Weighted KL-Divergence for Document Ranking Model Refinement

0

Sign in to get full access
Overview
- This paper proposes a novel document ranking model refinement technique using weighted KL-divergence.
- It explores how to effectively leverage the knowledge distilled from a large, complex teacher model to refine a smaller, more efficient student model for document ranking.
- The method aims to improve the student model's performance while maintaining its efficiency compared to the teacher model.
Plain English Explanation
The paper focuses on a technique to improve the performance of a smaller, more efficient document ranking model. Document ranking is a crucial task in search engines, where the goal is to present the most relevant results to users.
The researchers started with a large, complex "teacher" model that was good at ranking documents. They then used a knowledge distillation technique to transfer the knowledge from the teacher model to a smaller, more efficient "student" model. Knowledge distillation is a way to compress the knowledge of a large, powerful model into a smaller, simpler one, while preserving its key capabilities.
The key innovation in this paper is the use of weighted KL-divergence to guide the knowledge distillation process. KL-divergence is a way to measure the difference between two probability distributions, in this case, the output of the teacher model and the output of the student model. By weighting the KL-divergence, the researchers were able to focus the student model's learning on the most important aspects of the ranking task, improving its performance without sacrificing efficiency.
This approach allows the smaller student model to benefit from the knowledge of the larger teacher model, resulting in better document ranking performance compared to training the student model from scratch. The method can be used to refine any document ranking model, making it a valuable tool for improving the quality of search engine results.
Technical Explanation
The paper proposes a weighted KL-divergence based knowledge distillation approach for document ranking model refinement. The key idea is to use the knowledge distilled from a large, complex "teacher" model to improve the performance of a smaller, more efficient "student" model.
The authors first train a large, powerful teacher model for document ranking using standard techniques. They then use knowledge distillation to transfer the knowledge from the teacher model to the student model. The core of the knowledge distillation process is minimizing the KL-divergence between the output distributions of the teacher and student models.
The key innovation in this paper is the introduction of weighted KL-divergence, where the KL-divergence is weighted based on the relative importance of different document rankings. This allows the student model to focus on learning the most crucial aspects of the ranking task, leading to better performance without sacrificing efficiency.
The authors evaluate their approach on several standard document ranking benchmarks, comparing the performance of the student model refined using weighted KL-divergence to both the teacher model and a student model trained from scratch. The results show that the proposed method can significantly improve the student model's performance, often surpassing the teacher model, while maintaining the student model's efficiency.
Critical Analysis
The paper presents a novel and promising approach for document ranking model refinement using weighted KL-divergence and knowledge distillation. The key strengths of the method include its ability to effectively transfer knowledge from a large teacher model to a smaller student model, and the use of weighted KL-divergence to focus the student model's learning on the most crucial aspects of the ranking task.
One potential limitation of the approach is that the weighting scheme for the KL-divergence may need to be tuned for specific ranking tasks or datasets. The authors acknowledge this and suggest further research into automatic weighting schemes or learning the weights during the distillation process.
Additionally, the paper does not explore the impact of the teacher model's architecture or quality on the effectiveness of the knowledge distillation process. It would be interesting to see how the method performs when using different teacher models, or when the teacher model's performance is not significantly better than the student model's initial performance.
Further research could also investigate the generalization of the weighted KL-divergence approach to other knowledge distillation techniques, such as Generalized Contrastive Learning for Multi-modal Retrieval and Ranking or CKD: Contrastive Knowledge Distillation from Sample-wise Experts. This could further improve the efficiency and effectiveness of document ranking models.
Conclusion
The paper presents a novel document ranking model refinement technique using weighted KL-divergence and knowledge distillation. By effectively transferring knowledge from a large, complex teacher model to a smaller, more efficient student model, the proposed method can significantly improve the student model's performance while maintaining its efficiency.
