GeONet: a neural operator for learning the Wasserstein geodesic

0
🧠
Sign in to get full access
Overview
- The paper introduces GeONet, a deep neural network that can efficiently compute the Wasserstein geodesic between two probability distributions.
- Traditional methods for computing the Wasserstein distance and geodesic suffer from high computational cost and the curse of dimensionality.
- GeONet learns the non-linear mapping from input distributions to the Wasserstein geodesic, enabling fast and accurate predictions.
Plain English Explanation
The paper presents a new deep learning model called GeONet that can quickly and accurately compute the Wasserstein distance and geodesic between two probability distributions. The Wasserstein distance is a way to quantify how different two data distributions are, and the Wasserstein geodesic is the "shortest path" connecting those distributions.
Traditional methods for calculating the Wasserstein distance and geodesic can be very slow, especially as the dimensionality of the data increases. GeONet solves this problem by using a neural network to learn the relationship between the input distributions and the Wasserstein geodesic. During an offline training phase, GeONet learns the mathematical conditions that define the optimal transport problem. Then, during the fast online inference stage, GeONet can instantly predict the Wasserstein geodesic for new data pairs.
The key innovation of GeONet is that it is "mesh-invariant," meaning it can work with different types of data representations without requiring a specific discretization of the domain. This makes it more flexible and versatile compared to previous methods. The paper demonstrates that GeONet can achieve accuracy comparable to standard optimal transport solvers, but with orders of magnitude faster inference times.
Technical Explanation
The paper introduces a deep learning model called GeONet that can efficiently compute the Wasserstein geodesic between two probability distributions. Traditional methods for computing the Wasserstein distance and geodesic require mesh-specific domain discretization and suffer from the curse of dimensionality, limiting their scalability and practicality.
GeONet is designed to be mesh-invariant, learning a non-linear mapping from the input pair of initial and terminal distributions to the Wasserstein geodesic connecting them. During an offline training stage, GeONet learns the saddle point optimality conditions that characterize the dynamic formulation of the optimal transport problem in both the primal and dual spaces. This knowledge is encoded in a coupled PDE system that the neural network learns to approximate.
At inference time, GeONet can instantly predict the Wasserstein geodesic for new data pairs, orders of magnitude faster than standard optimal transport solvers. The paper demonstrates that GeONet achieves comparable testing accuracy to traditional methods on simulation examples and the MNIST dataset, while providing substantial computational savings.
Critical Analysis
The paper presents an innovative approach to efficient Wasserstein distance and geodesic computation using deep learning. The key strengths of the GeONet model include its mesh-invariance, which allows it to work with diverse data representations, and its ability to achieve high accuracy with drastically reduced inference times compared to traditional optimal transport solvers.
However, the paper does not extensively explore the limitations of the GeONet approach. For example, it is unclear how well the model would scale to very high-dimensional data or if there are any restrictions on the types of probability distributions it can handle. Additionally, the paper does not address potential issues with the stability or robustness of the neural network predictions, which could be important in real-world applications.
Further research could investigate the generalization capabilities of GeONet, its sensitivity to hyperparameter choices, and its performance on a broader range of datasets and tasks. Exploring ways to further accelerate the inference stage or develop even more efficient neural network architectures could also be fruitful avenues for future work.
Conclusion
The GeONet model presented in this paper offers a promising approach to efficiently computing Wasserstein distances and geodesics, a fundamental problem in optimal transport theory with numerous applications in machine learning and data analysis. By leveraging deep learning, GeONet can provide accurate predictions orders of magnitude faster than traditional solvers, making it a compelling tool for real-time or large-scale tasks.
While the paper demonstrates the effectiveness of the GeONet model on several benchmarks, further research is needed to fully understand its limitations and explore opportunities for improvement. Nonetheless, this work represents an important step forward in the development of scalable and practical optimal transport methods, with the potential to unlock new possibilities in a wide range of data-driven domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🧠
0
GeONet: a neural operator for learning the Wasserstein geodesic
Andrew Gracyk, Xiaohui Chen
Optimal transport (OT) offers a versatile framework to compare complex data distributions in a geometrically meaningful way. Traditional methods for computing the Wasserstein distance and geodesic between probability measures require mesh-specific domain discretization and suffer from the curse-of-dimensionality. We present GeONet, a mesh-invariant deep neural operator network that learns the non-linear mapping from the input pair of initial and terminal distributions to the Wasserstein geodesic connecting the two endpoint distributions. In the offline training stage, GeONet learns the saddle point optimality conditions for the dynamic formulation of the OT problem in the primal and dual spaces that are characterized by a coupled PDE system. The subsequent inference stage is instantaneous and can be deployed for real-time predictions in the online learning setting. We demonstrate that GeONet achieves comparable testing accuracy to the standard OT solvers on simulation examples and the MNIST dataset with considerably reduced inference-stage computational cost by orders of magnitude.
