WDMoE: Wireless Distributed Large Language Models with Mixture of Experts
2405.03131
0
0

Abstract
Large Language Models (LLMs) have achieved significant success in various natural language processing tasks, but how wireless communications can support LLMs has not been extensively studied. In this paper, we propose a wireless distributed LLMs paradigm based on Mixture of Experts (MoE), named WDMoE, deploying LLMs collaboratively across edge servers of base station (BS) and mobile devices in the wireless communications system. Specifically, we decompose the MoE layer in LLMs by deploying the gating network and the preceding neural network layer at BS, while distributing the expert networks across the devices. This arrangement leverages the parallel capabilities of expert networks on distributed devices. Moreover, to overcome the instability of wireless communications, we design an expert selection policy by taking into account both the performance of the model and the end-to-end latency, which includes both transmission delay and inference delay. Evaluations conducted across various LLMs and multiple datasets demonstrate that WDMoE not only outperforms existing models, such as Llama 2 with 70 billion parameters, but also significantly reduces end-to-end latency.
Create account to get full access
Overview
- This paper introduces WDMoE, a framework for distributing large language models using a wireless Mixture of Experts (MoE) architecture.
- WDMoE aims to improve the efficiency and flexibility of large language models by partitioning the model into specialized "experts" that can be selectively activated based on the input.
- The wireless communication aspect allows for dynamic routing of inputs to the most appropriate experts, which can help reduce the computational burden on individual devices.
Plain English Explanation
The researchers have developed a new way to run large, powerful language models like GPT-3 or BERT on multiple devices at once. They call this system WDMoE, which stands for "Wireless Distributed Mixture of Experts."
The key idea is to break up the language model into smaller, specialized "expert" components. Each expert is trained to handle a particular type of input or task really well. When you give the system some text to analyze, it can quickly figure out which expert(s) are best suited for that input and route it to them over a wireless network.
This distributed approach has a few benefits:
- Efficiency: By only activating the relevant experts, you can reduce the overall computational load and power consumption, which is important for running these models on mobile devices or in the cloud.
- Flexibility: The system can dynamically adjust which experts are used based on the input, allowing it to be more adaptable than a one-size-fits-all language model.
- Scalability: As the language model grows larger and more complex, the WDMoE framework makes it easier to scale by adding more expert components rather than trying to cram everything into a single monolithic model.
The wireless communication aspect is also a key part of the innovation. It allows the system to quickly route inputs to the best-suited experts, no matter where they are located. This could enable new applications where language models need to be distributed across multiple devices or servers.
Technical Explanation
The core of the WDMoE framework is a Mixture of Experts (MoE) architecture, where the large language model is divided into a collection of smaller "expert" sub-models. Each expert is trained to specialize in a particular type of input or task.
When a new input is received, a gating network dynamically selects which experts should be activated to process that input. This allows the system to efficiently focus computational resources on the most relevant parts of the model.
To enable flexible, distributed deployment, WDMoE incorporates wireless communication between the experts and the gating network. The inputs can be routed to the appropriate experts over the wireless channel, rather than requiring everything to be centralized.
The researchers also introduce a specialized algorithm and system co-design to optimize the expert selection process and wireless transmission, further improving the efficiency and latency of the WDMoE framework.
Critical Analysis
The WDMoE framework addresses some important challenges in deploying large language models in real-world, distributed settings. By partitioning the model and allowing dynamic expert selection, it can help reduce the computational and energy requirements compared to running a monolithic model.
However, the paper does not delve into the potential downsides or limitations of this approach. For example, there may be tradeoffs in terms of model performance or accuracy when relying on a mixture of experts instead of a single, unified model. The overhead of the wireless communication and expert selection process could also introduce latency that may be unacceptable for some applications.
Additionally, the paper focuses mainly on the architectural and algorithmic innovations, but does not provide a thorough analysis of the real-world implications or potential societal impacts of deploying such a distributed language model system. Further research would be needed to understand the broader consequences, both positive and negative.
