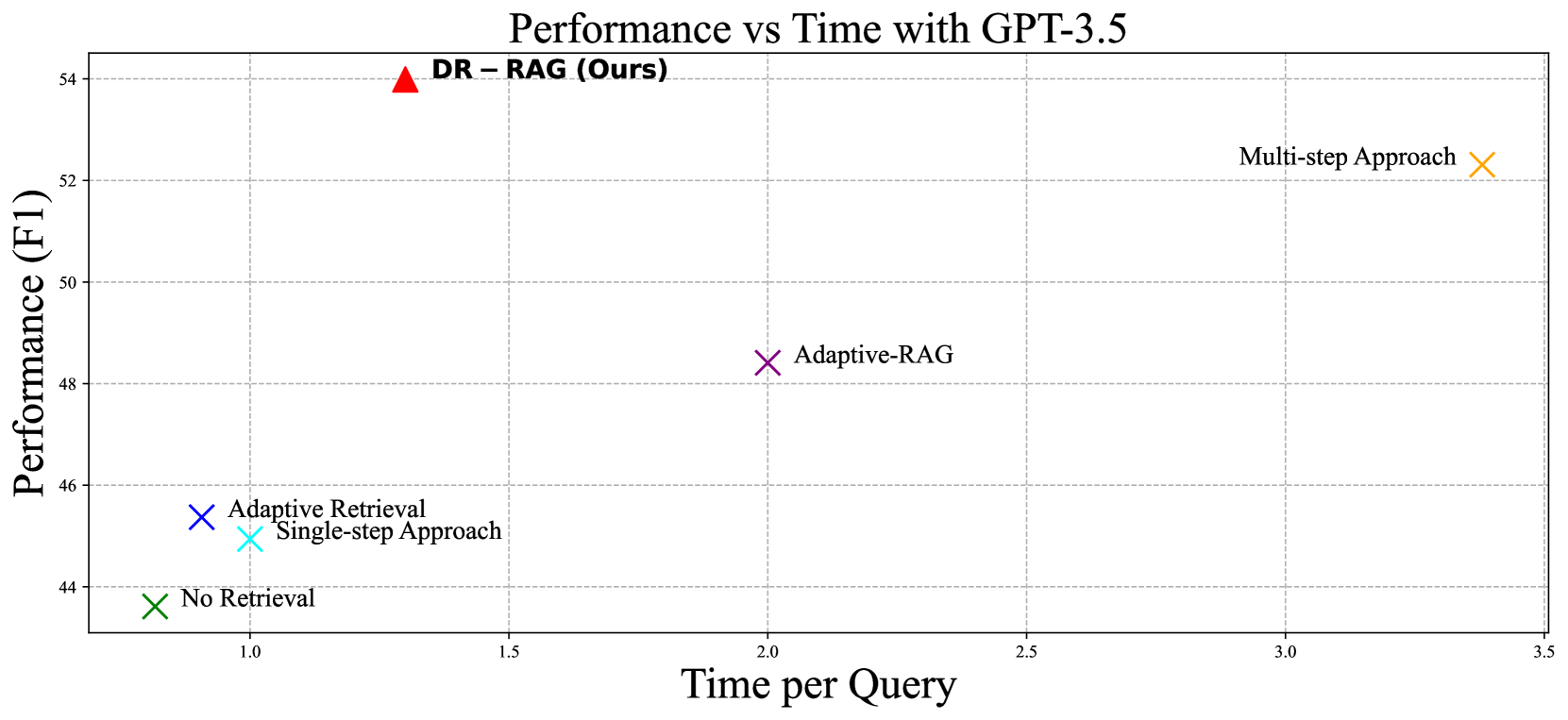
Retrieval-Augmented Generation (RAG) has recently demonstrated the performance of Large Language Models (LLMs) in the knowledge-intensive tasks such as Question-Answering (QA). RAG expands the query context by incorporating external knowledge bases to enhance the response accuracy. However, it would be inefficient to access LLMs multiple times for each query and unreliable to retrieve all the relevant documents by a single query. We have found that even though there is low relevance between some critical documents and query, it is possible to retrieve the remaining documents by combining parts of the documents with the query. To mine the relevance, a two-stage retrieval framework called Dynamic-Relevant Retrieval-Augmented Generation (DR-RAG) is proposed to improve document retrieval recall and the accuracy of answers while maintaining efficiency. Additionally, a compact classifier is applied to two different selection strategies to determine the contribution of the retrieved documents to answering the query and retrieve the relatively relevant documents. Meanwhile, DR-RAG call the LLMs only once, which significantly improves the efficiency of the experiment. The experimental results on multi-hop QA datasets show that DR-RAG can significantly improve the accuracy of the answers and achieve new progress in QA systems.
