What are the Essential Factors in Crafting Effective Long Context Multi-Hop Instruction Datasets? Insights and Best Practices

0
Sign in to get full access
Overview
- This paper explores the essential factors in creating effective long-context multi-hop instruction datasets.
- It provides insights and best practices for developing such datasets, which are crucial for training AI models to handle complex, multi-step tasks.
- The paper covers a framework for dataset design, experiment findings, and a critical analysis of the research.
Plain English Explanation
The paper focuses on a key challenge in the field of artificial intelligence (AI) - how to create datasets that can effectively train AI models to understand and complete complex, multi-step instructions.
These types of tasks, known as "multi-hop" instructions, require the AI system to gather information from multiple sources, make connections, and then take the appropriate actions. For example, a multi-hop instruction could be "Look up the capital of the country with the largest population in South America, then find the tallest building in that city."
To train AI models to handle these types of complex tasks, researchers need high-quality datasets that provide the necessary context and structure. This paper explores the essential factors that go into crafting such datasets, offering insights and best practices.
The key ideas covered include link to Framework section:
- how to design the structure and content of the dataset
- techniques for generating diverse and challenging instructions
- methods for evaluating the quality and effectiveness of the dataset
By sharing their research and analysis, the authors aim to help other AI researchers and developers create more robust and capable AI systems that can handle the real-world complexity of multi-step instructions.
Technical Explanation
Framework
The authors propose a framework for designing effective long-context multi-hop instruction datasets. This framework includes:
- Dataset Structure: Defining the core components of each instruction, such as the initial prompt, supporting context, and required actions.
- Instruction Generation: Techniques for automatically generating diverse and challenging instructions, including using knowledge bases, templates, and crowd-sourcing.
- Dataset Evaluation: Methods for assessing the quality and difficulty of the dataset, such as measuring the number of reasoning steps required and the level of contextual information needed.
Experiment Findings
The authors conducted experiments to test different approaches to instruction dataset creation. Some key findings include:
- Combining structured knowledge bases with natural language templates was an effective way to generate a diverse set of instructions.
- Incorporating relevant contextual information, such as background details and supporting facts, was crucial for the AI models to successfully complete the multi-hop tasks.
- Evaluating the dataset's difficulty level, such as the number of reasoning steps required, helped identify the most challenging and informative examples.
Insights and Best Practices
Based on their research, the authors provide several insights and best practices for crafting effective long-context multi-hop instruction datasets:
- Focus on creating a dataset with a wide range of complexity, from simple to highly challenging instructions.
- Ensure the dataset includes sufficient contextual information to support the reasoning required for each task.
- Leverage structured knowledge sources and natural language generation techniques to efficiently create a large and diverse set of instructions.
- Incorporate rigorous evaluation methods to assess the quality and difficulty of the dataset, and use these insights to iteratively improve it.
Critical Analysis
The authors acknowledge several limitations and areas for further research in their work:
- The dataset creation and evaluation methods proposed in the paper, while comprehensive, may not capture all the nuances and complexities of real-world multi-hop instructions.
- The experiments were conducted on a limited set of knowledge domains, and the findings may not fully generalize to other areas.
- The paper does not explore the impact of different AI model architectures or training approaches on the performance in these multi-hop tasks.
Additionally, one could question whether the focus on dataset creation is overly narrow, and whether there are other important factors, such as model design or training strategies, that also play a crucial role in enabling AI systems to handle complex, multi-step instructions.
Conclusion
This paper provides valuable insights and a structured framework for creating effective long-context multi-hop instruction datasets. By sharing their research and best practices, the authors aim to help the broader AI community develop more robust and capable systems that can successfully navigate complex, real-world tasks.
The findings and recommendations in this paper have important implications for the continued advancement of AI technology, particularly in areas such as personal assistants, task planning, and knowledge-intensive applications. As AI models become more sophisticated, the ability to handle multi-step, contextual instructions will be increasingly crucial for unlocking the full potential of these systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
What are the Essential Factors in Crafting Effective Long Context Multi-Hop Instruction Datasets? Insights and Best Practices
Zhi Chen, Qiguang Chen, Libo Qin, Qipeng Guo, Haijun Lv, Yicheng Zou, Wanxiang Che, Hang Yan, Kai Chen, Dahua Lin
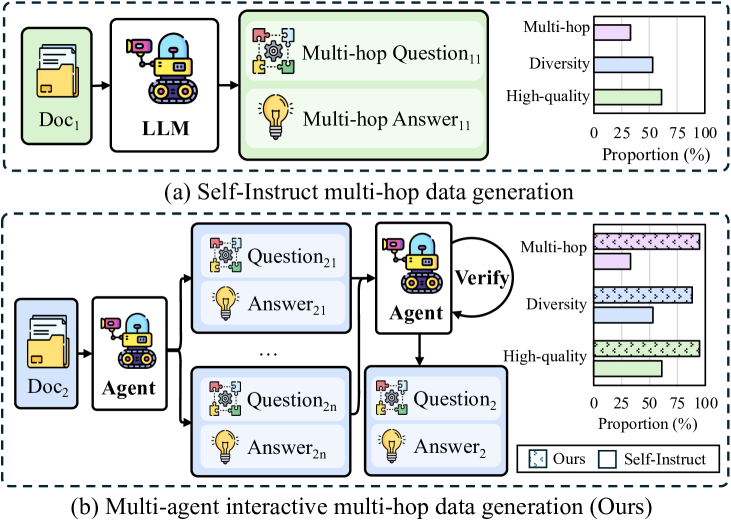
Recent advancements in large language models (LLMs) with extended context windows have significantly improved tasks such as information extraction, question answering, and complex planning scenarios. In order to achieve success in long context tasks, a large amount of work has been done to enhance the long context capabilities of the model through synthetic data. Existing methods typically utilize the Self-Instruct framework to generate instruction tuning data for better long context capability improvement. However, our preliminary experiments indicate that less than 35% of generated samples are multi-hop, and more than 40% exhibit poor quality, limiting comprehensive understanding and further research. To improve the quality of synthetic data, we propose the Multi-agent Interactive Multi-hop Generation (MIMG) framework, incorporating a Quality Verification Agent, a Single-hop Question Generation Agent, a Multiple Question Sampling Strategy, and a Multi-hop Question Merger Agent. This framework improves the data quality, with the proportion of high-quality, multi-hop, and diverse data exceeding 85%. Furthermore, we systematically investigate strategies for document selection, question merging, and validation techniques through extensive experiments across various models. Our findings show that our synthetic high-quality long-context instruction data significantly enhances model performance, even surpassing models trained on larger amounts of human-annotated data. Our code is available at: https://github.com/WowCZ/LongMIT.
Read more9/4/2024