Conclusion
The WDMoE framework represents an interesting advance in the field of large language model deployment, combining a Mixture of Experts architecture with wireless communication to enable more efficient and flexible distribution of these powerful AI systems.
By selectively activating the most relevant model components for each input, WDMoE has the potential to reduce the computational burden and energy consumption of running large language models, which could open up new use cases on resource-constrained devices or in edge computing environments.
However, the paper leaves room for further investigation into the practical tradeoffs and broader implications of this approach. Continued research and thoughtful deployment will be necessary to ensure that distributed language models like WDMoE are developed and used responsibly to benefit society.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
LocMoE: A Low-Overhead MoE for Large Language Model Training
Jing Li, Zhijie Sun, Xuan He, Li Zeng, Yi Lin, Entong Li, Binfan Zheng, Rongqian Zhao, Xin Chen
0
0
The Mixtures-of-Experts (MoE) model is a widespread distributed and integrated learning method for large language models (LLM), which is favored due to its ability to sparsify and expand models efficiently. However, the performance of MoE is limited by load imbalance and high latency of All-to-All communication, along with relatively redundant computation owing to large expert capacity. Load imbalance may result from existing routing policies that consistently tend to select certain experts. The frequent inter-node communication in the All-to-All procedure also significantly prolongs the training time. To alleviate the above performance problems, we propose a novel routing strategy that combines load balance and locality by converting partial inter-node communication to that of intra-node. Notably, we elucidate that there is a minimum threshold for expert capacity, calculated through the maximal angular deviation between the gating weights of the experts and the assigned tokens. We port these modifications on the PanGu-Sigma model based on the MindSpore framework with multi-level routing and conduct experiments on Ascend clusters. The experiment results demonstrate that the proposed LocMoE reduces training time per epoch by 12.68% to 22.24% compared to classical routers, such as hash router and switch router, without impacting the model accuracy.
5/24/2024

A Closer Look into Mixture-of-Experts in Large Language Models
Ka Man Lo, Zeyu Huang, Zihan Qiu, Zili Wang, Jie Fu
0
0
Mixture-of-experts (MoE) is gaining increasing attention due to its unique properties and remarkable performance, especially for language tasks. By sparsely activating a subset of parameters for each token, MoE architecture could increase the model size without sacrificing computational efficiency, achieving a better trade-off between performance and training costs. However, the underlying mechanism of MoE still lacks further exploration, and its modularization degree remains questionable. In this paper, we make an initial attempt to understand the inner workings of MoE-based large language models. Concretely, we comprehensively study the parametric and behavioral features of three recent MoE-based models and reveal some intriguing observations, including (1) Neurons act like fine-grained experts. (2) The router of MoE usually selects experts with larger output norms. (3) The expert diversity increases as the layer increases, while the last layer is an outlier. Based on the observations, we also provide suggestions for a broad spectrum of MoE practitioners, such as router design and expert allocation. We hope this work could shed light on future research on the MoE framework and other modular architectures. Code is available at https://github.com/kamanphoebe/Look-into-MoEs.
