Advancing High Resolution Vision-Language Models in Biomedicine

0
Sign in to get full access
Overview
- This research paper explores ways to improve high-resolution vision-language models for use in the biomedical domain.
- The key focus is on enhancing the perception and understanding of biomedical images by leveraging higher resolutions.
- The paper examines different approaches to incorporate higher resolutions into vision-language models and evaluates their impact on tasks like medical report generation.
- It also discusses the potential benefits of these advancements for clinical applications and the diagnostic capabilities of AI systems in the medical field.
Plain English Explanation
Imagine you're a doctor trying to diagnose a patient's condition by looking at medical images, like X-rays or MRI scans. The more detailed and high-quality the images, the better you can see and understand what's going on. The same is true for AI systems that are trained to analyze these kinds of biomedical images.
This research paper looks at ways to make the AI models that work with medical images even better at understanding what they're seeing. The researchers explore techniques to give these models access to higher-resolution images, which can provide more detailed information. By improving the "vision" capabilities of these AI systems, the researchers hope to enhance their ability to generate accurate and helpful medical reports, which could ultimately lead to better patient outcomes.
For example, a higher-resolution vision-language model could more clearly identify subtle abnormalities in an X-ray that might be missed by a lower-resolution model, potentially allowing for earlier detection of a condition. Or a more advanced AI system could generate more detailed and informative reports to assist doctors in making diagnoses and treatment decisions.
The researchers in this paper are trying to push the boundaries of what's possible with these AI models, with the ultimate goal of creating tools that can better support medical professionals and improve healthcare for everyone.
Technical Explanation
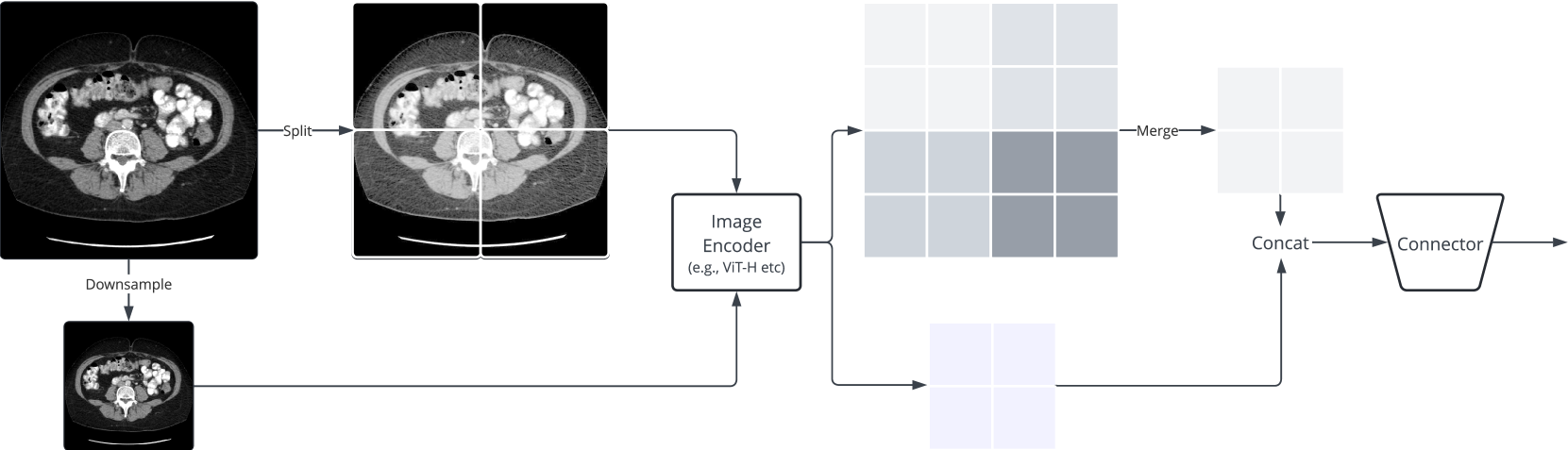
The paper explores ways to incorporate higher resolutions into vision-language models for biomedical applications. The researchers investigate different approaches, such as using specialized fusion techniques to combine high-resolution image data with language information and leveraging large-scale multimodal language models to enhance the understanding of medical images.