Read more6/18/2024
0
Blended RAG: Improving RAG (Retriever-Augmented Generation) Accuracy with Semantic Search and Hybrid Query-Based Retrievers
Kunal Sawarkar, Abhilasha Mangal, Shivam Raj Solanki
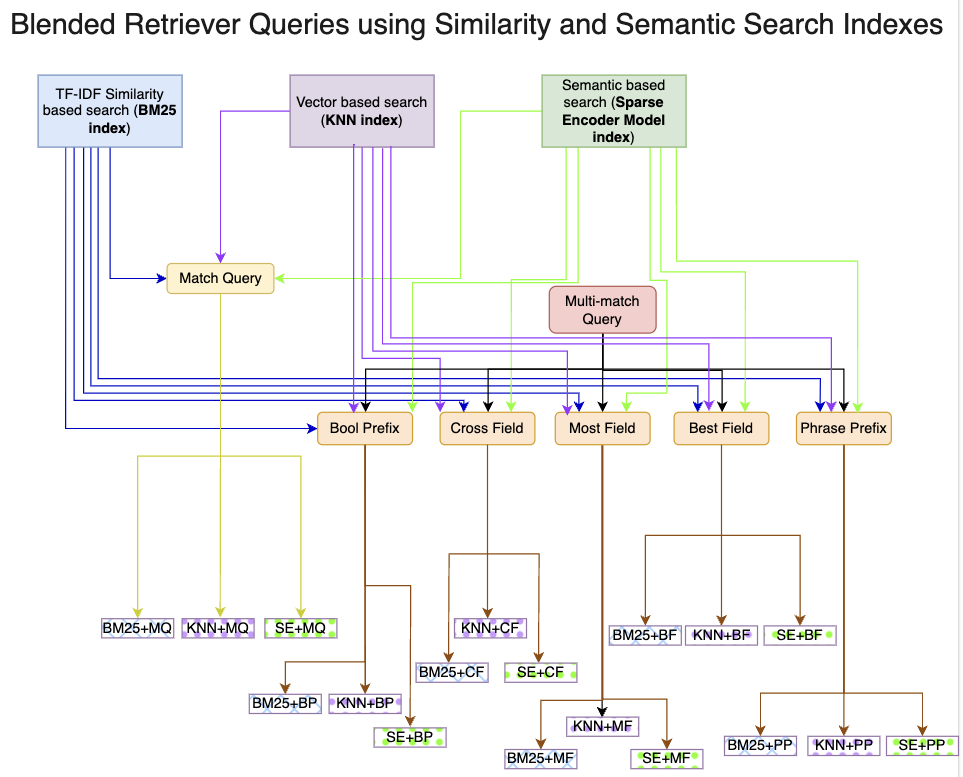
Retrieval-Augmented Generation (RAG) is a prevalent approach to infuse a private knowledge base of documents with Large Language Models (LLM) to build Generative Q&A (Question-Answering) systems. However, RAG accuracy becomes increasingly challenging as the corpus of documents scales up, with Retrievers playing an outsized role in the overall RAG accuracy by extracting the most relevant document from the corpus to provide context to the LLM. In this paper, we propose the 'Blended RAG' method of leveraging semantic search techniques, such as Dense Vector indexes and Sparse Encoder indexes, blended with hybrid query strategies. Our study achieves better retrieval results and sets new benchmarks for IR (Information Retrieval) datasets like NQ and TREC-COVID datasets. We further extend such a 'Blended Retriever' to the RAG system to demonstrate far superior results on Generative Q&A datasets like SQUAD, even surpassing fine-tuning performance.
Read more4/12/2024

0
Augmenting Query and Passage for Retrieval-Augmented Generation using LLMs for Open-Domain Question Answering
Minsang Kim, Cheoneum Park, Seungjun Baek
Retrieval-augmented generation (RAG) has received much attention for Open-domain question-answering (ODQA) tasks as a means to compensate for the parametric knowledge of large language models (LLMs). While previous approaches focused on processing retrieved passages to remove irrelevant context, they still rely heavily on the quality of retrieved passages which can degrade if the question is ambiguous or complex. In this paper, we propose a simple yet efficient method called question and passage augmentation (QPaug) via LLMs for open-domain QA. QPaug first decomposes the original questions into multiple-step sub-questions. By augmenting the original question with detailed sub-questions and planning, we are able to make the query more specific on what needs to be retrieved, improving the retrieval performance. In addition, to compensate for the case where the retrieved passages contain distracting information or divided opinions, we augment the retrieved passages with self-generated passages by LLMs to guide the answer extraction. Experimental results show that QPaug outperforms the previous state-of-the-art and achieves significant performance gain over existing RAG methods. The source code is available at url{https://github.com/kmswin1/QPaug}.
Read more9/30/2024