6/27/2024
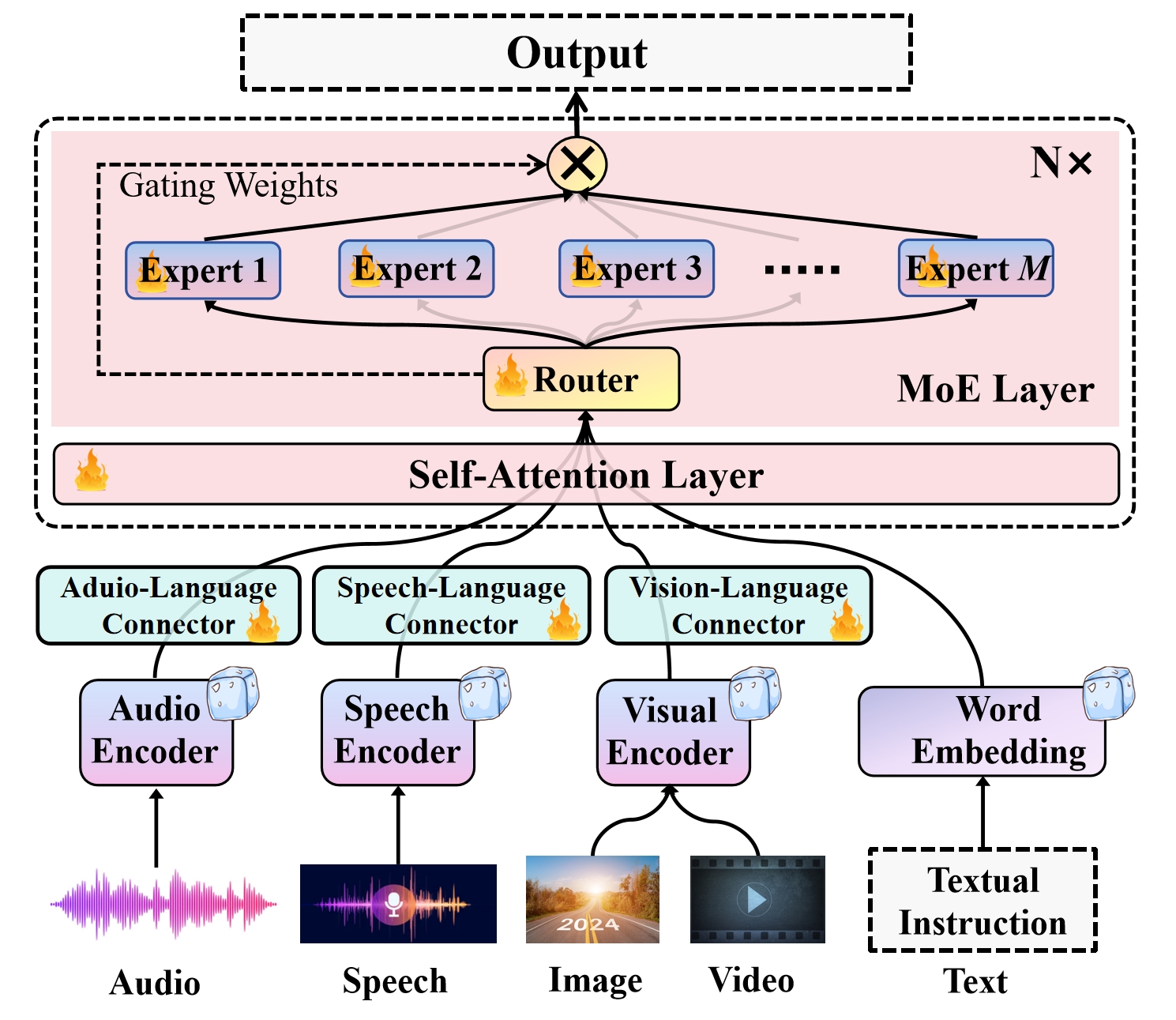
Uni-MoE: Scaling Unified Multimodal LLMs with Mixture of Experts
Yunxin Li, Shenyuan Jiang, Baotian Hu, Longyue Wang, Wanqi Zhong, Wenhan Luo, Lin Ma, Min Zhang
0
0
Recent advancements in Multimodal Large Language Models (MLLMs) underscore the significance of scalable models and data to boost performance, yet this often incurs substantial computational costs. Although the Mixture of Experts (MoE) architecture has been employed to efficiently scale large language and image-text models, these efforts typically involve fewer experts and limited modalities. To address this, our work presents the pioneering attempt to develop a unified MLLM with the MoE architecture, named Uni-MoE that can handle a wide array of modalities. Specifically, it features modality-specific encoders with connectors for a unified multimodal representation. We also implement a sparse MoE architecture within the LLMs to enable efficient training and inference through modality-level data parallelism and expert-level model parallelism. To enhance the multi-expert collaboration and generalization, we present a progressive training strategy: 1) Cross-modality alignment using various connectors with different cross-modality data, 2) Training modality-specific experts with cross-modality instruction data to activate experts' preferences, and 3) Tuning the Uni-MoE framework utilizing Low-Rank Adaptation (LoRA) on mixed multimodal instruction data. We evaluate the instruction-tuned Uni-MoE on a comprehensive set of multimodal datasets. The extensive experimental results demonstrate Uni-MoE's principal advantage of significantly reducing performance bias in handling mixed multimodal datasets, alongside improved multi-expert collaboration and generalization. Our findings highlight the substantial potential of MoE frameworks in advancing MLLMs and the code is available at https://github.com/HITsz-TMG/UMOE-Scaling-Unified-Multimodal-LLMs.