The researchers evaluate the performance of these enhanced vision-language models on tasks like medical report generation, where the models are asked to generate written summaries and descriptions of biomedical images. By comparing the outputs of models trained with higher-resolution inputs to those using lower-resolution inputs, the researchers are able to assess the benefits of the higher-resolution approach.
The paper also discusses the potential applications of these advancements, such as improving the diagnostic capabilities of AI systems in the medical field and supporting clinical decision-making by providing more detailed and informative medical reports.
Critical Analysis
While the research presented in the paper shows promising results in enhancing the performance of vision-language models for biomedical applications, the authors acknowledge that there are still some limitations and areas for further exploration.
One potential concern is the computational and storage requirements of using higher-resolution images, which could make these models more challenging to deploy in real-world clinical settings with limited resources. The researchers suggest that future work should investigate more efficient model architectures or compression techniques to address this issue.
Additionally, the paper focuses primarily on evaluating the models' performance on synthetic or controlled datasets, and the researchers note that further testing on more diverse and realistic medical datasets would be valuable to assess the models' robustness and generalization capabilities.
Overall, the research presented in this paper represents an important step forward in the development of high-resolution vision-language models for biomedical applications. However, continued advancements and thorough real-world testing will be necessary to fully realize the potential benefits of these technologies for improving medical diagnosis and patient care.
Conclusion
This research paper explores innovative approaches to enhancing high-resolution vision-language models for use in the biomedical domain. By incorporating higher-resolution image data, the researchers aim to improve the perception and understanding of biomedical images, which could lead to more accurate and informative medical reports.
The potential benefits of these advancements include better support for clinical decision-making, improved diagnostic capabilities of AI systems, and ultimately, more effective patient care. While the research presented in this paper is promising, continued development and real-world testing will be necessary to fully realize the potential of these technologies in the medical field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Advancing High Resolution Vision-Language Models in Biomedicine
Zekai Chen, Arda Pekis, Kevin Brown
Multi-modal learning has significantly advanced generative AI, especially in vision-language modeling. Innovations like GPT-4V and open-source projects such as LLaVA have enabled robust conversational agents capable of zero-shot task completions. However, applying these technologies in the biomedical field presents unique challenges. Recent initiatives like LLaVA-Med have started to adapt instruction-tuning for biomedical contexts using large datasets such as PMC-15M. Our research offers three key contributions: (i) we present a new instruct dataset enriched with medical image-text pairs from Claude3-Opus and LLaMA3 70B, (ii) we propose a novel image encoding strategy using hierarchical representations to improve fine-grained biomedical visual comprehension, and (iii) we develop the Llama3-Med model, which achieves state-of-the-art zero-shot performance on biomedical visual question answering benchmarks, with an average performance improvement of over 10% compared to previous methods. These advancements provide more accurate and reliable tools for medical professionals, bridging gaps in current multi-modal conversational assistants and promoting further innovations in medical AI.
Read more6/17/2024
0
A Survey for Large Language Models in Biomedicine
Chong Wang, Mengyao Li, Junjun He, Zhongruo Wang, Erfan Darzi, Zan Chen, Jin Ye, Tianbin Li, Yanzhou Su, Jing Ke, Kaili Qu, Shuxin Li, Yi Yu, Pietro Li`o, Tianyun Wang, Yu Guang Wang, Yiqing Shen
Recent breakthroughs in large language models (LLMs) offer unprecedented natural language understanding and generation capabilities. However, existing surveys on LLMs in biomedicine often focus on specific applications or model architectures, lacking a comprehensive analysis that integrates the latest advancements across various biomedical domains. This review, based on an analysis of 484 publications sourced from databases including PubMed, Web of Science, and arXiv, provides an in-depth examination of the current landscape, applications, challenges, and prospects of LLMs in biomedicine, distinguishing itself by focusing on the practical implications of these models in real-world biomedical contexts. Firstly, we explore the capabilities of LLMs in zero-shot learning across a broad spectrum of biomedical tasks, including diagnostic assistance, drug discovery, and personalized medicine, among others, with insights drawn from 137 key studies. Then, we discuss adaptation strategies of LLMs, including fine-tuning methods for both uni-modal and multi-modal LLMs to enhance their performance in specialized biomedical contexts where zero-shot fails to achieve, such as medical question answering and efficient processing of biomedical literature. Finally, we discuss the challenges that LLMs face in the biomedicine domain including data privacy concerns, limited model interpretability, issues with dataset quality, and ethics due to the sensitive nature of biomedical data, the need for highly reliable model outputs, and the ethical implications of deploying AI in healthcare. To address these challenges, we also identify future research directions of LLM in biomedicine including federated learning methods to preserve data privacy and integrating explainable AI methodologies to enhance the transparency of LLMs.