0
Retrieval Meets Reasoning: Dynamic In-Context Editing for Long-Text Understanding
Weizhi Fei, Xueyan Niu, Guoqing Xie, Yanhua Zhang, Bo Bai, Lei Deng, Wei Han
Current Large Language Models (LLMs) face inherent limitations due to their pre-defined context lengths, which impede their capacity for multi-hop reasoning within extensive textual contexts. While existing techniques like Retrieval-Augmented Generation (RAG) have attempted to bridge this gap by sourcing external information, they fall short when direct answers are not readily available. We introduce a novel approach that re-imagines information retrieval through dynamic in-context editing, inspired by recent breakthroughs in knowledge editing. By treating lengthy contexts as malleable external knowledge, our method interactively gathers and integrates relevant information, thereby enabling LLMs to perform sophisticated reasoning steps. Experimental results demonstrate that our method effectively empowers context-limited LLMs, such as Llama2, to engage in multi-hop reasoning with improved performance, which outperforms state-of-the-art context window extrapolation methods and even compares favorably to more advanced commercial long-context models. Our interactive method not only enhances reasoning capabilities but also mitigates the associated training and computational costs, making it a pragmatic solution for enhancing LLMs' reasoning within expansive contexts.
Read more6/19/2024
🔄
0
Make Your LLM Fully Utilize the Context
Shengnan An, Zexiong Ma, Zeqi Lin, Nanning Zheng, Jian-Guang Lou
While many contemporary large language models (LLMs) can process lengthy input, they still struggle to fully utilize information within the long context, known as the lost-in-the-middle challenge. We hypothesize that it stems from insufficient explicit supervision during the long-context training, which fails to emphasize that any position in a long context can hold crucial information. Based on this intuition, our study presents information-intensive (IN2) training, a purely data-driven solution to overcome lost-in-the-middle. Specifically, IN2 training leverages a synthesized long-context question-answer dataset, where the answer requires (1) fine-grained information awareness on a short segment (~128 tokens) within a synthesized long context (4K-32K tokens), and (2) the integration and reasoning of information from two or more short segments. Through applying this information-intensive training on Mistral-7B, we present FILM-7B (FILl-in-the-Middle). To thoroughly assess the ability of FILM-7B for utilizing long contexts, we design three probing tasks that encompass various context styles (document, code, and structured-data context) and information retrieval patterns (forward, backward, and bi-directional retrieval). The probing results demonstrate that FILM-7B can robustly retrieve information from different positions in its 32K context window. Beyond these probing tasks, FILM-7B significantly improves the performance on real-world long-context tasks (e.g., 23.5->26.9 F1 score on NarrativeQA), while maintaining a comparable performance on short-context tasks (e.g., 59.3->59.2 accuracy on MMLU). Github Link: https://github.com/microsoft/FILM.
Read more4/29/2024

0
MoreHopQA: More Than Multi-hop Reasoning
Julian Schnitzler, Xanh Ho, Jiahao Huang, Florian Boudin, Saku Sugawara, Akiko Aizawa
Most existing multi-hop datasets are extractive answer datasets, where the answers to the questions can be extracted directly from the provided context. This often leads models to use heuristics or shortcuts instead of performing true multi-hop reasoning. In this paper, we propose a new multi-hop dataset, MoreHopQA, which shifts from extractive to generative answers. Our dataset is created by utilizing three existing multi-hop datasets: HotpotQA, 2WikiMultihopQA, and MuSiQue. Instead of relying solely on factual reasoning, we enhance the existing multi-hop questions by adding another layer of questioning that involves one, two, or all three of the following types of reasoning: commonsense, arithmetic, and symbolic. Our dataset is created through a semi-automated process, resulting in a dataset with 1,118 samples that have undergone human verification. We then use our dataset to evaluate five different large language models: Mistral 7B, Gemma 7B, Llama 3 (8B and 70B), and GPT-4. We also design various cases to analyze the reasoning steps in the question-answering process. Our results show that models perform well on initial multi-hop questions but struggle with our extended questions, indicating that our dataset is more challenging than previous ones. Our analysis of question decomposition reveals that although models can correctly answer questions, only a portion - 38.7% for GPT-4 and 33.4% for Llama3-70B - achieve perfect reasoning, where all corresponding sub-questions are answered correctly. Evaluation code and data are available at https://github.com/Alab-NII/morehopqa
Read more6/21/2024