5/21/2024
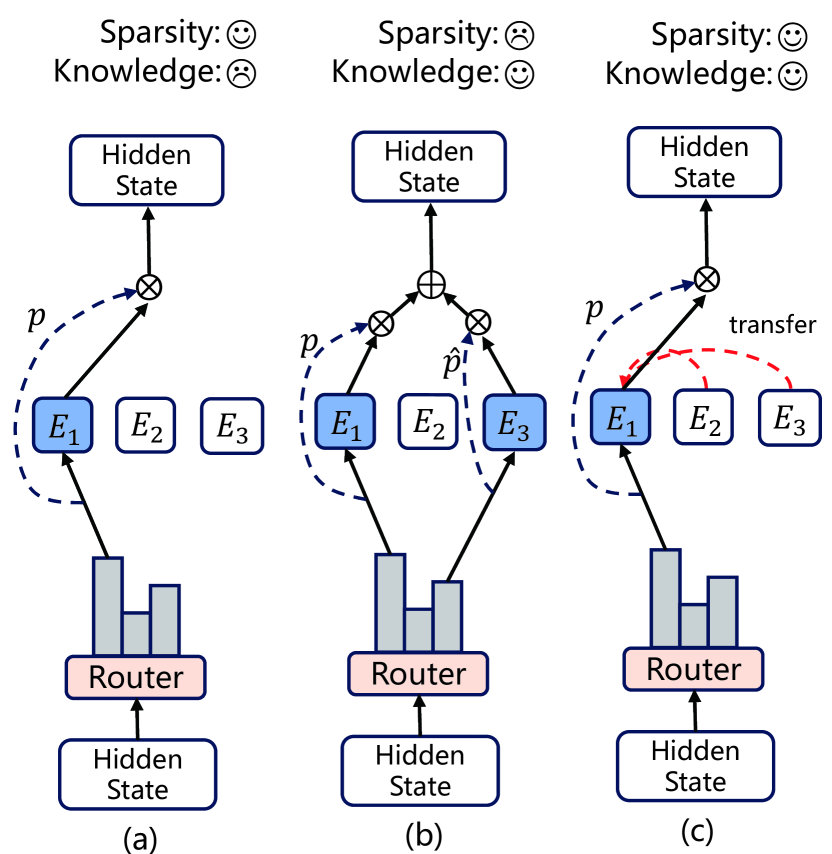
HyperMoE: Towards Better Mixture of Experts via Transferring Among Experts
Hao Zhao, Zihan Qiu, Huijia Wu, Zili Wang, Zhaofeng He, Jie Fu
0
0
The Mixture of Experts (MoE) for language models has been proven effective in augmenting the capacity of models by dynamically routing each input token to a specific subset of experts for processing. Despite the success, most existing methods face a challenge for balance between sparsity and the availability of expert knowledge: enhancing performance through increased use of expert knowledge often results in diminishing sparsity during expert selection. To mitigate this contradiction, we propose HyperMoE, a novel MoE framework built upon Hypernetworks. This framework integrates the computational processes of MoE with the concept of knowledge transferring in multi-task learning. Specific modules generated based on the information of unselected experts serve as supplementary information, which allows the knowledge of experts not selected to be used while maintaining selection sparsity. Our comprehensive empirical evaluations across multiple datasets and backbones establish that HyperMoE significantly outperforms existing MoE methods under identical conditions concerning the number of experts.
5/22/2024