Read more9/4/2024

0
HuatuoGPT-Vision, Towards Injecting Medical Visual Knowledge into Multimodal LLMs at Scale
Junying Chen, Chi Gui, Ruyi Ouyang, Anningzhe Gao, Shunian Chen, Guiming Hardy Chen, Xidong Wang, Ruifei Zhang, Zhenyang Cai, Ke Ji, Guangjun Yu, Xiang Wan, Benyou Wang
The rapid development of multimodal large language models (MLLMs), such as GPT-4V, has led to significant advancements. However, these models still face challenges in medical multimodal capabilities due to limitations in the quantity and quality of medical vision-text data, stemming from data privacy concerns and high annotation costs. While pioneering approaches utilize PubMed's large-scale, de-identified medical image-text pairs to address these limitations, they still fall short due to inherent data noise. To tackle this, we refined medical image-text pairs from PubMed and employed MLLMs (GPT-4V) in an 'unblinded' capacity to denoise and reformat the data, resulting in the creation of the PubMedVision dataset with 1.3 million medical VQA samples. Our validation demonstrates that: (1) PubMedVision can significantly enhance the medical multimodal capabilities of current MLLMs, showing significant improvement in benchmarks including the MMMU Health & Medicine track; (2) manual checks by medical experts and empirical results validate the superior data quality of our dataset compared to other data construction methods. Using PubMedVision, we train a 34B medical MLLM HuatuoGPT-Vision, which shows superior performance in medical multimodal scenarios among open-source MLLMs.
Read more9/26/2024

0
Beyond the Hype: A dispassionate look at vision-language models in medical scenario
Yang Nan, Huichi Zhou, Xiaodan Xing, Guang Yang
Recent advancements in Large Vision-Language Models (LVLMs) have demonstrated remarkable capabilities across diverse tasks, garnering significant attention in AI communities. However, their performance and reliability in specialized domains such as medicine remain insufficiently assessed. In particular, most assessments over-concentrate in evaluating VLMs based on simple Visual Question Answering (VQA) on multi-modality data, while ignoring the in-depth characteristic of LVLMs. In this study, we introduce RadVUQA, a novel Radiological Visual Understanding and Question Answering benchmark, to comprehensively evaluate existing LVLMs. RadVUQA mainly validates LVLMs across five dimensions: 1) Anatomical understanding, assessing the models' ability to visually identify biological structures; 2) Multimodal comprehension, which involves the capability of interpreting linguistic and visual instructions to produce desired outcomes; 3) Quantitative and spatial reasoning, evaluating the models' spatial awareness and proficiency in combining quantitative analysis with visual and linguistic information; 4) Physiological knowledge, measuring the models' capability to comprehend functions and mechanisms of organs and systems; and 5) Robustness, which assesses the models' capabilities against unharmonised and synthetic data. The results indicate that both generalized LVLMs and medical-specific LVLMs have critical deficiencies with weak multimodal comprehension and quantitative reasoning capabilities. Our findings reveal the large gap between existing LVLMs and clinicians, highlighting the urgent need for more robust and intelligent LVLMs. The code and dataset will be available after the acceptance of this paper.
Read more8/19/2024