The key innovation of the weighted KL-divergence approach allows the student model to focus on learning the most crucial aspects of the ranking task, leading to better overall performance. This technique can be a valuable tool for improving the quality of search engine results and other document ranking applications.
The paper's findings suggest that further research into automatic weighting schemes, the impact of teacher model quality, and the generalization of the approach to other knowledge distillation techniques could lead to even more effective document ranking models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Weighted KL-Divergence for Document Ranking Model Refinement
Yingrui Yang, Yifan Qiao, Shanxiu He, Tao Yang
Transformer-based retrieval and reranking models for text document search are often refined through knowledge distillation together with contrastive learning. A tight distribution matching between the teacher and student models can be hard as over-calibration may degrade training effectiveness when a teacher does not perform well. This paper contrastively reweights KL divergence terms to prioritize the alignment between a student and a teacher model for proper separation of positive and negative documents. This paper analyzes and evaluates the proposed loss function on the MS MARCO and BEIR datasets to demonstrate its effectiveness in improving the relevance of tested student models.
Read more6/11/2024
🧠
0
Improving Neural Topic Models with Wasserstein Knowledge Distillation
Suman Adhya, Debarshi Kumar Sanyal
Topic modeling is a dominant method for exploring document collections on the web and in digital libraries. Recent approaches to topic modeling use pretrained contextualized language models and variational autoencoders. However, large neural topic models have a considerable memory footprint. In this paper, we propose a knowledge distillation framework to compress a contextualized topic model without loss in topic quality. In particular, the proposed distillation objective is to minimize the cross-entropy of the soft labels produced by the teacher and the student models, as well as to minimize the squared 2-Wasserstein distance between the latent distributions learned by the two models. Experiments on two publicly available datasets show that the student trained with knowledge distillation achieves topic coherence much higher than that of the original student model, and even surpasses the teacher while containing far fewer parameters than the teacher's. The distilled model also outperforms several other competitive topic models on topic coherence.
Read more6/21/2024
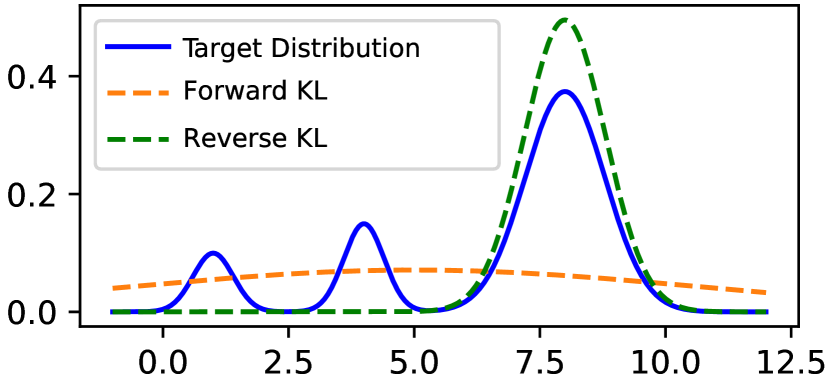
0
Rethinking Kullback-Leibler Divergence in Knowledge Distillation for Large Language Models
Taiqiang Wu, Chaofan Tao, Jiahao Wang, Zhe Zhao, Ngai Wong
Kullback-Leiber divergence has been widely used in Knowledge Distillation (KD) to compress Large Language Models (LLMs). Contrary to prior assertions that reverse Kullback-Leibler (RKL) divergence is mode-seeking and thus preferable over the mean-seeking forward Kullback-Leibler (FKL) divergence, this study empirically and theoretically demonstrates that neither mode-seeking nor mean-seeking properties manifest in KD for LLMs. Instead, RKL and FKL are found to share the same optimization objective and both converge after a sufficient number of epochs. However, due to practical constraints, LLMs are seldom trained for such an extensive number of epochs. Meanwhile, we further find that RKL focuses on the tail part of the distributions, while FKL focuses on the head part at the beginning epochs. Consequently, we propose a simple yet effective Adaptive Kullback-Leiber (AKL) divergence method, which adaptively allocates weights to combine FKL and RKL. Metric-based and GPT-4-based evaluations demonstrate that the proposed AKL outperforms the baselines across various tasks and improves the diversity and quality of generated responses.
Read more6/18/2024

0
Bridging the Gap: Unpacking the Hidden Challenges in Knowledge Distillation for Online Ranking Systems
Nikhil Khani, Shuo Yang, Aniruddh Nath, Yang Liu, Pendo Abbo, Li Wei, Shawn Andrews, Maciej Kula, Jarrod Kahn, Zhe Zhao, Lichan Hong, Ed Chi
Knowledge Distillation (KD) is a powerful approach for compressing a large model into a smaller, more efficient model, particularly beneficial for latency-sensitive applications like recommender systems. However, current KD research predominantly focuses on Computer Vision (CV) and NLP tasks, overlooking unique data characteristics and challenges inherent to recommender systems. This paper addresses these overlooked challenges, specifically: (1) mitigating data distribution shifts between teacher and student models, (2) efficiently identifying optimal teacher configurations within time and budgetary constraints, and (3) enabling computationally efficient and rapid sharing of teacher labels to support multiple students. We present a robust KD system developed and rigorously evaluated on multiple large-scale personalized video recommendation systems within Google. Our live experiment results demonstrate significant improvements in student model performance while ensuring consistent and reliable generation of high quality teacher labels from a continuous data stream of data.
Read more8/28/2024