Read more5/24/2024
0
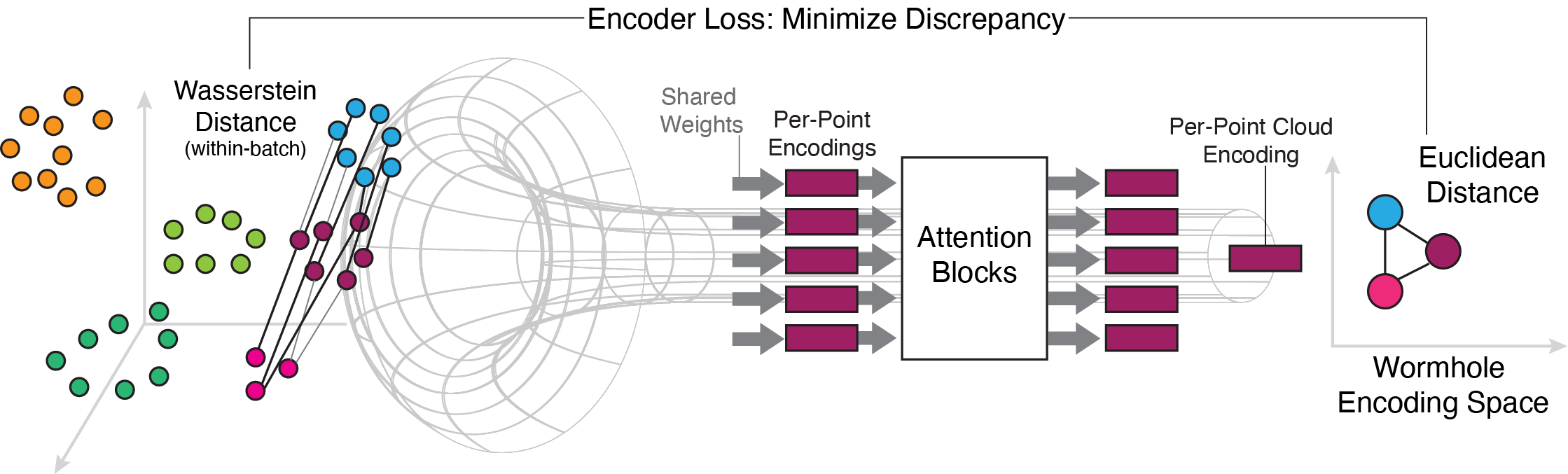
Wasserstein Wormhole: Scalable Optimal Transport Distance with Transformers
Doron Haviv, Russell Zhang Kunes, Thomas Dougherty, Cassandra Burdziak, Tal Nawy, Anna Gilbert, Dana Pe'er
Optimal transport (OT) and the related Wasserstein metric (W) are powerful and ubiquitous tools for comparing distributions. However, computing pairwise Wasserstein distances rapidly becomes intractable as cohort size grows. An attractive alternative would be to find an embedding space in which pairwise Euclidean distances map to OT distances, akin to standard multidimensional scaling (MDS). We present Wasserstein Wormhole, a transformer-based autoencoder that embeds empirical distributions into a latent space wherein Euclidean distances approximate OT distances. Extending MDS theory, we show that our objective function implies a bound on the error incurred when embedding non-Euclidean distances. Empirically, distances between Wormhole embeddings closely match Wasserstein distances, enabling linear time computation of OT distances. Along with an encoder that maps distributions to embeddings, Wasserstein Wormhole includes a decoder that maps embeddings back to distributions, allowing for operations in the embedding space to generalize to OT spaces, such as Wasserstein barycenter estimation and OT interpolation. By lending scalability and interpretability to OT approaches, Wasserstein Wormhole unlocks new avenues for data analysis in the fields of computational geometry and single-cell biology.
Read more6/5/2024

0
Strongly Isomorphic Neural Optimal Transport Across Incomparable Spaces
Athina Sotiropoulou, David Alvarez-Melis
Optimal Transport (OT) has recently emerged as a powerful framework for learning minimal-displacement maps between distributions. The predominant approach involves a neural parametrization of the Monge formulation of OT, typically assuming the same space for both distributions. However, the setting across ``incomparable spaces'' (e.g., of different dimensionality), corresponding to the Gromov- Wasserstein distance, remains underexplored, with existing methods often imposing restrictive assumptions on the cost function. In this paper, we present a novel neural formulation of the Gromov-Monge (GM) problem rooted in one of its fundamental properties: invariance to strong isomorphisms. We operationalize this property by decomposing the learnable OT map into two components: (i) an approximate strong isomorphism between the source distribution and an intermediate reference distribution, and (ii) a GM-optimal map between this reference and the target distribution. Our formulation leverages and extends the Monge gap regularizer of Uscidda & Cuturi (2023) to eliminate the need for complex architectural requirements of other neural OT methods, yielding a simple but practical method that enjoys favorable theoretical guarantees. Our preliminary empirical results show that our framework provides a promising approach to learn OT maps across diverse spaces.
Read more7/23/2024
🌿
0
New!A Riemannian Approach to Ground Metric Learning for Optimal Transport
Pratik Jawanpuria, Dai Shi, Bamdev Mishra, Junbin Gao
Optimal transport (OT) theory has attracted much attention in machine learning and signal processing applications. OT defines a notion of distance between probability distributions of source and target data points. A crucial factor that influences OT-based distances is the ground metric of the embedding space in which the source and target data points lie. In this work, we propose to learn a suitable latent ground metric parameterized by a symmetric positive definite matrix. We use the rich Riemannian geometry of symmetric positive definite matrices to jointly learn the OT distance along with the ground metric. Empirical results illustrate the efficacy of the learned metric in OT-based domain adaptation.
Read more9/17/2024